| 一文看懂图像生成模型(一) | 您所在的位置:网站首页 › vae生成模型和判别 › 一文看懂图像生成模型(一) |
一文看懂图像生成模型(一)
|
AIGC这一年可太火了,stable diffusion 这个文生图的模型无疑是目前最popular的模型。由于这个模型的客户很多,我们最近也在做这个模型的相关优化,正好借机整理了相关的论文,下面是一个非深度学习炼丹玩家的学习记录。 BackGround生成模型的基本逻辑无论是图像生成,还是语音合成,都有一个信息补全的问题,因为图像和语音的信息密度是远大于文字的,比如文字是一只在奔跑的狗,那图像中狗奔跑的姿势,背景,都是文字没有给出的,所以生成模型往往要做一定的补全,而不同的补全会生成不同的图像。 那这个补全在模型里是啥呢?在目前流行的生成模型里,这个补全就是一个来自normal distribution的sample。 从模型的设计来说,一般是两个输入,一个是normal distribution的sample,这个输入是unconditional的,另外一个就是文字prompt,这个输入是conditional的,限制模型的输出结果。模型要学习的便是将文字和sample对应到特定的图像。 你可能会问,为什么是normal distribution,不是其他的distribution,这个有讨论过,结论就是其他distribution没有比normal distribution更好,所以大多数都用了normal distribution。  李宏毅老师讲解生成模型的PPT 李宏毅老师讲解生成模型的PPT Sample + Prompt ---; Image Sample + Prompt ---; Image这还涉及到另外一个问题,目标函数,一段文字可以对应很多张图片,那么怎么评价生成的图像是不是符合这段文字描述的,这个会在后面的章节细讲。 常用生成模型生成模型的策略主要是两种,一个是non-autoregressive(各个击破),另外一个是non-autogressive(NAR) 一次到位。 先看autogregressive,各个击破,这个很好理解,拿图片生成举例,就是图片的像素是一个一个生成的,后面一个像素的生成依赖于前面一个像素的结果。大名鼎鼎的GPT系列就是autoregressive策略的。autoregressive策略的优点是可以生成高质量的样本,但缺点是生成速度较慢,因为每个时间步都需要计算前一个时间步的输出。文字通常比较短,所以这个方法适合文字序列。 再看non-autoregressive(NAR) , 一次到位,这种就是一次并行生成所有像素,从而提高生成效率。但是这种模型的准确度通常比autoregressive要差。拿生成一只猫举例,autoregressive因为是逐像素生成,一个一个来,所以每个像素的目标是一样的,但non-autoregressive可能就不一样了,因为每个像素是各自行动,可能这个像素想生成宠物店的猫,另外的像素想生成的是街角的猫,这样每个像素的目标不一致,图片质量可能就差了。不过对于影像生成来说,由于高质量的图片像素太多了,用autoregressive会非常慢,所以在non-autoregressive上的上的尝试挺多的,比较流行的有VAE,GAN。 那有没有两种结合的呢?也有,比如把一次到位改成N次到位,虽然一次到位生成的质量不高,但是迭代N次的质量就高了,这个就是Diffusion model的思想了。 下面具体看下目前流行的几种生成模型:VAE, GAN, Diffusion VAE: variational autoencoders VAE基于AE, autoencoder, autoencoder的整体思想是图像重建,先通过一个encoder得到中间表达,然后通过decoder将中间表达重建为原始图像。VAE的不同在于,限制中间表达是normal distribution。所以整个loss函数是图像的距离,和中间表达与normal distribution的距离之和。 loss = || x - \tilde{x}||^{2} + KL[N(\mu_{x}, \sigma_{x}), N(0, I)] VAE model的encoder/decoder学习的便是上面提到的图像生成的基本逻辑:sample到图像的对应。