| 【NLP】第 4 章:文本预处理、词干提取和词形还原 | 您所在的位置:网站首页 › 还原释义 › 【NLP】第 4 章:文本预处理、词干提取和词形还原 |
【NLP】第 4 章:文本预处理、词干提取和词形还原
|
🔎大家好,我是Sonhhxg_柒,希望你看完之后,能对你有所帮助,不足请指正!共同学习交流🔎 📝个人主页-Sonhhxg_柒的博客_CSDN博客 📃 🎁欢迎各位→点赞👍 + 收藏⭐️ + 留言📝 📣系列专栏 - 机器学习【ML】 自然语言处理【NLP】 深度学习【DL】
✔说明⇢本人讲解主要包括Python、机器学习(ML)、深度学习(DL)、自然语言处理(NLP)等内容。 如果你对这个系列感兴趣的话,可以关注订阅哟👋 目录 技术要求 文本预处理 删除 HTML 将文本转换为小写 删除标点符号 替换数字 词干和词形还原 词干 词形还原 词干和词形还原的使用 词形还原和词干化的差异 概括 文本数据可以从许多不同的来源收集并采用许多不同的形式。文本可以是整洁易读的,也可以是原始的和凌乱的,也可以有许多不同的风格和格式。能够对这些数据进行预处理,以便在它到达我们的 NLP 模型之前将其转换为标准格式,这就是我们将在本章中看到的内容。 类似于标记化的词干提取和词形还原是 NLP 预处理的其他形式。然而,与将文档简化为单个单词的标记化不同,词干提取和词形还原是尝试将这些单词进一步简化为词根。例如,几乎所有英语动词都有许多不同的变体,具体取决于时态: He jumped He is jumping He jumps 虽然所有这些词都不同,但它们都与同一个词根——jump相关。词干提取和词形还原都是我们可以用来将单词变体减少到它们共同词根的技术。 在本章中,我们将解释如何对文本数据进行预处理,探索词干提取和词形还原,并展示如何在 Python 中实现这些。 在本章中,我们将介绍以下主题: 文本预处理词干词形还原词干和词形还原的使用 技术要求对于本章中的文本预处理,我们将主要使用内置的 Python 函数,但我们也会使用外部的BeautifulSoup包。对于词干提取和词形还原,我们将使用 NLTK Python 包。 文本预处理文本数据可以有多种格式和样式。文本可以是结构化的、可读的格式或更原始的、非结构化的格式。我们的文本可能包含我们不希望包含在模型中的标点和符号,或者可能包含 HTML 和其他非文本格式。从在线资源中抓取文本时,这一点尤其值得关注。为了准备我们的文本以便可以将其输入到任何 NLP 模型中,我们必须执行预处理。这将清理我们的数据,使其成为标准格式。在本节中,我们将更详细地说明其中一些预处理步骤。 删除 HTML从在线资源中抓取文本时,您可能会发现您的文本包含 HTML 标记和其他非文本工件。我们通常不希望将这些包含在模型的 NLP 输入中,因此默认情况下应将其删除。例如,在 HTML 中,标记指示其后面的文本应为粗体。但是,这不包含有关句子内容的任何文本信息,因此我们应该删除它。幸运的是,在 Python 中,有一个名为BeautifulSoup的包,它允许我们在几行中删除所有 HTML: input_text = " This text is in bold, This text is in italics " output_text = BeautifulSoup(input_text, "html.parser").get_text() print('Input: ' + input_text) print('Output: ' + output_text)这将返回以下输出:
图 4.1 – 删除 HTML 前面的屏幕截图显示 HTML 已成功删除。这在 HTML 代码可能存在于原始文本数据中的任何情况下都很有用,例如在抓取网页以获取数据时. 将文本转换为小写预处理文本以将所有内容转换为小写字母是标准做法。这是因为任何两个相同的词都应该被认为在语义上是相同的,无论它们是否大写。' Cat '、' cat ' 和 ' CAT ' 都是相同的词,只是大小写不同。我们的模型通常会将这三个词视为独立的实体,因为它们并不相同。因此,标准做法是将所有单词转换为小写,以便这些单词在语义和结构上都相同。这可以在 Python 中使用以下代码行轻松完成: input_text = ['Cat','cat','CAT'] output_text = [x.lower() for x in input_text] print('Input: ' + str(input_text)) print('Output: ' + str(output_text))这将返回以下输出:
图 4.2 – 将输入转换为小写 这表明输入已全部转换为相同的小写表示。在一些例子中,大写实际上可以提供额外的语义信息。例如,May(月份)和may(意味着可能)在语义上是不同的,May(月份)总是大写。然而,像这样的例子非常罕见,将所有内容都转换为小写比试图解释这些罕见的例子更有效。 值得的注意到大写在某些任务中可能很有用,例如词性标注,其中大写字母可能表示单词在句子中的角色,以及命名实体识别,其中大写字母可能表示单词是专有名词而不是非专有名词替代;例如,土耳其(国家)和火鸡(鸟). 删除标点符号有时,根据所构建模型的类型,我们可能希望删除标点符号从我们的输入文本。这在我们汇总字数的模型中特别有用,例如在词袋表示中。句子中出现句号或逗号不会添加有关句子语义内容的任何有用信息。然而,考虑到句子中标点符号位置的更复杂的模型实际上可能会使用标点符号的位置来推断不同的含义。一个经典的例子如下: The panda eats shoots and leaves The panda eats, shoots, and leaves 在这里,逗号的添加将描述熊猫饮食习惯的句子变成了描述熊猫武装抢劫餐馆的句子!尽管如此,为了保持一致性,能够从句子中删除标点符号仍然很重要。我们可以在 Python 中使用re库来做到这一点,使用正则表达式匹配任何标点符号,以及sub()方法,用空字符替换任何匹配的标点符号: input_text = "This ,sentence.'' contains-£ no:: punctuation?" output_text = re.sub(r'[^\w\s]', '', input_text) print('Input: ' + input_text) print('Output: ' + output_text)这将返回以下输出: 图 4.3 – 从输入中删除标点符号 这表明标点符号已从输入句子中删除。 在某些情况下,我们可能不希望直接删除标点符号。一个很好的例子是是与符号 ( & ) 的使用,它几乎在所有情况下都可以与单词 "和" 互换使用。因此,我们可以选择直接用单词“和”代替它,而不是完全删除&符号。我们可以使用.replace()函数在 Python 中轻松实现: input_text = "Cats & dogs" output_text = input_text.replace("&", "and") print('Input: ' + input_text) print('Output: ' + output_text)这将返回以下输出:
图 4.4 – 删除和替换标点符号 还值得考虑标点符号可能必不可少的特定情况句子的表示。一个重要的例子是电子邮件地址。从电子邮件地址中删除@不会使地址更具可读性: 删除标点符号会返回: namegmailcom 因此,在这种情况下,根据您的 NLP mod 的要求和目的,最好完全删除整个项目这。 替换数字同样,对于数字,我们也希望标准化我们的输出。数字可以写成数字(9、8、7)或实际单词(9、8、7)。可能值得改造这些都成为一个单一的标准化表示,因此 1 和 1 不会被视为单独的实体。我们可以使用以下方法在 Python 中执行此操作: def to_digit(digit): i = inflect.engine() if digit.isdigit(): output = i.number_to_words(digit) else: output = digit return output input_text = ["1","two","3"] output_text = [to_digit(x) for x in input_text] print('Input: ' + str(input_text)) print('Output: ' + str(output_text))这将返回以下输出:
图 4.5 – 用文本替换数字 这表明我们已经成功地将我们的数字转换为文本。 然而,在一个与处理电子邮件地址类似,处理电话号码可能不需要与常规号码相同的表示。这在以下示例中进行了说明: input_text = ["0800118118"] output_text = [to_digit(x) for x in input_text] print('Input: ' + str(input_text)) print('Output: ' + str(output_text))这将返回以下输出:
