| 课程实录|PPO × Family 第二课:解构复杂动作空间(上) | 您所在的位置:网站首页 › 旋翼无人机原理图 › 课程实录|PPO × Family 第二课:解构复杂动作空间(上) |
课程实录|PPO × Family 第二课:解构复杂动作空间(上)
|
本节课将进入 PPO × Family 系列课程的第一个专题:解构复杂动作空间。 如果想将各种各样的深度强化学习算法应用在实际问题中,那么第一步就是需要将原始的自然决策问题转化为标准的马尔科夫决策过程(MDP),具体来说就是需要去定义清楚 MDP 五元组的各个元素,比如状态,动作,奖励等等。而本节课将会从动作空间入手,首先,概述性地讲解动作空间的特点,然后,会选取四种主流的决策动作空间(离散、连续、多维离散、混合)一一展开,最终希望能够使用一个 PPO 算法去解决上述四种动作空间,从“算法-代码-应用”三合一的角度来探索各类决策输出的最佳方案,做到真正意义上的决策万能钥匙。  (图1:四类经典的决策动作空间)2.1 动作空间概述 (图1:四类经典的决策动作空间)2.1 动作空间概述 图2:一个经典的动作空间例子——键盘动作空间。键盘上的每个按键的按下和松开就代表相应功能的执行还是不执行,一个键就是一个2维的离散动作,整个键盘就是一个巨大的离散动作集合。 图2:一个经典的动作空间例子——键盘动作空间。键盘上的每个按键的按下和松开就代表相应功能的执行还是不执行,一个键就是一个2维的离散动作,整个键盘就是一个巨大的离散动作集合。动作是智能体(Agent)与环境交互时做出的决策行为,即决策算法的输出,动作空间 (Action Space) 是指所有可能动作的集合,是马尔科夫决策过程的五元组元素之一。将原始决策问题的输出端抽象为合适的动作空间,并配合使用相应的决策算法,是通向高效强大决策智能体的必经之路。 动作空间的分类 图3:动作空间分类概览和样例图 图3:动作空间分类概览和样例图离散和连续动作是最经典最基本的两类动作空间,在此基础上,又可以推广到更复杂的多维离散动作空间和混合动作空间。在经典的强化学习学术环境中,如图3所示,离散动作空间的例子包括 Super Mario Bros 和 Procgen 环境,相应的,连续动作空间一般则会和机器人更相关,例如图中所示的 DeepMind Control 和 PyBullet 环境,而多维离散(multi-discrete)和混合(hybrid)动作空间,则更多对应生活实际中的一些决策应用。总结来看,动作空间可以总结出如下几条特点: 不同的动作空间常需要不同的算法:例如处理离散动作空间常用一些 value-based 方法(DQN)和策略梯度方法(PPO),而连续动作空间则会涉及更多策略梯度方法的变体,例如 PPO、DDPG、SAC。这些算法在设计之初就会为对应的动作空间做一些特殊的设计,进而使得它们在这些场景上会有一定的优势。标准的 RL 算法常需要对特定动作进行适配和定制化:比如想将标准的 PPO 算法应用到上述四种动作空间上,那么就需要针对具体的动作空间添加一些算法设计和技巧,这也是 PPO × Family 课程设计的重要动机之一。同一个环境可以用不同的动作空间:基于对决策问题(环境)的领域知识,基于对强化学习算法的使用经验,可以对原有环境的动作空间做一些改造,让改造后的动作空间更适合于算法训练和部署。动作塑形(Action Shaping)上文中提到的动作空间改造,又被称为动作塑形(Action Shaping),即对原始的动作空间进行各种预处理和特征工程操作,转化为更适合 RL 的空间,下表就总结了实践中[1] 常用的一些动作塑形操作和变换前后动作空间的类型,其中标明的三种最常用的变换分别为: DC:连续动作空间离散化RA:去除部分冗余或无意义的动作CMD:将多维离散动作空间转换为离散动作空间 图4:一些经典的大型决策环境中 Action Shaping 操作一览 图4:一些经典的大型决策环境中 Action Shaping 操作一览基于上述 Action Shaping 方法的结果,本节课将会关注跟算法设计联系更加紧密的部分,结合 PPO × Family 在不同动作空间上的算法理论设计、代码实现、衍生应用三方面的相关知识,详细讲述 PPO 如何解构各类动作空间。 2.2 离散动作空间 图5:离散动作空间和连续动作空间的对比示意图引言:离散动作空间的定义 图5:离散动作空间和连续动作空间的对比示意图引言:离散动作空间的定义离散动作空间是最经典、最常规的动作空间,一般是相对连续动作而言的概念,具体由有限数量的动作组成,包含特定任务中所有可用的离散控制指令,可以类比机器学习中的分类任务。这里我们举一些离散动作空间的实际例子: 石头剪刀布游戏,可选择的动作有三种。红白机游戏,可选择的动作为游戏手柄上的按键(上下左右BA)。理论:PPO 如何建模离散动作空间策略定义如果智能体正在玩超级马里奥游戏,那么将当前游戏这一帧的画面(下图所示)记为图片观察状态 s 。而智能体在观测到状态 s 后,可选择的动作集合则记为 a \in \{{left, right, up} \} ,即一个标准的3维离散动作空间,每次决策需要从这三个离散动作中选择一个。  图6:马里奥游戏中的状态和动作定义示例 图6:马里奥游戏中的状态和动作定义示例基于上述的状态和动作定义,智能体往往需要从数据中学习到策略 \pi ,即向策略 \pi 输入状态,它将输出所选动作,或是选择每个动作的概率,对于 PPO 来说,具体是学习一种随机性策略,即给定一个某时刻 t 马里奥的游戏画面,即图片观察状态 s_t ,PPO 智能体策略输出选择各个离散动作的概率分布 \pi(a_t|s_t) ,一个具体的实例为: \pi(left|s) =0.2 表示选择向左动作的概率是0.2\pi(right|s)=0.1 表示选择向右动作的概率是0.1\pi(up|s)=0.7 表示选择向上动作的概率是0.7计算图和动作采样PPO 是一种深度强化学习算法,由于策略要建模的“状态-动作”之间的映射在实际问题中可能比较复杂,所以结合神经网络来实现参数策略函数 \pi(a|s) ,对于这个策略神经网络,输入状态 s ,网络就输出每一维离散动作 a_i 对应的 logit 值,比如上文所示的马里奥游戏就是最终输出3个 logit 值,完整的输入输出数据流可以参考下图:  图7:使用 PPO 算法处理马里奥游戏,详细的输入输出数据流 图7:使用 PPO 算法处理马里奥游戏,详细的输入输出数据流logit 的含义是神经网络 \pi(a|s;\theta) 的原始输出(比如最后一层全连接层的输出,不加激活函数,取实数范围),离散动作空间有 k 个动作,则策略网络输出 k 个动作相应的 logit 值。