| emoji | 您所在的位置:网站首页 › emoji转换 › emoji |
emoji
|
前言
今天项目中遇到一个需求,APP的问题上报和意见反馈提意见的时候,需要支持表情。前端没什么,但是如果存入到mysql 就会报错了。导致的原因是,Emoji表情占用4个字节,但是MySQL数据库UTF-8编码最多只能存储3个字节。所以存储就会报错。 想要解决上面的问题,可以修改mysql 的编码格式,这里就不建议了,大部分的还是3个字节的utf-8的编码。如果直接改成4个字节的编号,会造成资源浪费。 第二种方法,可以不用mysql 数据库存储,比如我们存储问题上报或者意见反馈,我们不一定需要使用关系型数据库。我们项目中如果使用了其他的数据库,我们可以使用其他类型的数据。比如我们直接将这类的信息存储在redis 中就是一个不错的选择。 第三种方法,当然就是我们这里想讲的,如果你不想改mysql 的编码格式,也没有其他的数据库,那么就只好通过后端来进行转换了。 依赖有专门的jar 包帮我们做好了转换,我们只需要传入包含表情的字符串就会返回转换后的字符串存在数据库中,取出的时候,再进行转换回来就好了。 com.vdurmont emoji-java 4.0.0github地址:https://github.com/vdurmont/emoji-java 简单使用我们使用也很简单,就两个方法,看下面这个例子: public static void main(String[] args) { String str="\uD83E\uDD17\uD83D\uDE0F\uD83D\uDE36\uD83D\uDE10\uD83D\uDE44"; String result= EmojiParser.parseToAliases(str); System.out.println(result); String res=EmojiParser.parseToUnicode(result); System.out.println(res); }打印的结果如下: :hugging::smirk::no_mouth::neutral_face::eye_roll: 🤗😏😶😐🙄可以看到,EmojiParser.parseToAliases(str)是将包含字符串的str进行转义。 EmojiParser.parseToUnicode(str);是将转义后的str 进行还原成表情。有点像对数据进行加密解密的味道。 一探究竟使用起来不难,但既然是github 上开源的项目,我们也来稍微的深入了解下。可以看到整个jar包还是很简单的,就几个类而已。我们用到的EmojiParser 类,所以我们就来看看这类方法。 默认情况下,别名将解析并包括将提供的任何Fitzpatrick修饰符。 如果要删除或忽略Fitzpatrick修饰符。 parseFromUnicode(input, emojiTransformer) 方法就是将表情转换成对应的字符串了。至于怎么转换的,是将字符串拆成一个个的字符,然后在emojis.json 中匹配,如果emojis.json 有这个表情,就会转义成对应的别名。 所以我们不能保证所有的表情在emojis.json 中都存在,也就是说,这个转换的jar 包只能支持部分表情。比如这个表情就没有。 🤭 String str="\uD83E\uDD2D";