图 4.6 – 将电话号码转换为文本 显然,输入在前面的示例中是电话号码,因此全文表示不一定适合目的。在这种情况下,最好从我们的输入 t 中删除任何长数字分机 词干和词形还原在语言中,屈折变化是如何通过修饰一个共同的词根来表达不同的语法类别,如时态、情绪或性别。这通常涉及更改单词的前缀或后缀,但也可能涉及修改整个词。例如,我们可以修改一个动词来改变它的时态: Run -> Runs(添加“s”后缀使其成为现在时) Run -> Ran(将中间字母修改为“a”以使其成为过去式) 但在某些情况下,整个词都会发生变化: To be -> Is(现在时) To be -> Was(过去时) To be -> Will be (未来时态 - 添加模态) 名词也可以有词汇变化: Cat -> Cats(复数) Cat -> Cat's (占有) Cat -> Cats'(复数所有格) 所有这些词都与词根 cat 相关。我们可以计算句子中所有单词的词根,以将整个句子简化为其词根: "His cats' fur are different colors" -> "He cat fur be different color" 词干提取和词形还原是我们得出这些词根的过程。词干提取是一个算法过程,其中词的末端被切断以达到一个共同的词根,而词形还原使用词本身的真实词汇和结构分析来得出词的真正词根或引理。我们将在接下来的章节中详细介绍这两种方法选项。 词干词干是算法过程,我们通过它修剪单词的结尾,以达到它们的词根或词干。为此,我们可以使用不同的词干分析器,每个词干分析器都遵循特定的算法以返回单词的词干。在英语中,最常见的词干分析器之一是 Porter Stemmer。 Porter Stemmer是一个具有大量逻辑规则的算法,可用于返回词干。我们将首先展示如何使用 NLTK 在 Python 中实现 Porter Stemmer,然后继续详细讨论该算法: 首先,我们创建一个 Porter Stemmer 的实例: porter = PorterStemmer() 然后,我们只需在单个单词上调用这个词干分析器实例并打印结果。在这里,我们可以看到 Porter Stemmer 返回的词干示例: word_list = ["see","saw","cat", "cats", "stem", "stemming","lemma","lemmatization","known","knowing","time", "timing","football", "footballers"] for word in word_list: print(word + ' -> ' + porter.stem(word))这将产生以下输出:
图 4.7 – 返回词干 我们还可以将词干应用于整个句子,首先对句子进行标记,然后分别对每个词进行词干: def SentenceStemmer(sentence): tokens=word_tokenize(sentence) stems=[porter.stem(word) for word in tokens] return " ".join(stems) SentenceStemmer('The cats and dogs are running')这将返回以下输出:
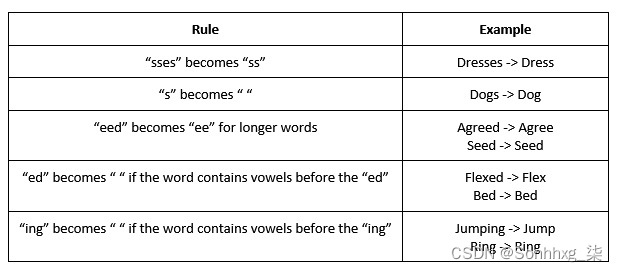
图 4.8 – 将词干应用于句子 在这里,我们可以看到如何使用 Porter Stemmer 对不同的词进行词干提取。有些词,例如stemming和timing,会简化为他们预期的stem和time词干。但是,有些词,例如saw,并不能简化为它们的逻辑词干(参见)。这说明了 Porter Stemmer 的局限性。由于词干提取对单词应用了一系列逻辑规则,因此很难定义一组正确词干词干的规则。在英语单词的情况下尤其如此,其中单词根据时态(is/was/be)完全改变。这是因为没有通用规则可以应用于这些单词以将它们全部转换为相同的词根。 我们可以检查Porter Stemmer 更详细地应用了一些规则,以准确了解如何转化为词干。