下图中没有文字输入,实际上我们可以在decoder的输入里面加入文字,来限制生成的图像范围。  VAE: https://swarma.org/?p=37227 VAE: https://swarma.org/?p=37227Diffusion 这里把Diffusion放在VAE的后面是因为Diffusion也是VAE这样的encoder+decoder架构,但是使用了不同的思路: 前向加nosie,反向去noice, 而且是多步到位,add noice和denoice都是有多步迭代的。由于后面会详细讲这个模型,这里就简单介绍下。 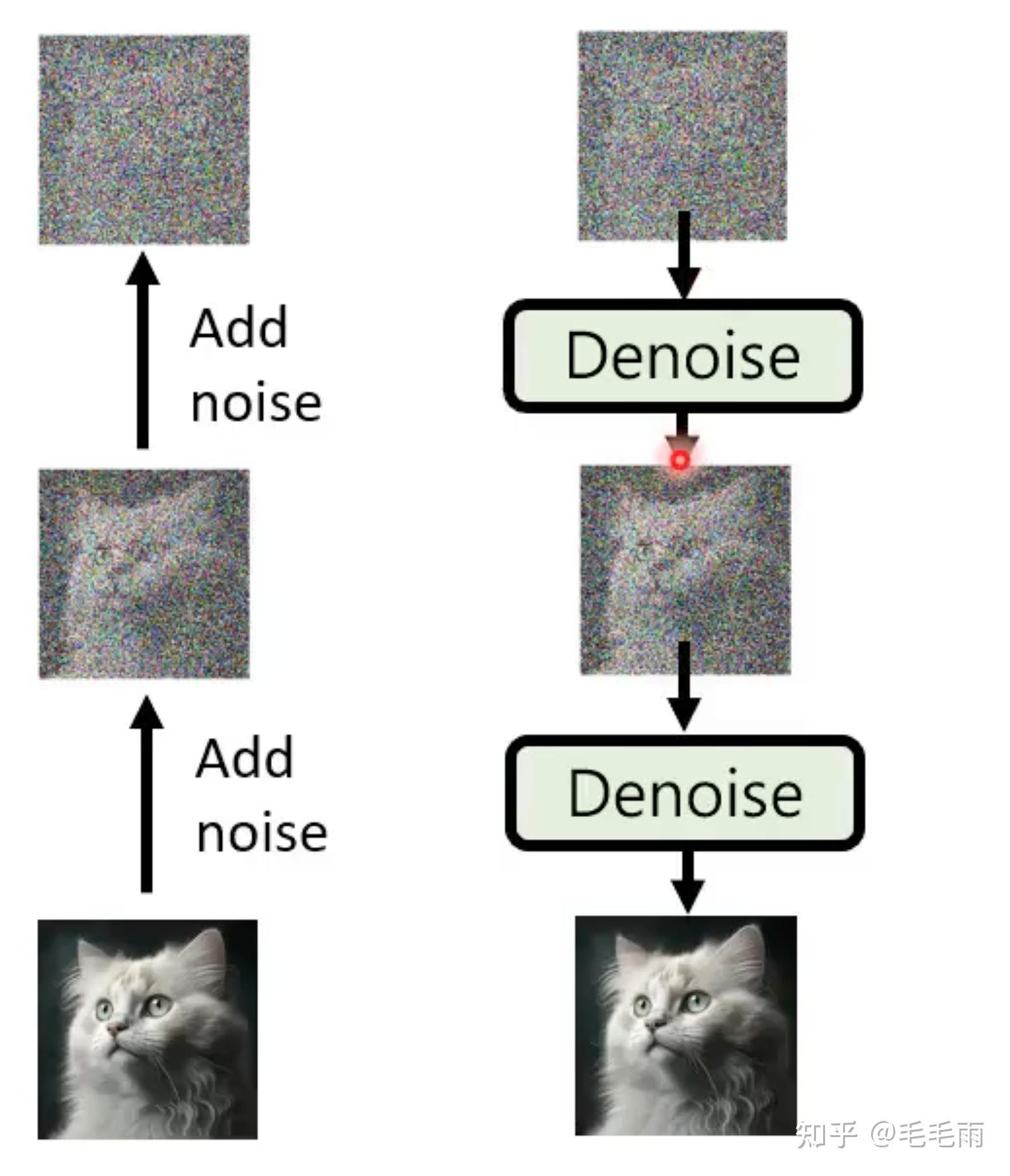 李宏毅老师讲解生成模型的PPT 李宏毅老师讲解生成模型的PPTGAN: Generative Adversarial Networks GAN模型包含了两个model,一个是生成器G: generative model,负责从latent space(也就是某个data distribution) 到image,另外一个是判别器D: discriminative model, 用来判断图片是model生成的fake image和real sample的概率 GAN的训练流程是先训练判别器D,然后训练生成器G。 先固定生成器G,训练判别器D,让判别器的准确度越来愈高。 然后固定判别器,训练生成器G, 让判别器的结果越来越接近1/2。  https://www.kdnuggets.com/2017/01/generative-adversarial-networks-hot-topic-machine-learning.html https://www.kdnuggets.com/2017/01/generative-adversarial-networks-hot-topic-machine-learning.htmlGAN的思路是和VAE/Diffusion这种完全不同的,我们完全可以在VAE/Diffusion的decoder后面再加一个判别器来提升图片质量,实际上也有人这么干,比如VAE-GAN, Diffusion-GAN。  VAE-GAN VAE-GAN Diffusion-GANDDPM Diffusion-GANDDPM 今天大部分优秀的diffusion的模型都是基于DDPM:Denoising Diffusion Probabilistic Models,所以就从DDPM开始讲起, 先看下DDPM的数学原理。 前向/反向 过程Diffusion 模型包括了两个过程,Forward process(也常叫做Diffusion process) 和 Reverse process。前向过程是逐步加noice,将图片变成一个随机噪音,反向过程是逐步denoice,将随机噪音的图片还原为完整图片。  Forward process 先来看下前向过程,这个相当于VAE的encoder,这个过程是不断的在原始图片不断加noise,直到变成一张全是噪音的图片(标准正态分布)。每一个step添加的噪音都是来自normal distribution的sample,但是这里每一个step的normal distribution并不是同一个,不同step的方差不一样,那具体方差怎么随着step变化呢?这个在代码里叫做noise/variance scheduler, 一般来说,越到后面的step,方差会设置得越大,保证后面的图片越接近纯噪音。(原因后面会再具体说明)  Reverse Process 再来看下反向过程,输入是一张全是noise的图片(normal distribution),和文字prompt, 经过多次迭代denoise,输出就是一张高质量的图片了。 那这里的Denoise部分就是我们要train的模型了,前向过程由于方差/均值是给定的,所以是没有参数的。那这个Denoise是个啥?给定一张全是noise的图片,输出一张prompt对应的图片?  No, 这个Denoise并不是去生成一张符合prompt的图片,而是predict输入图片的noise,然后将原图减去noise,来得到一张更清晰的图片。这个noise predict的任务很显然,比直接生成一张符合prompt的图片要更简单。 