方法二,既然前面说了,表情都是在emojis.json 中匹配的,那如果没有的话,我们在emojis.json 加上对应的关系,是不是就可以了呢?我们来试试。 我们用压缩包打开jar包
别名我们随意起没有关系,只要确保唯一就可以,这样在解密的时候可以转成对应的表情。 然后我们保存修改好的jar,重新导入项目中。 在idea 中发现我们自定义的这个表情不显示。说明idea 是不支持这个表情的。 我们在实际开发过程中,还是可能需要存储表情的,特别是APP,手机上大家输入表情很常见,所以我们在存储的时候,可以将表情转义一下,然后显示的时候再转义回来。 |
 这个类的最上面的一个方法就我们用的最多的将包含有表情的字符串进行转义。可以看到这里用了多态性质,还有一个同命不同参的方法。其实就是给第二个参数赋予了一个默认值。
这个类的最上面的一个方法就我们用的最多的将包含有表情的字符串进行转义。可以看到这里用了多态性质,还有一个同命不同参的方法。其实就是给第二个参数赋予了一个默认值。 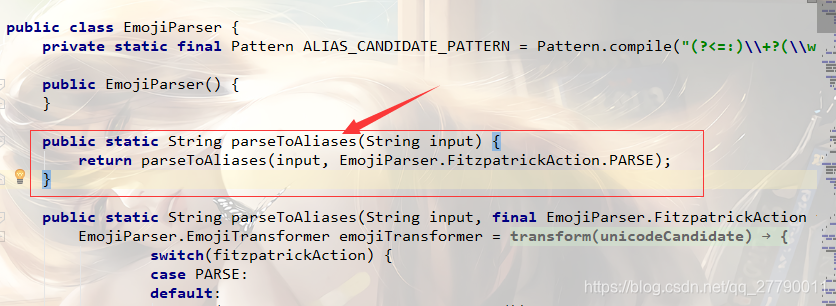 可以看到有三种模式。
可以看到有三种模式。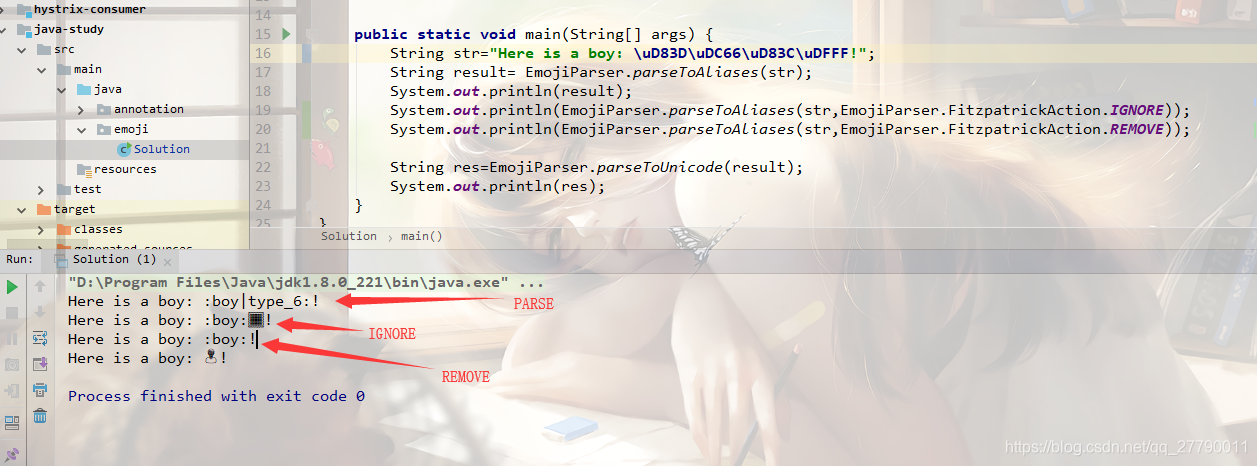
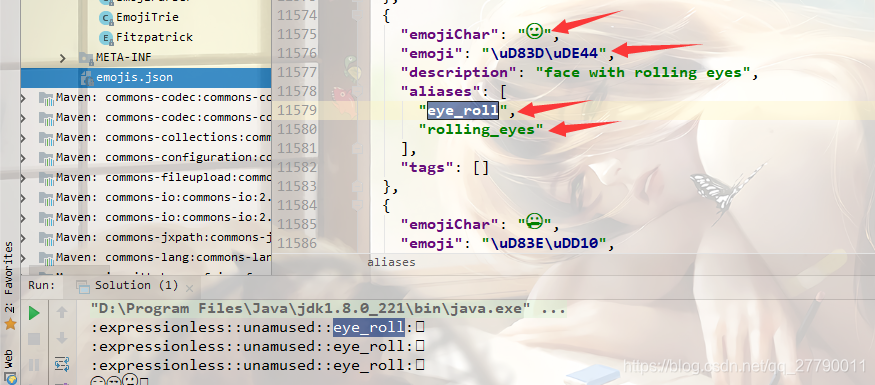
 所以如果我们输入了一些无法转换的表情,入库的时候还是会报错。那没有的表情怎么处理呢? 这里提供两种思路。 一:将不能转换的表情舍弃掉,虽然这个表情在json中没有,但是它依旧是一个四字节的字符。所以我们可以写一个通用方法过滤掉。没能转换的表情依然是下面\ud 开头的,所以用replaceAll 直接替换掉。slipStr是将我们不能转换的表情替换成我们自定义的字符。
所以如果我们输入了一些无法转换的表情,入库的时候还是会报错。那没有的表情怎么处理呢? 这里提供两种思路。 一:将不能转换的表情舍弃掉,虽然这个表情在json中没有,但是它依旧是一个四字节的字符。所以我们可以写一个通用方法过滤掉。没能转换的表情依然是下面\ud 开头的,所以用replaceAll 直接替换掉。slipStr是将我们不能转换的表情替换成我们自定义的字符。 上面就是将不能转义的表情直接移除掉,也可以使用一个我们自定义的默认表情。 但是上面虽然是可行之法,却对用户不是很友好,用户输入的表情,再返回给用户的时候,竟然有些表情没有了。但是毕竟表情起到的修饰作用更多的,没有的话也情有可原。
上面就是将不能转义的表情直接移除掉,也可以使用一个我们自定义的默认表情。 但是上面虽然是可行之法,却对用户不是很友好,用户输入的表情,再返回给用户的时候,竟然有些表情没有了。但是毕竟表情起到的修饰作用更多的,没有的话也情有可原。
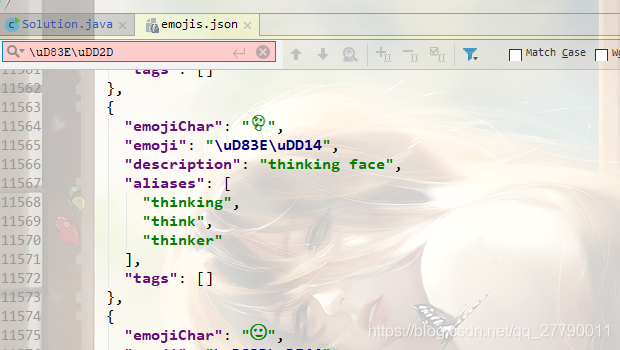
 编辑emojis.json 比如我们🤭 这个表情没有,那我们自己添加一个。
编辑emojis.json 比如我们🤭 这个表情没有,那我们自己添加一个。
 我们再来看看代码是否能正常转换。
我们再来看看代码是否能正常转换。  可以看到,将表情转成我们自定义的别名是没有问题的。但是将它还原成表情,却显示不出来,这里我确信应该是可以还原成功的,只是idea不支持这个表情,所以显示不出来。
可以看到,将表情转成我们自定义的别名是没有问题的。但是将它还原成表情,却显示不出来,这里我确信应该是可以还原成功的,只是idea不支持这个表情,所以显示不出来。【本文地址】