这些 logit 值经过 softmax 函数即可得到当前策略 \pi(a|s;\theta) 选择每个离散动作的概率。 关于 logit 的进一步理解可以参考知乎博客:如何理解深度学习源码里经常出现的logit [2]在获得智能体策略选择各个离散动作的概率之后,一般常有两种采样动作的方式: 确定性决策(determinstic decision):直接贪心选择 [3] 概率最大的那一维动作 (一般实现中直接选择 logit 最大的,因为 softmax 函数并不改变 logit 的相对大小,即 \mathop{\mathrm{argmax}}\limits_{a\in \mathcal{A}}{\pi(a|s;\theta )} )。随机性决策(stochastic decision):根据之前将 \pi(a|s) 的输出经过 softmax 函数后获得的概率值,构造相应概率分布(离散动作空间即对应玻尔兹曼分布 [4]) 进行抽样得到动作。随机性决策一般用于 PPO 智能体收集数据的过程,由于强化学习是一个在线训练的过程,所以训练中需要保持足够的探索程度(即概率低的动作也有被采样到的可能性),同时也更多地利用概率高的动作。此外,为了更精细地控制这一点,部分任务中还会在 softmax 处设置专门的温度系数来控制概率分布的平滑程度。另一方面, PPO 智能体训练过程中也会定期进行评测,分析当前智能体的性能。这时则会根据情况选择使用确定性决策还是随机性决策。一般来说,对于环境简单,干扰噪声因素较少的环境(例如超级马里奥),确定性决策往往能直接给出优秀的解。而另外一些过于复杂,环境中随机性较大,最优策略不唯一的环境(例如星际争霸2,局部视野的迷宫),使用随机性决策则可以获得比较高的期望收益。在确定了智能体策略的计算图和采样动作的方式之后,我们就可以让智能体和环境不断交互,产生一系列轨迹数据用于训练,整个交互流程如下图所示:  图8:智能体与环境交互产生轨迹数据的流程示意图代码:PPO 中如何实现采样动作(torch.distribution) 图8:智能体与环境交互产生轨迹数据的流程示意图代码:PPO 中如何实现采样动作(torch.distribution)PPO 在离散动作空间上的算法理论其实很简单,大部分的算法设计很容易实现,具体可以参考课程第二章的相关代码。但其中关于随机性决策采样动作的部分,仍存在一些特殊的地方。关于如何在深度学习中构建和使用概率分布,TensorFlow 的作者们在2017年提出了关于这部分的标准设计 [5]。本课程中我们结合 PyTorch 中具有相似功能与设计的概率分布模块 torch.distribution [6] 来进行讲解。 torch.distribution 实现了各种概率分布,以及相关用于抽样和计算统计数据的方法。如对于离散动作空间,我们使用 torch.distribution.Categorical 来构建策略神经网络输出的离散动作概率分布,决策时直接使用它的函数sample()即可返回抽样结果。 而要深入了解torch.distribution的工作原理,就要理解三种类型的shape,即 Sample shape、Batch shape 和 Event shape,它们对于理解 torch.distribution 至关重要。 Sample shape 为针对单个分布的采样次数,在使用sample(sample_shape)时指定,即从这个分布中独立同分布地采样多个值。Batch shape 为用于采样的(不同)分布的个数,例如对于一批(batch)样本,采样每个样本对应的动作。Event shape 为单个分布本身的维度,具体使用时跟概率分布的语义强相关,例如后续更复杂的动作空间,可能需要考虑多重动作之间的关系。一个更具体的演示图如下所示 [7]:  图9:三种类型的shape 分布、抽样、维度形式、原理解释的对比图 图9:三种类型的shape 分布、抽样、维度形式、原理解释的对比图完整的“算法-代码”一一对比详细讲解,读者可以参考 PPO × Family 课程的注解文档,一个示意图如下:  图10:PPO × Family 课程“算法-代码”注解文档示意图——离散动作空间示例实践:使用 PPO 来解决火箭回收中的离散控制 图10:PPO × Family 课程“算法-代码”注解文档示意图——离散动作空间示例实践:使用 PPO 来解决火箭回收中的离散控制在明确 PPO + 离散动作空间的算法理论和代码实现细节后,我们尝试来应用相关知识解决相应的实际问题,这里选择简化后的火箭回收任务中的离散控制问题。本章节将会介绍环境的各种细节定义以及使用 PPO 的实践经验。问题背景2021年3月4日,美国得克萨斯州 Boca Chica 测试基地,SpaceX 的星舰飞船原型 SN10 再次表演了一场空中杂技,实现了星舰高空试飞的首次平稳落地,下图是 SN10 发射和着陆的实际情况 [8]:  图11:SN10升空和落地过程的叠加合成图[8] 图11:SN10升空和落地过程的叠加合成图[8]本课程修改并简化了开源代码环境 Rocket-recycling [9] 中模拟 SN10 的回收落地任务,并将其作为 PPO 做离散控制的示例之一,可以在1-2小时内训练收敛。具体来说,这个任务就是要控制火箭从水平的初始状态,不断调整发动机的推力从而控制姿态,最终成功竖直平稳落地。