虽然实际的 Porter 算法有很多详细的步骤,但在这里,为了便于理解,我们将简化一些规则: 图 4.9 – Porter Stemmer 算法的规则 虽然了解 Porter Stemmer 中的每条规则并不是必需的,但我们了解其局限性是关键。虽然 Porter Stemmer 已被证明在整个语料库中运行良好,但总会有一些词无法正确还原为真正的词干。由于 Porter Stemmer 的规则集依赖于英语单词结构的约定,因此总会有一些单词不属于常规单词结构,并且没有被这些规则正确转换。幸运的是,其中一些限制可以通过使用 lemmati 来克服化。 词形还原词形还原与词干不同之处在于它将单词简化为词根而不是词干。当一个词的词干被处理并简化为一个字符串时,一个词的引理是它的真正的词根。因此,虽然ran这个词的词干只是ran,但它的引理是这个词的真正词根,应该是run。 词元化过程使用内置的预先计算的词条和相关词,以及句子中词的上下文来确定给定词的正确词条。在这个例如,我们将研究在NLTK中使用WordNet Lemmatizer 。WordNet 是一个包含英语单词及其词汇关系的大型数据库。它包含最强大和最全面的英语映射之一,特别是关于单词与其引理的关系。 我们将首先创建 lemmatizer 的一个实例,并在选择的单词上调用它: wordnet_lemmatizer = WordNetLemmatizer() print(wordnet_lemmatizer.lemmatize('horses')) print(wordnet_lemmatizer.lemmatize('wolves')) print(wordnet_lemmatizer.lemmatize('mice')) print(wordnet_lemmatizer.lemmatize('cacti'))这将产生以下输出:
图 4.10 – 词形还原输出 在这里,我们已经可以开始看到使用词形还原相对于词干提取的优势。由于 WordNet Lemmatizer建立在包含所有英语单词的数据库上,因此它知道mouse 是mouse的复数形式。使用词干提取我们将无法达到相同的根源。尽管词形还原在大多数情况下效果更好,因为它依赖于内置的词索引,它不能推广到新词或虚构词: print(wordnet_lemmatizer.lemmatize('madeupwords')) print(porter.stem('madeupwords'))这将产生以下输出:
图 4.11 – 虚构词的词形还原输出 在这里,我们可以看到,在这种情况下,我们的词干分析器能够更好地泛化到以前看不见的单词。因此,如果我们要进行词形还原,使用词形还原器可能是个问题语言不一定与真正的英语相匹配的来源,例如人们可能经常缩写语言的社交媒体网站。 如果我们在两个动词上调用 lemmatizer,我们会看到这并没有将它们简化为预期的共同引理: print(wordnet_lemmatizer.lemmatize('run')) print(wordnet_lemmatizer.lemmatize('ran'))这将产生以下输出:
图 4.12 – 对动词进行词形还原 这是因为我们的 lemmatizer 依赖于单词的上下文来返回 lemmas。回想一下我们的 POS 分析,我们可以轻松地返回句子中单词的上下文,并确定给定单词是名词、动词还是形容词。现在,让我们手动指定我们的单词是动词。我们可以看到这现在正确地返回了引理: print(wordnet_lemmatizer.lemmatize('ran', pos='v')) print(wordnet_lemmatizer.lemmatize('run', pos='v'))这将产生以下输出:
图 4.13 – 在函数中实现 POS 这表示为了返回任何给定句子的正确词形还原,我们必须首先执行 POS 标记以获取句子中单词的上下文,然后将其传递给 lemmatizer 以获得句子中每个单词的词元。我们首先创建一个函数,该函数将返回句子中每个单词的 POS 标记: sentence = 'The cats and dogs are running' def return_word_pos_tuples(sentence): return nltk.pos_tag(nltk.word_tokenize(sentence)) return_word_pos_tuples(sentence)这将产生以下输出:
图 4.14 – 词性标注的句子输出 请注意这如何返回句子中每个单词的 NLTK POS 标签。我们的 WordNet lemmatizer 需要稍微不同的 POS 输入。这意味着我们首先创建将 NLTK POS 标签映射到所需的 WordNet POS 标签的函数: def get_pos_wordnet(pos_tag): pos_dict = {"N": wordnet.NOUN, "V": wordnet.VERB, "J": wordnet.ADJ, "R": wordnet.ADV} return pos_dict.get(pos_tag[0].upper(), wordnet.NOUN) get_pos_wordnet('VBG')这将产生以下输出:
图 4.15 – 将 NTLK POS 标签映射到 WordNet POS 标签 最后,我们将这些函数组合成一个最终函数,该函数将对整个句子进行词形还原: def lemmatize_with_pos(sentence): new_sentence = [] tuples = return_word_pos_tuples(sentence) for tup in tuples: pos = get_pos_wordnet(tup[1]) lemma = wordnet_lemmatizer.lemmatize(tup[0], pos=pos) new_sentence.append(lemma) return new_sentence lemmatize_with_pos(sentence)这将产生以下输出: 图 4.16 – 最终的词形还原函数的输出 在这里,我们可以看到,一般来说,与词干相比,词根通常可以更好地表示单词的真正词根,但有一些明显的例外。当我们可能决定使用词干提取和词形还原取决于手头任务的要求,其中一些我们将探讨现在重新。 词干和词形还原的使用词干和词形还原都是 NLP 的一种形式,可用于从文本中提取信息。这个被称为文本挖掘。文本挖掘任务来了在各种类别中,包括文本聚类、分类、总结文档和情感分析。词干提取和词形还原可以与深度学习结合使用来解决其中的一些任务,我们将在本书后面看到。 通过使用词干提取和词形还原进行预处理,再加上停用词的去除,我们可以更好地减少句子以理解它们的核心含义。通过删除对句子含义没有显着贡献的单词通过将单词简化为词根或引理,我们可以在深度学习框架内有效地分析句子。如果我们是能够将 10 个单词的句子减少到由多个核心引理组成的五个单词,而不是相似单词的多个变体,这意味着我们需要通过神经网络提供的数据要少得多。如果我们使用词袋表示,我们的语料库将明显更小,因为多个单词都减少到相同的词条,而如果我们计算嵌入表示,则捕获我们单词的真实表示所需的维数会更小减少语料库。 词形还原和词干化的差异既然我们已经看到了词形还原和词干化的作用,那么问题仍然存在在什么情况下我们应该同时使用这两种技术。我们看到这两种技术都试图将每个单词简化为词根。在词干分析中,这可能只是目标房间的简化形式,而在词形还原中,它简化为真正的英语词根。 因为词形还原需要在 WordNet 语料库中交叉引用目标词,以及执行词性分析以确定词条的形式,所以如果需要大量的词,这可能需要大量的处理时间。词形化。这与词干提取形成对比,词干提取使用详细但相对快速的算法来词干词。最终,与计算中的许多问题一样,这是一个权衡速度与细节的问题。在选择将这些方法中的哪一种纳入我们的深度学习管道时,可能需要在速度和准确性之间进行权衡。如果时间至关重要,那么词干化可能是要走的路。另一方面,如果您需要模型尽可能详细和准确,则词形还原可能会产生更好的模型。 概括在本章中,我们通过探索这两种方法的功能、它们的用例以及如何实现它们,详细介绍了词干提取和词形还原。现在我们已经涵盖了深度学习和 NLP 预处理的所有基础知识,我们已经准备好从头开始训练我们自己的深度学习模型了。 在下一章中,我们将探索 NLP 的基础知识,并展示如何构建深度 NLP 领域中使用最广泛的模型:循环神经网络。 |





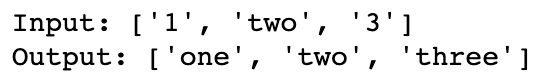
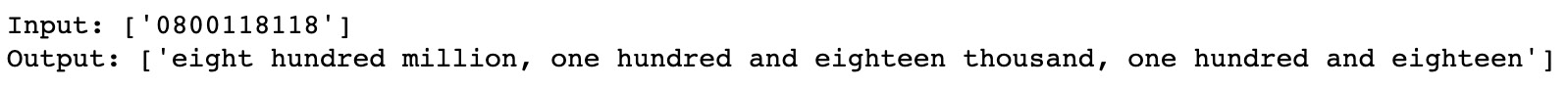

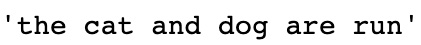





【本文地址】