| STFT和声谱图,梅尔频谱(Mel Bank Features)与梅尔倒谱(MFCCs) | 您所在的位置:网站首页 › 声谱图和语谱图 › STFT和声谱图,梅尔频谱(Mel Bank Features)与梅尔倒谱(MFCCs) |
STFT和声谱图,梅尔频谱(Mel Bank Features)与梅尔倒谱(MFCCs)
|
参考链接: https://blog.csdn.net/qq_28006327/article/details/59129110 最近小编在做ASC(Acoustic Scene Classification)问题,不管是用传统的GMM模型,还是用机器学习中的SVM或神经网络模型,提取声音特征都是第一步。梅尔频谱和梅尔倒谱就是使用非常广泛的声音特征形式,小编与它们斗争已有一段时间了,在此总结一下使用它们的经验。 STFT和声谱图(Spectrogram)声音信号本是一维的时域信号,直观上很难看出频率变化规律。如果通过傅里叶变换把它变到频域上,虽然可以看出信号的频率分布,但是丢失了时域信息,无法看出频率分布随时间的变化。为了解决这个问题,很多时频分析手段应运而生。短时傅里叶,小波,Wigner分布等都是常用的时频域分析方法。 短时傅里叶变换(STFT)是最经典的时频域分析方法。傅里叶变换(FT)想必大家都不陌生,这里不做专门介绍。所谓短时傅里叶变换,顾名思义,是对短时的信号做傅里叶变化。那么短时的信号怎么得到的? 是长时的信号分帧得来的。这么一想,STFT的原理非常简单,把一段长信号分帧、加窗,再对每一帧做傅里叶变换(FFT),最后把每一帧的结果沿另一个维度堆叠起来,得到类似于一幅图的二维信号形式。如果我们原始信号是声音信号,那么通过STFT展开得到的二维信号就是所谓的声谱图。 有很多工具方便地支持STFT展开,如果你是和小编一样是python爱好者,可以使用scipy库中的signal模块。如果你想做STFT分解的音频信号(wav文件)的路径存在path变量中,可通过下面的代码得到STFT数据。 import wavio import numpy as np from scipy import signal wav_struct=wavio.read(path) wav=wav_struct.data.astype(float)/np.power(2,wav_struct.sampwidth*8-1) [f,t,X]=signal.spectral.spectrogram(wav,np.hamming(1024),nperseg=1024,noverlap=0,detrend=False,return_onesided=True,mode='magnitude') 12345678关于signal模块中spectrogram的使用方法和各个参数的具体意义,参见https://docs.scipy.org/doc/scipy/reference/generated/scipy.signal.spectrogram.html#scipy.signal.spectrogram 梅尔频谱和梅尔倒谱声谱图往往是很大的一张图,为了得到合适大小的声音特征,往往把它通过梅尔标度滤波器组(mel-scale filter banks),变换为梅尔频谱。什么是梅尔滤波器组呢?这里要从梅尔标度(mel scale)说起。 梅尔标度,the mel scale,由Stevens,Volkmann和Newman在1937年命名。我们知道,频率的单位是赫兹(Hz),人耳能听到的频率范围是20-20000Hz,但人耳对Hz这种标度单位并不是线性感知关系。例如如果我们适应了1000Hz的音调,如果把音调频率提高到2000Hz,我们的耳朵只能觉察到频率提高了一点点,根本察觉不到频率提高了一倍。如果将普通的频率标度转化为梅尔频率标度,映射关系如下式所示: 至于梅尔滤波器怎么生成的(各个三角滤波器起始频率和终止频率怎么得到,等面积梅尔滤波器最高门限值怎么得到)这个问题,我列在后面的参考文献和博客可以回答你。但如果你只是想使用梅尔滤波器组得到梅尔频率谱,并不关心它怎么得到的,那么你只需要关注下面的代码段: import numpy as np import librosa melW=librosa.filters.mel(fs=44100,n_fft=1024,n_mels=40,fmin=0.,fmax=22100) melW /= np.max(melW,axis=-1)[:,None] melX = np.dot(X,melW.T) 1234567其中,变量X是上一小节代码段得到的声谱,melX就是我们说的梅尔频谱。