| YOLO v4 实现目标检测详细教程 | 您所在的位置:网站首页 › yolov4目标检测代码 › YOLO v4 实现目标检测详细教程 |
YOLO v4 实现目标检测详细教程
|
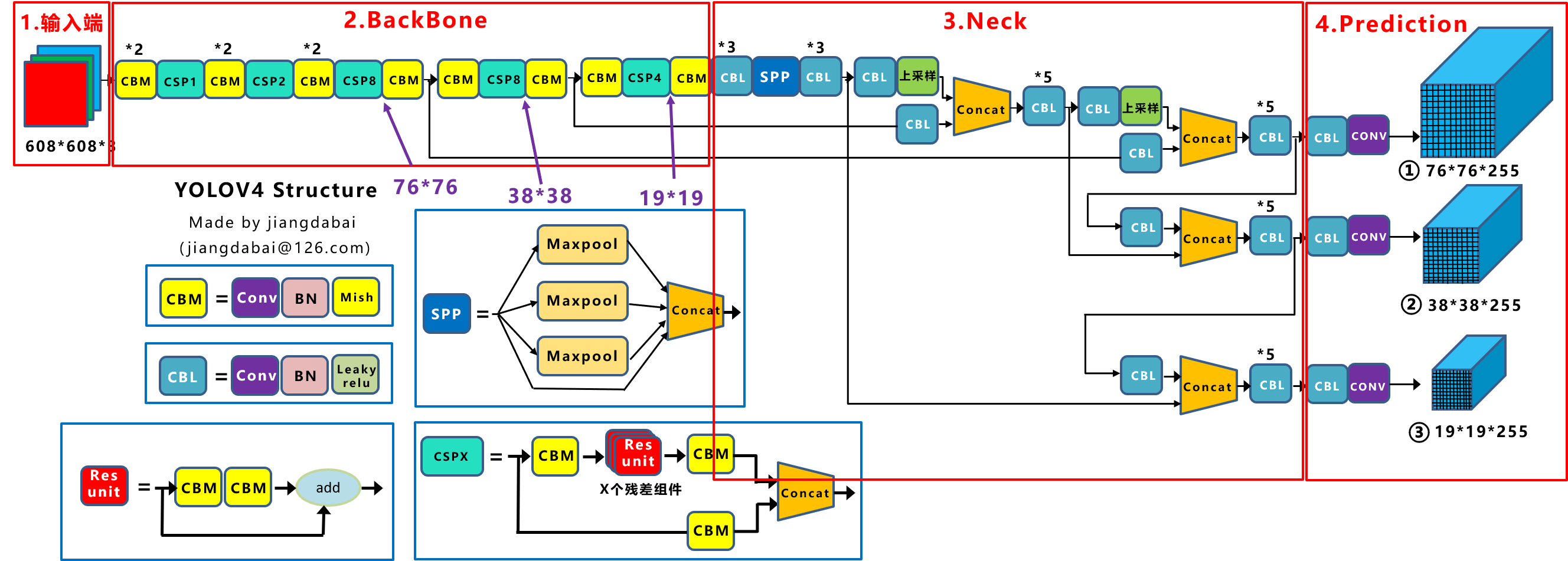
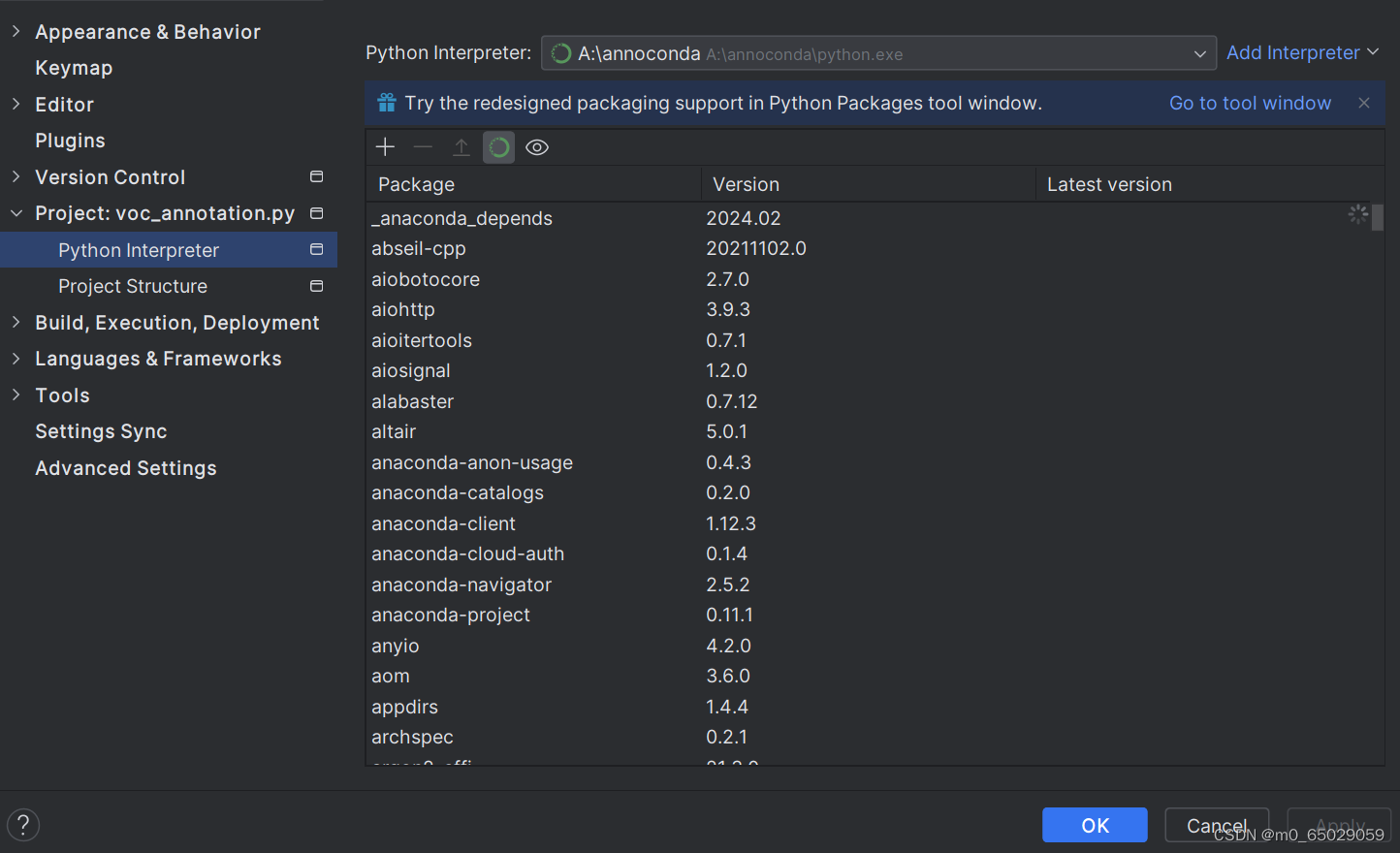
目录 前言 一、YOLO V4算法介绍 1.1 YOLOv4结构图 二、YOLO V4项目实现 2.1下载源代码,保存并解压 2.2下载训练的图片集 2.3利用label标注图片集 2.4将项目导入 Pycharm 2.5pycharm 环境配置 2.6运行yolo.py 2.7运行voc_annotation.py 2.8运行train.py 2.9运行predict.py 三、总结 3.1结果图片展示 3.2实验分析 3.3总结 前言YOLOv4,作为物体检测领域的杰出代表,以其卓越的性能和广泛的应用受到了广泛关注。