实际的环境实现是一个简化模型,考虑了基本的气缸动力学模型,并假设空气阻力与速度成正比。火箭底部安装了推动力为矢量的发动机,强化学习的目标也就是控制这些发动机的相关参数。具体原理图如下所示,将原始连续的推力控制离散化为三个角度 × 三种推力的九维离散动作空间:  图12:SN10 火箭仿真结构原理图和动作离散化图环境 MDP 设定 图12:SN10 火箭仿真结构原理图和动作离散化图环境 MDP 设定Rocket-recycling 仿真环境的 MDP 基础元素定义如下: 初始条件• 初始速度设置为 -50m/s。• 火箭方向设置为 90°(水平)。• 着陆燃烧高度设置为离地 500m。• 水平方向初始位置随机动作空间• 推力:推力可调值为 0.2g、 1.0g和 2.0g• 喷嘴角速度: 可调节为 0、 20°/s和 -20°/s• 注意也就是只有 9 个组合,动作空间 shape 为 (9,)观察空间• 位置 (x, y) :即火箭在画布中的位置,范围分别为 (-300, 300)和(-30, 570)• 速度 (vx, vy):即火箭在 x和 y方向上的速度• 箭身角度 θ :即火箭箭身与竖直方向的角度,范围为 [0, 360°]•箭身角速度 vθ :即火箭箭身旋转角速度•喷嘴角度 :范围 (-20°, 20°)• 时间t奖励空间由两部分组成reward = dist_reward + pose_reward• dist_reward 距离目标着陆位置的度量• pose_reward 偏离正中线的位置(theta,正负)• shape (1,),类型为 float一般情况下,复杂机械的控制大多都为连续控制,但在精度要求不是特别高的问题中,合理的离散化将会大大提升问题的解决效率 [10]。具体来说,这里将发动机的推力与喷嘴角度进行组合,预设了9个可选的离散动作,即:(0.2g, 0), (0.2g, 20°/s), (0.2g, -20°/s)(1.0g, 0), (1.0g, 20°/s), (1.0g, -20°/s)(2.0g, 0), (2.0g, 20°/s), (2.0g, -20°/s) 实验结果展示下方的图13展示了 PPO 智能体控制火箭回收的完整训练过程,纵轴是每局游戏结束(坠毁或者成功降落)智能体获得的累积回报值,横轴是智能体和环境交互的步数,最终 PPO 智能体可以学习到稳定的火箭回收控制策略。  图13:火箭回收任务 PPO 算法训练曲线,图中5组随机种子平均后的结果,实线为均值,阴影部分为标准 图13:火箭回收任务 PPO 算法训练曲线,图中5组随机种子平均后的结果,实线为均值,阴影部分为标准由于强化学习是一个需要平衡探索和利用的过程,所以需要不断尝试各种决策行为,并根据奖励反馈学习到最优策略。通过对回放视频以及累积回报值的观察,可以发现 PPO 智能体的学习可以主要分为以下几个阶段: 乱喷气直接坠落(0-100k)先学会前半程的hover(200k-500k)然后学习轨迹的落点(大趋势)尽量靠近目标区域(不论中间怎么翻滚)(600k-1M)学会落地减速(但是落地太想靠近目标区域,所以临近落地疯狂翻转)(1M-2M)开始探索较短的轨迹(反复横跳)(2M-3M)学习落地保持竖直(保持后半程的竖直,一定程度上放弃对目标中心的追求)(3M-5M)最终训练收敛时获得的策略和随机初始化策略的行为对比视频如下,完整样例可以参考官方示例 ISSUE:  https://www.zhihu.com/video/16172455503482880012.3 连续动作空间 https://www.zhihu.com/video/16172455503482880012.3 连续动作空间 图14:连续动作空间与离散动作空间对比举例示意图) 图14:连续动作空间与离散动作空间对比举例示意图)在剖析完 PPO 对于离散动作空间的设计之后,本节课第二部分将会聚焦到连续动作空间。离散和连续是决策问题中两种最基本的空间类型。它们之间的关系可以类比于二进制世界中的整型变量与浮点型变量一样,互相独立存在,却又有着密切的联系。换个角度来说,在现实宏观世界中,大部分的事物都是连续地在时空内变化的,只是为了人类定义和使用的方便,或是受限于工具与条件,需要将一些连续变量抽象成不同离散化的选项,构造出一些离散的情形。 引言:连续动作空间的定义通俗点来说,连续空间往往是一个“充实又稠密”的空间,即对于空间中任意一个点,在某种距离函数的定义下,该空间中总存在一些不同于该点的,但距离无穷小的其它点。这一说法的严格的数学定义如下: 连续空间是一个完备测度向量空间,即指一个拓扑空间 X ,假使对该拓扑空间 X 定义一种度量函数 F(x,x') ,对于拓扑空间 X 中的任意点 x ,该点的任意邻域内都存在一个柯西序列:即对于任意小的正实数 r ,序列中都存在一个序数 M ,使得序列中所有序数大于 M 的点 x_N , \forall N>M ,与 x 的距离都小于该正实数, F(x_N,x) 图15:MOBA 类游戏《王者荣耀》中的离散和连续动作空间示例。每一个技能选择是离散动作空间,而确定好技能选择之后,技能的释放范围和方向就可能是连续控制问题 图15:MOBA 类游戏《王者荣耀》中的离散和连续动作空间示例。每一个技能选择是离散动作空间,而确定好技能选择之后,技能的释放范围和方向就可能是连续控制问题此外,对于具体的决策问题,也可以根据情况把问题建模成不同的 MDP,例如强化学习的经典环境 Lunarlander(模拟月球着陆器),就提供了离散和连续2种不同的控制方式: 离散控制模式:对应着4个离散动作,分别为:什么都不做,启动左方向引擎,启动主引擎,启动右方向引擎(启动引擎的推力为一个固定值)。连续控制模式:对应着2个连续的动作变量,即主引擎和助推器的开启力度。前者训练起来更加简洁高效,而后者可以允许更细粒度的操控。部分强化学习环境中的离散动作空间往往都是将原始连续动作中经过某种归类方式获得,是连续动作的某个特殊形式。  