librosa库是python中的语音和信号处理的专业库,具体说明参见:http://librosa.github.io/librosa/generated/librosa.filters.mel.html#librosa.filters.mel 我们知道梅尔频谱了,那么梅尔倒谱是怎么回事呢? 这里涉及到倒谱分析的概念,在附录一(大神zouxy09的博客)介绍的很详细了。记住一句话,在梅尔频谱上做倒谱分析(取对数,做DCT变换)就得到了梅尔倒谱。这里通过一段代码展示梅尔倒谱怎么得到的: import librosa melM = librosa.feature.mfcc(wav,sr=44100,n_mfcc=20) 12而librosa.feature.mfcc这个函数内部是这样的: # -- Mel spectrogram and MFCCs -- # def mfcc(y=None, sr=22050, S=None, n_mfcc=20, **kwargs): if S is None: S = logamplitude(melspectrogram(y=y, sr=sr, **kwargs)) return np.dot(filters.dct(n_mfcc, S.shape[0]), S) 123456可以看出,如果只给定原始的时域信号(即S参数为None),librosa会先通过melspectrogram()函数先提取时域信号y的梅尔频谱,存放到S中,再通过filters.dct()函数做dct变换得到y的梅尔倒谱系数。 感谢librosa可以使我们方便地提取这些有用的声音特征!! 附录【1】http://blog.csdn.net/zouxy09/article/details/9156785/ 【2】http://blog.sina.com.cn/s/blog_892508d501012px5.html 【3】https://en.wikipedia.org/wiki/Mel-frequency_cepstrum |

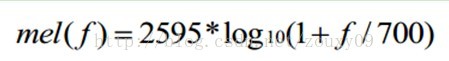
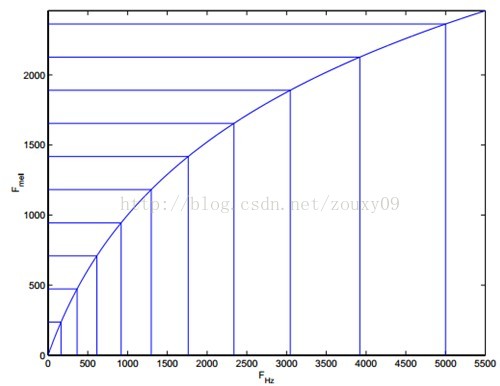 则人耳对频率的感知度就成了线性关系。也就是说,在梅尔标度下,如果两段语音的梅尔频率相差两倍,则人耳可以感知到的音调大概也相差两倍。 让我们观察一下从Hz到mel的映射图,由于它们是log的关系,当频率较小时,mel随Hz变化较快;当频率很大时,mel的上升很缓慢,曲线的斜率很小。这说明了人耳对低频音调的感知较灵敏,在高频时人耳是很迟钝的,梅尔标度滤波器组启发于此。
则人耳对频率的感知度就成了线性关系。也就是说,在梅尔标度下,如果两段语音的梅尔频率相差两倍,则人耳可以感知到的音调大概也相差两倍。 让我们观察一下从Hz到mel的映射图,由于它们是log的关系,当频率较小时,mel随Hz变化较快;当频率很大时,mel的上升很缓慢,曲线的斜率很小。这说明了人耳对低频音调的感知较灵敏,在高频时人耳是很迟钝的,梅尔标度滤波器组启发于此。 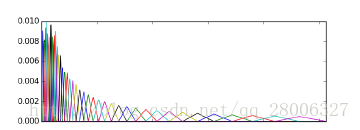 如上图所示,40个三角滤波器组成滤波器组,低频处滤波器密集,门限值大,高频处滤波器稀疏,门限值低。恰好对应了频率越高人耳越迟钝这一客观规律。上图所示的滤波器形式叫做等面积梅尔滤波器(Mel-filter bank with same bank area),在人声领域(语音识别,说话人辨认)等领域应用广泛,但是如果用到非人声领域,就会丢掉很多高频信息。这时我们更喜欢的或许是等高梅尔滤波器(Mel-filter bank with same bank height):
如上图所示,40个三角滤波器组成滤波器组,低频处滤波器密集,门限值大,高频处滤波器稀疏,门限值低。恰好对应了频率越高人耳越迟钝这一客观规律。上图所示的滤波器形式叫做等面积梅尔滤波器(Mel-filter bank with same bank area),在人声领域(语音识别,说话人辨认)等领域应用广泛,但是如果用到非人声领域,就会丢掉很多高频信息。这时我们更喜欢的或许是等高梅尔滤波器(Mel-filter bank with same bank height): 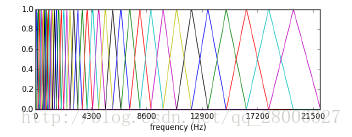
【本文地址】