Diffusion的denoise过程是迭代多次的,由于每个step的输入并不一样,所以如果不同step共享同一个noise predicter模型的参数,那可能效果不是很好,但也不想train T个noise predicter,于是有了一个很聪明的想法,那就是把step信息加入模型,这样模型的输入一共是3个,全是noise的图片(也就是normal distirbution sample), 文字prompt,time-step embedding。  看到这里,我们对Diffusion模型有了初步的了解,接下来就该看看原论文了。不看不知道,一看吓一跳,看论文才发现,原来Diffusion背后的数学原因这么复杂,公式推导这么长,但是其实我并不关心那些推导的细节,只需要大概知道模型的工作原理,能看懂模型代码就行。那么,下面,简单易懂版的数学原理推导,它来了。 数学原理先从论文里的算法流程图看起。  先看training, x_{0} 是我们训练数据集的image, t 是time-step id,从1到T, \epsilon 是 noise, 取自均值为0, 方差为1的normal distribution, \theta 是网络,noise predictor。可以将 \sqrt{\bar{\alpha_{t}}}x_{0} + \sqrt{1- \bar{\alpha_{t}}}\epsilon 看成第t个step时网络的输入:noisy image, 网络的目标函数就是最小化predicted noise和target noise的距离,直到模型收敛。那为啥 \sqrt{\bar{\alpha_{t}}}x_{0} + \sqrt{1- \bar{\alpha_{t}}}\epsilon 是第t个step的noise image呢?先留下这个问题。  再来看Inference, x_{T} 是输入的纯噪音的图片,也就是一个normal distribution sample, 然后是T次denoise,每次拿到上一个step的输出 x_{t} ,预测出当前step的noise: \epsilon_{\theta}(x_{t}, t) , 用 x_{t} - weight * \epsilon_{\theta}(x_{t}, t) ,再加上一个noise得到 x_{t-1} ,等等,这里为什么加一个noise呢?再留下这个问题。  下面来回答第一个问题:那为啥 \sqrt{\bar{\alpha_{t}}}x_{0} + \sqrt{1- \bar{\alpha_{t}}}\epsilon 是第t个step的noise image? 那就要回到前向过程, 前向是在原始图片不断加noise,直到变成纯噪音(标准正态分布)为止。给定原始数据 x_{0} , 增加噪声的过程如下定义:  这里的 \beta_{t} 是每一步的方差,定义这义\alpha_t = 1 - \beta_t和\bar{\alpha}_t = \prod_{i=1}^t \alpha_i,通过重参数技巧(这里推导利用了两个方差不同的正态分布相加等于一个新的正态分布的结论。 为啥这个是重点呢?因为train要用到的ground truth正是这个任意时刻的noise图片。 DraftHow to train 关于模型的training这里再多说两句,实际上公式推导是很复杂的,我也只是理个思路。这部分主要参考了这篇博文,里面有详细的推导,感兴趣的同学可以跳转。 前向是没有参数的,不需要训练。反向生成noise,数据上就是得到当前time-step noise的均值和方差。  这里直接从 x_{t} 预测 x_{t-1} 是很难的,但是我们还有一个条件: x_{0} , 加上 x_{0} 的后验分布就可以处理了:  根据贝叶斯公式,可以转换为:  我们熟悉的东西回来了: q(x_{t}|x_{t-1}) ,这样最终可以得到后验分布 q(x_{t}|x_{t-1}, x_{0}) 的均值和方差:可以看到均值是定量,方差是一个关于 x_{0}, x_{t} 的函数,这个就是我们的noise predictor的优化目标了。  这一篇写到这里,下一篇会具体看下DDPM和stable diffusion的代码以及性能优化的思路。 为什么diffusion这么成功: 视频1:40:00 |
【本文地址】