图16:Lunarlander 环境的成功示例,智能体控制飞船成功平稳降落到两个旗杆之间理论:PPO 如何建模连续动作空间 图16:Lunarlander 环境的成功示例,智能体控制飞船成功平稳降落到两个旗杆之间理论:PPO 如何建模连续动作空间连续动作空间的特点  图17:bipedalwalker 环境里的四维连续动作实际意义原理图 图17:bipedalwalker 环境里的四维连续动作实际意义原理图更具体地,本章节以经典的学术环境双足机器人行走(bipedalwalker)为例,具体分析连续动作空间的特性。在这个环境中,智能体的任务目标是控制机器人平稳走到右端的终点。如上图所示,具体的决策输出是一个4维的连续变量,这四个维度分别是其机器人位于臀部关节和膝盖关节的铰链的马达转速。对比这样的连续动作空间和上文提到的离散动作空间,我们可以发现: 离散动作空间是非连续的动作的集合(类似分类问题),而连续动作空间是连续的,稠密的,不可数个动作元素组成的连续区间(类似回归问题)。在连续空间中的个体,总能找到许多与它特别相似甚至相同的另一个体;而在离散空间中,不存在完全相同的个体,每个元素自成一派。一般而言,连续动作空间中的变量可以根据具体取值来衡量数值大小和远近关系。比如放置物体时的位置坐标,抛掷物体时的施加力的大小(例如 1.1N > 1N ,那么 两者之差 0.1N 能够明确表达两个力之间的数量关系差异)。而离散动作空间中的变量,则需要用一组类别来区分彼此,集合中各个不同的状态点或动作点之间存在着显著的性质上的差异,但他们之间并没有具体的数量关系(比如之前的马里奥游戏中0指代向左2指代跳跃,但两者相减并没有实际意义)。具体实例比如十字路口处的直行左转右转,开关阀门的开启与闭合等等。总结来说,连续动作空间的特点可以概括为以下三点: 连续的,稠密的,不可数个动作元素组成的连续区间(类似回归问题)可以根据具体取值来衡量数值大小和远近关系可以直接回归,也可构建概率分布采样动作(参数化分布)基于上述分析,关于 PPO 和连续动作空间相关的算法设计,本章节将会从以下两部分展开: 如何设计 PPO 算法去输出连续动作PPO 和其他连续空间上的决策算法(以 DDPG 为例)的对比计算图设计(前向和反向计算图)对于 bipedalwalker 环境这样的连续动作空间如何使用 PPO 算法。这里将从前向和反向计算图分别展开:  图18:bipedalwalker 连续动作环境设计策略并生成动作的前向计算图前向计算图:环境内部将机器人各个部件角速度、水平速度、垂直速度、关节位置和关节角速度、腿与地面的接触以及 10 个激光雷达测距仪测量值等信息抽象为一个24维的向量观测状态。这个状态信息会送入策略网络(policy network),输出所谓的“logit”,但和离散动作空间不同的是,PPO 在连续动作空间采用参数化分布的形式,即针对每一维连续动作输出相应的参数 \mu 和 L (均值和标准差),然后利用这些参数去构建一个相应的高斯分布,并借助这个高斯分布来进行后续的动作选择。相应的,这里也会存在随机性和确定性决策:前者是从高斯分布中采样获得动作后者是直接将动作分布的均值 \mu 作为策略输出的动作,即最大化概率密度的点估计 图18:bipedalwalker 连续动作环境设计策略并生成动作的前向计算图前向计算图:环境内部将机器人各个部件角速度、水平速度、垂直速度、关节位置和关节角速度、腿与地面的接触以及 10 个激光雷达测距仪测量值等信息抽象为一个24维的向量观测状态。这个状态信息会送入策略网络(policy network),输出所谓的“logit”,但和离散动作空间不同的是,PPO 在连续动作空间采用参数化分布的形式,即针对每一维连续动作输出相应的参数 \mu 和 L (均值和标准差),然后利用这些参数去构建一个相应的高斯分布,并借助这个高斯分布来进行后续的动作选择。相应的,这里也会存在随机性和确定性决策:前者是从高斯分布中采样获得动作后者是直接将动作分布的均值 \mu 作为策略输出的动作,即最大化概率密度的点估计 图19:连续动作环境使用 PPO 进行优化时的前向和反向计算图。方形代表神经网络,圆角方形代表输入/输出/中间数据节点,只有蓝色注明的数据节点会传递梯度,其他数据节点只是参与计算反向计算图:将上文的状态输入和动作输出简记之后,图19得到了 PPO 在连续动作空间上的所有关键数据节点,即经典的深度强化学习训练过程,策略网络输入状态输出 logit 并结合其他数据计算损失函数进行优化。但是在 PPO 的各个优化项中,只有重要性采样(Importance Sampling)这一项的分子项回传梯度,分母和优势函数(Advantage)都不参与梯度反向传播,只是作为一个计算项参与其中。 图19:连续动作环境使用 PPO 进行优化时的前向和反向计算图。方形代表神经网络,圆角方形代表输入/输出/中间数据节点,只有蓝色注明的数据节点会传递梯度,其他数据节点只是参与计算反向计算图:将上文的状态输入和动作输出简记之后,图19得到了 PPO 在连续动作空间上的所有关键数据节点,即经典的深度强化学习训练过程,策略网络输入状态输出 logit 并结合其他数据计算损失函数进行优化。但是在 PPO 的各个优化项中,只有重要性采样(Importance Sampling)这一项的分子项回传梯度,分母和优势函数(Advantage)都不参与梯度反向传播,只是作为一个计算项参与其中。另外,对于连续动作空间,如果某个连续动作的最优解是单峰的(大多数控制任务中很常见),就常常使用高斯分布来建模连续动作。一个高斯分布的形态,只决定于其均值向量 \mu 与协方差矩阵 L 。因此仅需让策略神经网络输出高斯分布的均值与方差的数值,随后从该分布中采样即可。除此之外,实际应用中也可以做进一步简化,如果假设不同维度的连续动作是互相独立的分布,那么协方差矩阵可以退化为对角矩阵 [\sigma_{ii}] 。注:关于强化学习算法和重参数化方法的进一步联系可以参考本节课的补充材料。 