| 并查集(通俗易懂) | 您所在的位置:网站首页 › 数组中各元素不可以重复出现吗 › 并查集(通俗易懂) |
并查集(通俗易懂)
|
并查集
这玩意能干嘛??
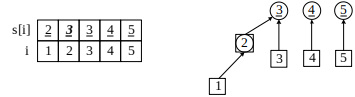
说它是高级数据结构,有点过又不过,它真正做的事情是 1.合并集合 2.查询新的元素是否在某个集合中 根据我最近做题的心得:这玩意处理重复元素问题的时候可是一把好手,当我们在处理问题时能想到用hash去解决的,不妨也去想想并查集,选种更方便的岂不美哉~ 但是更为标准的是,它是图论问题不可或缺的小帮手:什么判断连通性、最小生成树 Kruskal 算法、最近公共祖先(Least Common Ancestors, LCA)等,都需要并查集,所以得认真看认真学~ 操作思路:简单来说分为三部分: 初始化。连通(合并)两个数字。连通性判断。来看看吧 初始化: 数组:a[5]; for(int i=0;i if(p[x]!=x){//这里做了路径压缩,后面会讲 p[x]=find(p[x]); } return p[x]; } 这里面具体整了些啥活呢?1.初始化。定义数组 int s[] 是以结点 i为元素的并查集,开始的时候,还没有处理点与点之间的朋友关系,所以每个点属于独立的集,并且以元素i的值表示它的集 s[i],例如元素 1的集 s[1]=1。下面是图解,左边给出了元素与集合的值,右边画出了逻辑关系。为了便于讲解,左边区分了结点 i和集 s:把集的编号加上了下划线;右边用圆圈表示集,方块表示元素。
图1 并查集的初始化 2.合并。例如加入第一个朋友关系 (1, 2) 。在并查集 s中,把结点 1 合并到结点 2,也就是把结点1的集 1 改成结点 2 的集 2。
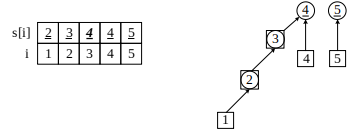
图2 合并(1, 2) 3.合并。加入第二个朋友关系 (1, 3)。查找结点 1 的集,是 2,再递归查找元素 2 的集是2,然后把元素 2 的集 2合并到结点 3 的集 3。此时,结点 1、2、3 都属于一个集。右图中,为简化图示,把元素 2 和集 2 画在了一起。
图3 合并(1, 3) 4.还是合并。加入第三个朋友关系 (2, 4) 。结果如下,你自己分析一下咯。
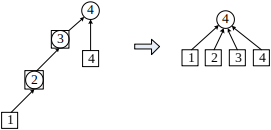
图4 合并(2, 4) 5.查找。上面步骤中已经有查找操作。查找元素的集,是一个递归的过程,直到元素的值和它的集相等,就找到了根结点的集。从上面的图中可以看到,这棵搜索树的高度,可能很大,复杂度是 O(n) 的,变成了一个链表,出现了树的“退化”现象。后面将用“路径压缩”来解决这一问题。 6.统计有多少个集。如果 s[i] = i,这是一个根结点,是它所在的集的代表;统计根结点的数量,就是集的数量。 前面说的路径压缩是啥玩意呢?并查集之所以有用,因为:路径压缩。在上面的查询程序 find() 中,查询元素 i所属的集,需要搜索路径找到根结点,返回的结果是根结点。这条搜索路径可能很长,导致超时。 所以如果在返回的时候,顺便把 i所属的集改成根结点,那么下次再搜的时候,是不是就能在 O(1)的时间内得到结果。 结点,返回的结果是根结点。这条搜索路径可能很长,导致超时。 所以如果在返回的时候,顺便把 i所属的集改成根结点,那么下次再搜的时候,是不是就能在 O(1)的时间内得到结果。
|


【本文地址】