本文将详细解析YOLOv4的原理,带您深入了解其背后的技术原理和设计思路。 一、YOLO V4算法介绍YOLOv4的算法原理主要基于深度学习,特别是卷积神经网络(CNN),以实现高精度和高效率的物体检测。其核心原理可以概括为构建一个端到端的物体检测模型,该模型充分利用多尺度特征和多层次特征融合的方式进行物体检测。 1.1 YOLOv4结构图
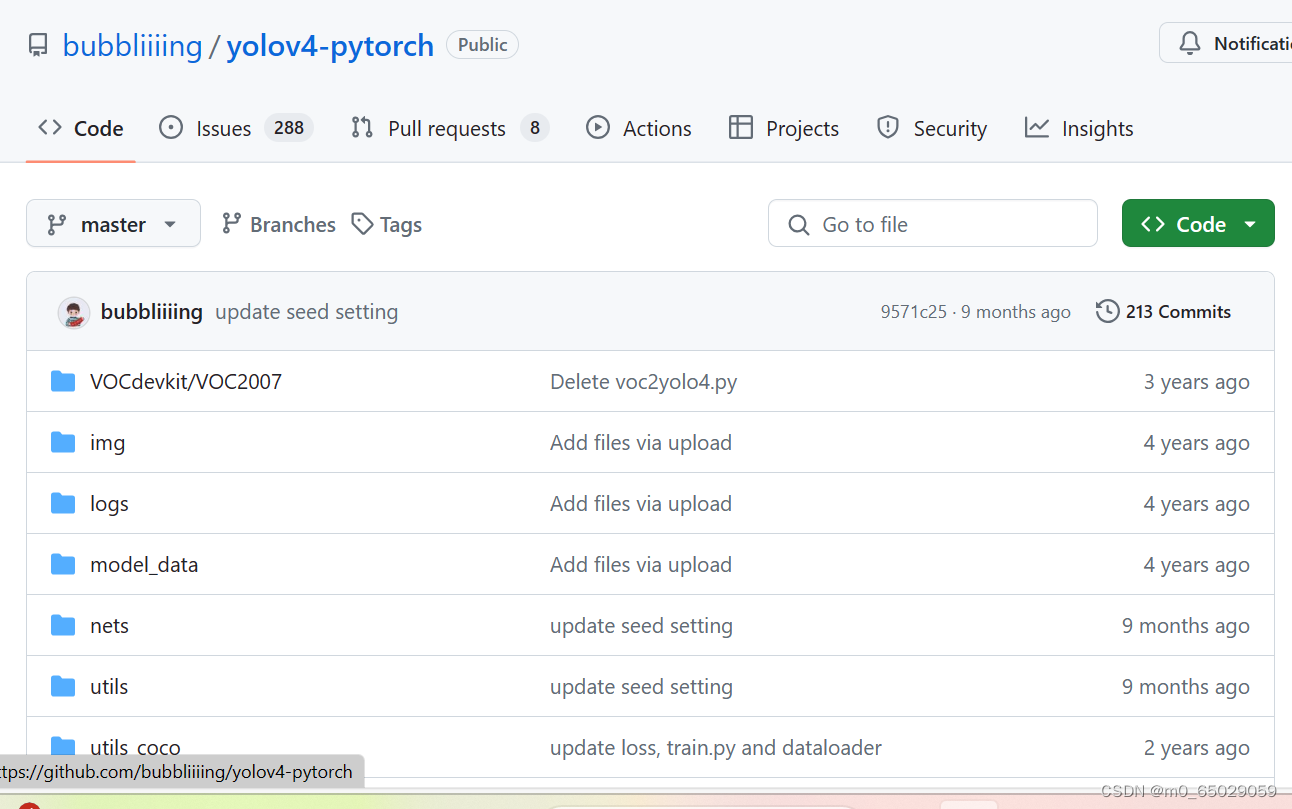
具体来说,YOLOv4的算法流程可以分为以下几个关键部分: 输入端:通常包含图片预处理阶段,例如将输入图像缩放到网络所需的输入大小,并进行归一化等操作,以便模型能够更有效地处理图像数据。Backbone网络:主要是分类网络,用于提取通用的特征表示。在YOLOv4中,采用了CSPDarkNet53作为基准网络。