PPO 与 DDPG 算法对比PPO 和 DDPG 都可以用于经典连续动作空间的决策问题,那么这两个算法相比有什么不同点呢?设计理念  图20:TRPO/PPO 策略提升的迭代过程图 图20:TRPO/PPO 策略提升的迭代过程图PPO 算法来自论文《Proximal Policy Optimization Algorithms》,是经典的策略梯度算法的延伸,中文译为近端策略优化算法。顾名思义,PPO 主要是围绕第一节课中提到的策略提升定理展开,也就是 TRPO 算法的相关算法设计和逻辑,核心思想是在一个临近的信赖区域内,让策略朝着优化目标前进(即最大化累计回报),由此推导出的算法是在原始优化目标的基础上,额外增加单次优化前后,对策略变化距离的限制。只是在具体优化实现中,PPO 的前身 TRPO 为了控制优化中策略的变化幅度,在算法中使用了优化前后策略函数的 KL散度作为约束,进而优化方法较为复杂(具体可参考课程第一讲的补充材料),而 PPO 继承了 TRPO 的核心理念,采用了更易于计算的 clip 函数替代 KL 散度来限制策略的更新幅度,侧重于保持策略函数的近端优化和渐近单调提升,同时,其价值函数主要起辅助评价作用,只是用来计算优势函数 Advantage,类似一个权重乘到优化项上,并不传递梯度: $J^{\text{CLIP}}(\theta')=\mathbb{E}_{(s_{t}, a_{t})\sim \pi_{\theta'}}[\min(\frac{p_{\theta}(a_{t}|s_{t})}{p_{\theta'}(a_{t}|s_{t})}A^{\theta'}(s_{t},a_{t}),\text{clip}(\frac{p_{\theta}(a_{t}|s_{t})}{p_{\theta'}(a_{t}|s_{t})}, 1-\epsilon,1+\epsilon)A^{\theta'}(s_{t},a_{t}))]  图21:DDPG 的算法设计概述,主要围绕优化动作价值函数展开,策略函数用对价值函数求极值的方式引导生成 图21:DDPG 的算法设计概述,主要围绕优化动作价值函数展开,策略函数用对价值函数求极值的方式引导生成相应的,DDPG 算法来自论文《Continuous control with deep reinforcement learning》[11]。DDPG 的全称为 Deep Deterministic Policy Gradient,中文译为使用深度学习的确定性策略梯度算法。虽然和 PPO 一样,它们俩都是 Actor-Critic 系列算法,但两者的设计理念区别很大,DDPG 使用了确定性策略,即一个参数化的策略函数 $\mu(s|\theta_\mu) ,而 PPO 是随机性策略,输出一个选择动作的概率分布。DDPG 算法围绕优化动作价值函数(Q Function)展开,侧重于最小化价值函数的建模误差,而其策略函数由对价值函数求极值的方式引导生成。如图20所示,就是策略网络输出一个动作,交给价值网络来判断动作的好坏,并通过价值网络回传梯度来指导策略进行更新(特性上更类似于Deep Q-learning [12]),更详细的关于 DDPG 算法设计的细节可以参考原始论文。数据属性(On-Policy VS Off-Policy)  图22:强化学习中不同的数据利用范式示意图 图22:强化学习中不同的数据利用范式示意图从数据属性上看: PPO 需要尽可能地选用最新 Policy 采样获得的数据轨迹,是一个 on-policy 算法。而 DDPG 则可以使用来自不同的 Policy 生成的数据,对当前的 Policy 进行训练,是一个 off-policy 算法。PPO 算法需要使用在线数据是由策略提升定理的本质决定的 [13-14],即使用下述公式进行更新: \eta(\pi')=\eta(\pi)+E_{s,a \sim \pi'}(\Sigma_t{\gamma^tA_\pi(s,a)})=\eta(\pi)+\Sigma_s\rho_{\pi'}(\Sigma_a\pi'A_\pi(s,a)) 这个公式从原理上来讲,就是对于迭代更新前后的两个策略函数 \pi 与 \pi' ,如果希望它们的总回报值有稳定的更新提升,即 \eta(\pi')>\eta(\pi) ,那么需要将目标函数设定为此式,并优化 \pi' 使其最大化累计回报 \eta(\pi') 。但在实际操作中无法获得更新后的轨迹 \rho \sim \pi' 的数据,因而只能选取更新前的轨迹 \rho \sim \pi ,来近似最大化下式: J(\pi')=\eta(\pi)+\Sigma_s\rho_{\pi'}(\Sigma_a\pi'A_\pi(s,a))\approx\eta(\pi)+\Sigma_s\rho_{\pi}(\Sigma_a\pi'A_\pi(s,a)) 相应地,为了使策略提升定理有效,需要保证两个策略接近,它们所采集的轨迹也接近,这样才可以使训练稳定。而 DDPG 算法则并不依赖在线数据,这是因为 DDPG 的优化思路来源于 DPG,使用最小化均方贝尔曼误差来拟合值函数,随后使用值函数来引导策略函数的生成,并不会对动作求积分,因此可以使用不同策略的数据进行优化: L(\theta_Q)=E_{data}{(Q(s,a)-(r+\gamma \max Q_{target}(s',a')))^2} J(\theta_\mu)=E_{data}{(Q(s,\mu(s|\theta_\mu)))} 从算法性质上讲,DDPG 的优化思路更接近于 value-based 方法,其算法可靠性和值函数本身的建模质量很相关。注:关于 PPO 和 DDPG 中是否使用重要性采样的详细思考可以参考本节课的相关补充材料。代码:如何实现高斯分布的策略函数关于 PPO 对于连续动作空间神经网络设计的部分,可以参考课程第二章的相关代码。