这个网络结构通过使用Mish激活函数代替原始的ReLU激活函数,以及增加Dropblock模块,来进一步提升模型的泛化能力。Neck网络:进一步提升特征的多样性和鲁棒性。YOLOv4利用SPP(空间金字塔池化)模块来融合不同尺度大小的特征图,同时使用自顶向下的FPN(特征金字塔网络)特征金字塔与自底向上的PAN(路径聚合网络)特征金字塔,以增强网络的特征提取能力。Head网络:用于完成目标检测结果的输出。在YOLOv4中,使用了CIOU_Loss来代替Smooth L1 Loss函数,以及DIOU_nms来代替传统的NMS(非极大值抑制)操作,这些改进有助于进一步提高算法的检测精度。除了上述的核心结构,YOLOv4还采用了一系列称为“bag of freebies”(BoF)和“bag of specials”(BoS)的方法和技巧。BoF是指那些只改变训练策略或增加训练成本,但不增加推理成本的方法。而BoS是指那些只会少量增加推理成本,但能显著提高目标检测精度的模块和后处理方法。这些方法和技巧的引入,使得YOLOv4在保持高效率的同时,实现了更高的检测精度。 总的来说,YOLOv4通过结合深度学习和计算机视觉的最新技术,构建了一个强大而高效的物体检测模型,适用于各种复杂场景下的物体检测任务。 二、YOLO V4项目实现 2.1下载源代码,保存并解压 我是课堂老师发送的源代码压缩包,直接保存至U盘。yolov4代码地址:GitHub - bubbliiiing/yolov4-pytorch: 这是一个YoloV4-pytorch的源码,可以用于训练自己的模型。
快捷键W,开始进行标注,对准要标记的人物或物品,进行标注;标注完成之后,会出现标注提示框,输入标注的属性,例如:pandas,点击OK,完成标注
标注完每张图片后点击File中的save as后选择保存的文件夹("yolov4-pytorch-master\yolov4-pytorch-master\VOCdevkit\VOC2007\Annotations"),保存的图片格式为xml