以下部分将进一步详述如何使用 PyTorch distributions 库的相关函数,实现使用高斯分布来将动作参数化的方法: a|s\sim \mathcal{N}(\mu(s),\Sigma(s)) \pi(a|s)=\frac{\exp({-\frac{1}{2}{(a-\mu)}^T\Sigma^{-1}(a-\mu)})}{\sqrt{{(2\pi)}^{k}{|\Sigma|}^{-1}}} 独立分布的动作对于独立分布的动作,我们可以使用多个独立分布的单维高斯分布来实现参数化。因为一个单维高斯分布由均值 \mu 和方差 \sigma^2 构成,对于 PyTorch distributions Normal 类,我们需要提供均值 \mu 和标准差 \sigma 。由于标准差是非负数,我们可以使用对数来构造一个无界的标准差的参数,然后再用指数操作来还原它。如果环境有动作区间的限制,除了通过环境中适配截断动作这个处理办法之外,我们也可以通过函数变换,来让无界的高斯分布,限定至一个有界的区间内。 import torch from torch import nn from torch.distributions import Independent, Normal, TransformedDistribution, TanhTransform # Get mean vector mean = nn.Parameter(torch.zeros(action_dim)) # Get log_sigma to ensure sigma is positive log_sigma = nn.Parameter(torch.zeros(action_dim)) # usually they are model output mean, log_sigma = model(obs) # Define Independent Normal distribution with 1 Batch size sigma=torch.exp(log_sigma) # Get normal distribution and reinterpret 1 batch dim to be event dim distribution = Independent(Normal(output_mean, output_std), reinterpreted_batch_ndims=1) # Transform distribution into a bounded interval by functions such as Tanh into [-1,1] if you need to do so. distribution = TransformedDistribution(base_distribution=distribution, transforms=[TanhTransform()]) # Sample action from Distribution with Autograd to it action=distribution.rsample() # Sample action from Distribution without Autograd to it action=distribution.sample()非独立分布的动作对于存在协方差的非独立的动作分布,我们可以使用一个多维高斯分布来实现参数化。多维高斯分布由均值向量 \mu 和协方差矩阵 \Sigma=LL^T 构成。对于 PyTorch distributions MultivariateNormal 类,我们可以提供均值 \mu 和协方差矩阵 \Sigma 来构造它。因为协方差矩阵是一个对称的(半)正定矩阵,而且需要符合几个特殊要求: 各维度标准差为非负。协方差项的绝对值,小于两个标准差项之积。等价于相关系数位于 [-1,1] 之间。但是我们无法直接使用一个矩阵来编码协方差矩阵 \Sigma ,那样参数自由度太大。而其矩阵分解的下三角矩阵 L 虽然满足自由度的数目,其所需满足的边界要求也不易编码。因此,我们需要借助容易编码边界的相关系数矩阵 C ,和标准差向量 \sigma ,来构造协方差矩阵 \Sigma=[\sigma_{i}c_{ij}\sigma_{j}] 。矩阵 C 自由度为 \frac{(D-1)(D)}{2} ,标准差向量 \sigma 自由度为 D ,共计 \frac{(D+1)(D)}{2} 个参数变量。 import torch from torch import nn from torch.distributions import Independent, MultivariateNormal, TransformedDistribution, TanhTransform, CorrCholeskyTransform # Get mean vector mean = nn.Parameter(torch.zeros(action_dim)) # Get log_sigma to ensure sigma is positive log_sigma = nn.Parameter(torch.zeros(action_dim)) # Get correlation_param to ensure sigma is positive correlation_param = nn.Parameter(torch.zeros(action_dim*(action_dim-1)//2)) # usually they are model output mean, log_sigma,correlation_param = model(obs) # Define Independent Normal distribution with 1 Batch size sigma=torch.exp(log_sigma) # Get low triangle decomposition matrix of correlation matrix low_tri = CorrCholeskyTransform()(correlation_param) # Get covariance matrix corvar_matrix=torch.mul(torch.einsum('bij,bkj->bik', low_tri, low_tri), torch.einsum('bi,bj->bij', sigma, sigma)) # Get multivariate normal distribution and reinterpret 1 batch dim to be event dim distribution = Independent(MultivariateNormal(loc=mean, covariance_matrix=corvar_matrix), reinterpreted_batch_ndims=1) # Transform distribution into a bounded interval by functions such as Tanh into [-1,1] if you need to do so. distribution = TransformedDistribution(base_distribution=distribution, transforms=[TanhTransform()]) # Sample action from Distribution with Autograd to it action=distribution.rsample() # Sample action from Distribution without Autograd to it action=distribution.sample()实践:使用 PPO 来解决无人机姿态控制问题在明确 PPO + 连续动作空间的算法理论和代码实现细节后,我们尝试来应用相关知识解决相应的实际问题,这里选择一个简明的无人机姿态连续控制问题。本章节将会介绍环境的各种细节定义以及使用 PPO 的实践经验。 问题背景近年来,多旋翼无人机技术发展迅速,该技术已经能够赋予很多传统行业一些新的技术方法和商业解决方案,比如物流业、农林业、旅游业等。本节课以一个开源的无人机模拟环境—— gym-pybullet-drones [15-16] 为例介绍 PPO 在连续动作空间上的应用。研究对象是一台性能指标开源的四旋翼小无人机,bitcrazeflie [17]。我们选定了一个简单的任务 Flythrughgate,目标是让四旋翼无人机从原点出发,飞行穿过一座门框。  图23:Flythrughgate 无人机任务环境示意图环境 MDP 设定 图23:Flythrughgate 无人机任务环境示意图环境 MDP 设定状态空间:该任务的状态空间为一个12维度的连续空间,按顺序分别是: 变量性质区间备注x, y, z,无人机在世界坐标中的位置[-1,1]经过clip截断函数和scale范围缩放处理,对于z坐标,被限制在[0,1]之内y, p, rr~roll滚转角, p~pitch俯仰角,y~yaw偏航角[-1,1]r~roll滚转角与p~pitch俯仰角,经过clip截断函数和scale范围缩放处理。y~yaw偏航角仅经过scale范围缩放处理。vx, vy, vz无人机在世界坐标中的速度[-1,1]经过clip截断函数和scale范围缩放处理wx, wy, wz无人机在世界坐标中的角速度[-1,1]经过clip截断函数和scale范围缩放处理动作空间:该任务提供了多种控制无人机的模式,包括PID控制模式,转速控制模式等,对应着不同的动作空间。  图24:四旋翼无人机示意图直接控制四个旋翼的转速模式,4维连续动作空间: 图24:四旋翼无人机示意图直接控制四个旋翼的转速模式,4维连续动作空间:(\frac{20*\Delta{RPM}_0}{{RMP}_{hover}},\frac{20*\Delta{RPM}_1}{{RMP}_{hover}},\frac{20*\Delta{RPM}_2}{{RMP}_{hover}},\frac{20*\Delta{RPM}_3}{{RMP}_{hover}}) 上式中的分子是各个旋翼转速与悬停转速的差值,分母是悬停转速,整体取值范围为 [-1,1] 2.PID 算法修正 position 模式,三维连续空间: (10*\Delta x,10*\Delta y,10*\Delta z) 分别是各个方向上所期望无人机运动的位置修正量的10倍大小,单位为米,取值范围为 [-1,1] 。即智能体只需要给出下一步期望到达的空间运动量,PID 算法将根据当前位置和期望运动量计算得出实际的操作控制信号。 3.PID 算法修正velocity 模式,4维连续空间: ({V_x}/|V| , {V_y}/|V| , {V_z}/|V|, |V|/|V_{max}|) 分别是各个方向上的速度分量的相对大小,以及速度相比系统最大允许速度的相对大小。 采用第一种方式,直接控制无人机四个旋翼各自的转速,将其作为智能体的动作输出,这在物理概念上十分直观。但这种模式在实际训练中会使得无人机的状态十分不稳定,常常倾斜起飞或翻转,而无法达成目标。这是为什么呢?举例来说,如果想让无人机学习到竖直原地起飞这样的动作,就需要它控制四个旋翼转速保持一致,这件事对于人类来说是很简单的概念,但对于智能体来讲是庞大的连续动作空间中的一个点,因此它很难在没有任何辅助信息的情况下探索到这件事。在实际运行中,还会可以发现四个旋翼之间的配合度往往会比较差。因为转速的变化在带来升力的同时也会带来扭矩,扭矩会传递给整体,带来整体的姿态变化,而姿态的变化会影响力的方向,进而让无人机进入负面的状态而产生损失,强化学习算法因此也难以训练。为了解决第一种动作空间的问题,可以借助课程一开始讲到的 Action Shaping 的思路,具体来说就是将强化学习和经典控制理论中的 PID 结合起来使用,即对应到第二和第三种控制方式。实践中,采用 PID 算法可以很大程度上协调和统一四个旋翼之间的转速和配合。