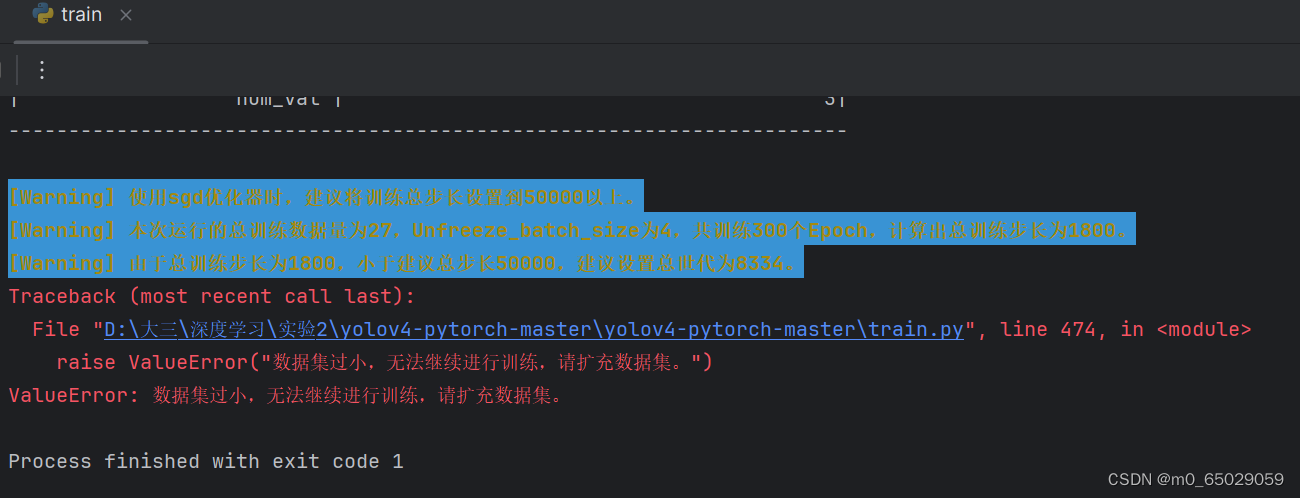
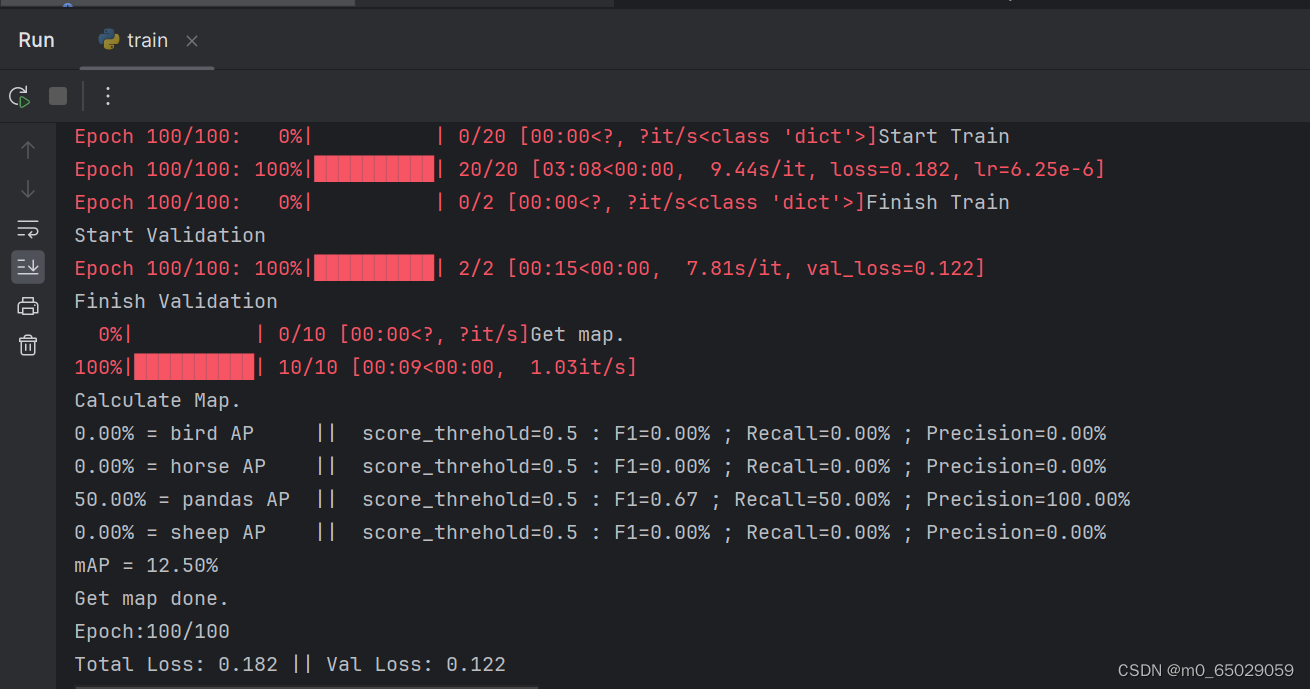
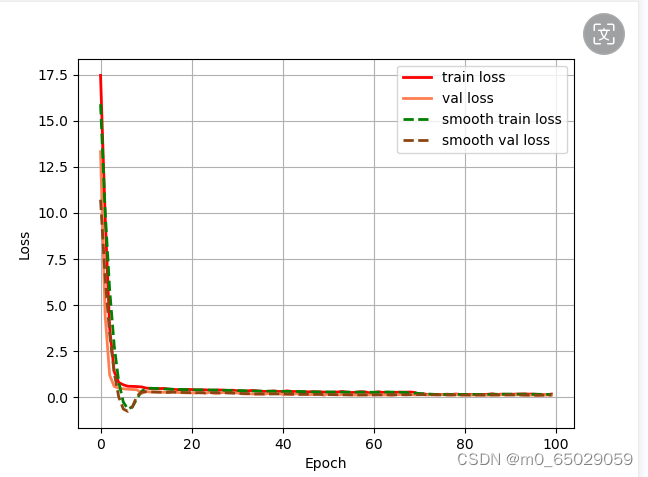
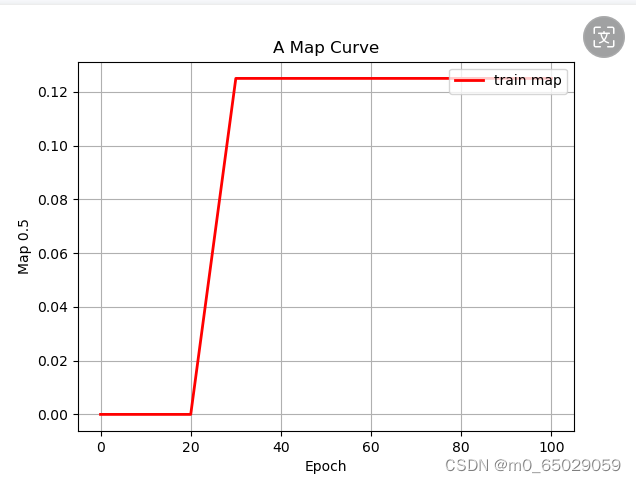
本次实验虽然取得了一定的成果,但仍存在一些局限性。首先,实验所采用的数据集可能存在一定的偏差和局限性,这可能对模型的性能评估产生影响。为了更准确地评估模型的性能,我们需要使用更大规模、更具代表性的数据集进行训练和测试。其次,实验环境的配置也可能对实验结果产生影响。例如,不同的硬件设备和软件版本可能导致模型训练速度和性能的差异。因此,在后续的研究中,我们需要更加关注实验条件的统一性和可重复性。 |






【本文地址】