因此智能体在这类模式下,训练较为平稳,无论是 PID-position 还是 PID-velocity 模式下都有较好的效果,课程中为了简便主要使用 PID-position 模式。 奖励空间:四旋翼无人机的每个时刻都会基于其位置而获得奖励,计算方法如下: $r(x,y,z)=-10*([x,y,z]-[0,-2*\frac{t}{T},0.75])^2 通过奖励函数的组成,可以看出,该任务将激励无人机往y值减小,且z值增大至某一定高度的轨迹上飞行。此外,由于还会受到不可见的障碍物的影响(门框与地面),存在损失和错过奖励的风险。因此,在该任务中无人机需要学习成功起飞,飞离地面,通过试错的方式,感知和躲避障碍。 实验结果展示接下来的部分将介绍 PPO 智能体完整的训练过程,具体分析使用 PPO 控制 Flythrughgate 的的各个训练阶段: 在初始阶段(训练迭代0~200K),从视频中可以看到,四旋翼无人机驻留在原地,还未学会起飞。这是因为根据强化学习环境的奖励的设计,此时无人机会在每一帧收到一个比较差的 reward。这个阶段 PPO 算法的 Actor 的策略网络显然还无法输出好的决策,这是因为从 Critic (价值网络)是随机初始化的,无法给出正确引导,它需要拟合现状,学习到停留在原地是坏的决策(这从 Critic 输出的均值逐渐下降可以看出,即下图红色箭头): 图25:四旋翼无人机训练各迭代的轨迹的动作价值的平均值统计结果,注:横坐标为训练迭代次数,纵坐标为各迭代的轨迹的动作价值的平均值,红色箭头为调整阶段标注(训练迭代0~200K)在前期阶段(训练迭代200K~300K),四旋翼无人机的 Critic 网络已经逐渐趋向成熟,它开始“意识”到,起飞提升高度,是一件会被鼓励的事情。无人机的高度越高,奖励也越大。因此在这个阶段,从视频中可以看到,无人机在 100K 训练迭代内,迅速地学到了快速起飞这件事情。我们可以看到价值网络的输出明显快速地变好。虽然在刚开始的时候,无人机的飞行方向是反向远离目标方向的(比如训练迭代为220K时)。这说明此时 Actor 网络还没有学习到起飞之后的合理策略。这很正常,因为之前无人机并没有成功飞离地面的经验,没有相关的历史数据,自然 Critic 网络也没有对飞行方向有合理的经验评价,所以 Actor 网络也不会太成熟。但只要无人机离开地面,无人机就会慢慢学到,朝着目标方向飞行才是对的。截至训练迭代300K时,无人机已经大致学会了选择合适的方向。在调整阶段(训练迭代300K~400K),这个阶段四旋翼无人机开始微调策略网络。虽然环境中存在大门这个物理实体,但无人机的观测空间中并没有关于这个实体的描述,因此无法直接感知到它的存在。这使得在训练迭代310K所对应的视频里,无人机为了尝试追求更高的奖励,采纳的飞行路线正好和大门的横梁发生了撞击而掉落,使得奖励整体偶尔会变差。此类的事故导致的训练不稳定现象,在价值网络的平均输出的曲线中也可以清晰的看到: 图25:四旋翼无人机训练各迭代的轨迹的动作价值的平均值统计结果,注:横坐标为训练迭代次数,纵坐标为各迭代的轨迹的动作价值的平均值,红色箭头为调整阶段标注(训练迭代0~200K)在前期阶段(训练迭代200K~300K),四旋翼无人机的 Critic 网络已经逐渐趋向成熟,它开始“意识”到,起飞提升高度,是一件会被鼓励的事情。无人机的高度越高,奖励也越大。因此在这个阶段,从视频中可以看到,无人机在 100K 训练迭代内,迅速地学到了快速起飞这件事情。我们可以看到价值网络的输出明显快速地变好。虽然在刚开始的时候,无人机的飞行方向是反向远离目标方向的(比如训练迭代为220K时)。这说明此时 Actor 网络还没有学习到起飞之后的合理策略。这很正常,因为之前无人机并没有成功飞离地面的经验,没有相关的历史数据,自然 Critic 网络也没有对飞行方向有合理的经验评价,所以 Actor 网络也不会太成熟。但只要无人机离开地面,无人机就会慢慢学到,朝着目标方向飞行才是对的。截至训练迭代300K时,无人机已经大致学会了选择合适的方向。在调整阶段(训练迭代300K~400K),这个阶段四旋翼无人机开始微调策略网络。虽然环境中存在大门这个物理实体,但无人机的观测空间中并没有关于这个实体的描述,因此无法直接感知到它的存在。这使得在训练迭代310K所对应的视频里,无人机为了尝试追求更高的奖励,采纳的飞行路线正好和大门的横梁发生了撞击而掉落,使得奖励整体偶尔会变差。此类的事故导致的训练不稳定现象,在价值网络的平均输出的曲线中也可以清晰的看到: 图26:四旋翼无人机训练各迭代的轨迹的动作价值的平均值统计结果,注:横坐标为训练迭代次数,纵坐标为各迭代的轨迹的动作价值的平均值,红色箭头为调整阶段标注(训练迭代300K~500K)这也就是强化学习中,所谓 Trial-Error 模式的一个特征,通过尝试和犯错,这样智能体的评价器会学习到这种惩罚,从而“感知”到横梁与立柱的存在。最终,四旋翼无人机逐渐调整策略网络,找到了一条,既可以最大化奖励,又可以规避惩罚的最优路线,训练收敛时和随机初始化时无人机完整的轨迹对比视频如下(完整样例也可以参考官方示例 ISSUE): 图26:四旋翼无人机训练各迭代的轨迹的动作价值的平均值统计结果,注:横坐标为训练迭代次数,纵坐标为各迭代的轨迹的动作价值的平均值,红色箭头为调整阶段标注(训练迭代300K~500K)这也就是强化学习中,所谓 Trial-Error 模式的一个特征,通过尝试和犯错,这样智能体的评价器会学习到这种惩罚,从而“感知”到横梁与立柱的存在。最终,四旋翼无人机逐渐调整策略网络,找到了一条,既可以最大化奖励,又可以规避惩罚的最优路线,训练收敛时和随机初始化时无人机完整的轨迹对比视频如下(完整样例也可以参考官方示例 ISSUE):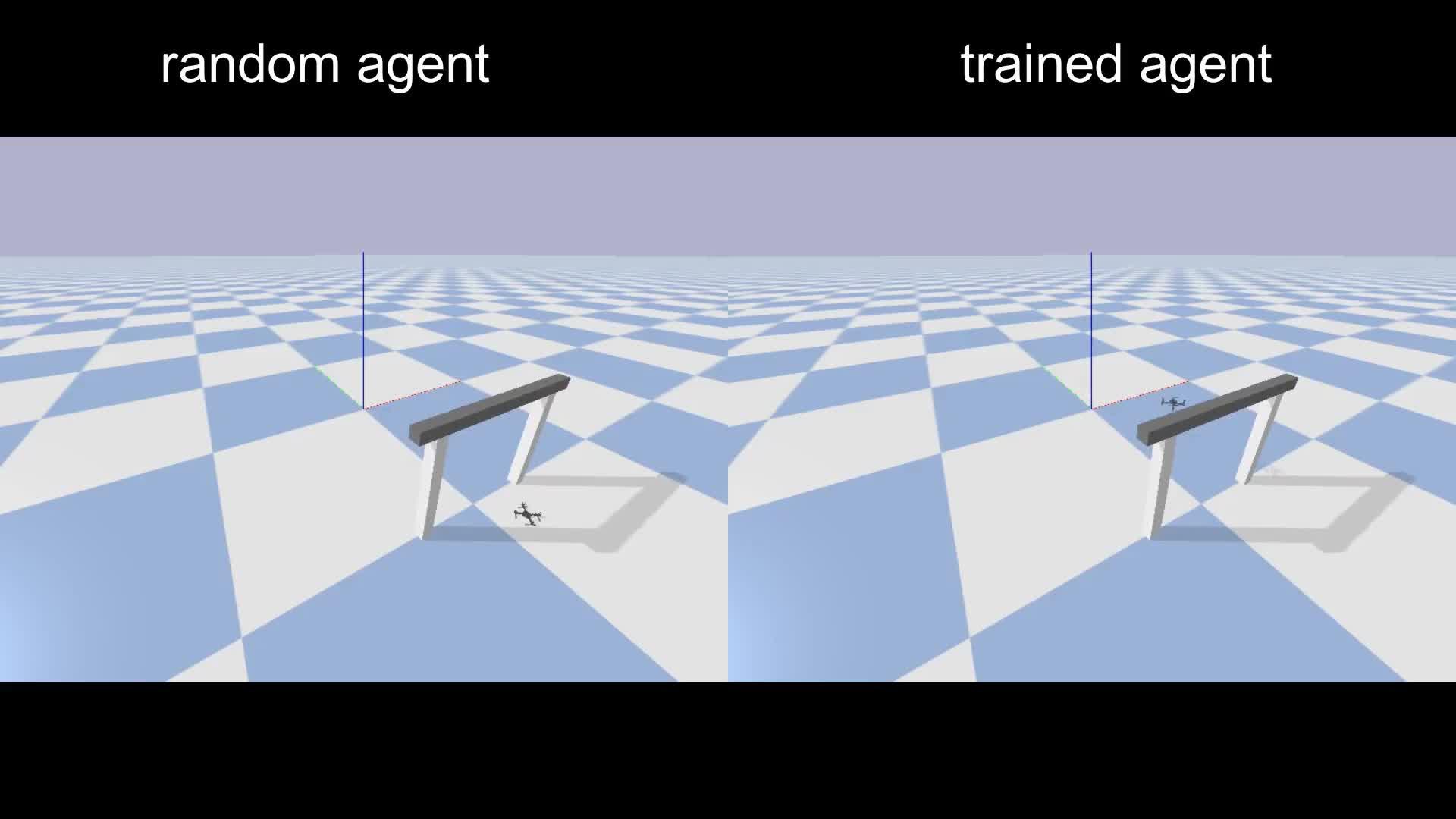 https://www.zhihu.com/video/1617250432857939968 https://www.zhihu.com/video/1617250432857939968
|
【本文地址】