| Python+MySQL+PowerBI 抖音用户浏览行为数据分析与挖掘 | 您所在的位置:网站首页 › 短视频数据分析主要分析哪些数据 › Python+MySQL+PowerBI 抖音用户浏览行为数据分析与挖掘 |
Python+MySQL+PowerBI 抖音用户浏览行为数据分析与挖掘
|
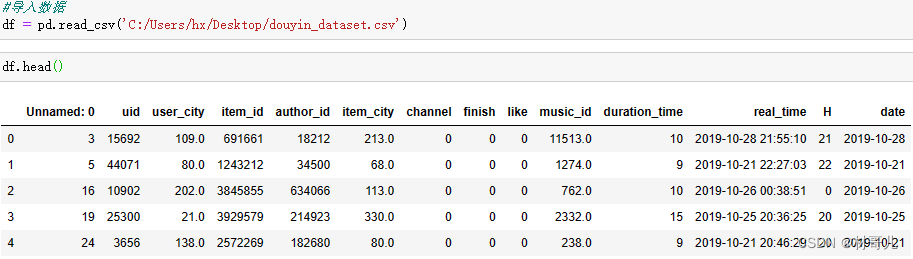
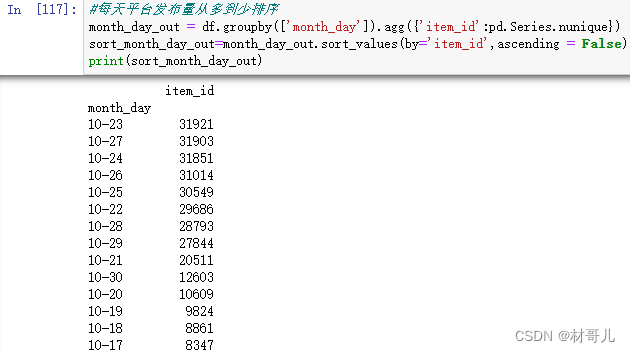
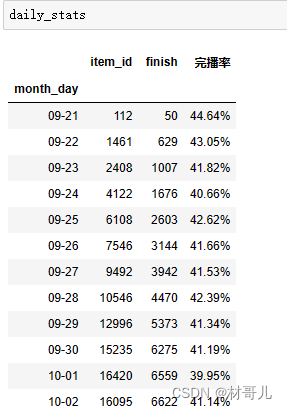
项目概述: 抖音作为当下最火热的短视频软件,探索其产生的数据可以得到极高的价值。本项目模拟从将csv文件导入python工具进行数据分析并对用户点赞预测建模分析,且将python处理后的数据存储到MySQL数据库中,最后用可视化工具输出分析结果,最终可以更好地进行内容优化、产品运营。 数据具体字段信息: 字段字段说明字段字段说明uid用户idlike是否点赞user_city用户城市music_id音乐iditen_id作品idduration_time作品时长author_id作者idreal_time发布时间item_city作者城市H小时(发布)channel作品频道date天(发布)finish是否看完1.分析目的 目的更好地进行内容优化、产品运营。要达到此目的需要从分析运营情况和用户特征两方面进行。 - 运营情况: 根据时间统计平台的浏览量,音乐的使用量,作品发布量,作品完播率。 - 用户特征:聚类划分,可对各个类针对性策划运营方案。此处的用户可分为三个方面,分别为用户,作者,作品 其特征为 用户:浏览量,点赞量,观看作者量 作者:总作品量,总浏览量,总点赞量,完播量,音乐使用情况 作品:被浏览量,点赞量,音乐 2.数据获取: 数据集来自:抖音用户数据集 - Heywhale.com 导入数据并存为 DataFrame 结构 3.数据处理 先审视数据:得到数据共有1737312条 ①选择子集:根据分析目的过滤掉不需要的列,此处Unnamed: 0 ,real_time,user_city,item_city,duration_time 列为无效数据,直接删除 #删除多余列 del df['Unnamed: 0'] del df['real_time'] del df['user_city'] del df['item_city'] del df['duration_time']②列名重命名:列名正常,不需要重命名. ③删除重复值:按需删除不需要的重复值以达到唯一性. #删除重复行 df.drop_duplicates().head()④处理缺失值:查看缺失值发现无缺失值 ⑤一致化处理:有的数据列数据类型需要修改 #一致化处理 df['date'] = pd.to_datetime(df['date']) df['music_id'] = df['music_id'].astype(int)再次查看数据类型: ⑥异常值处理:无异常值 4.数据分析 4.1运营分析 先查看时间范围 此时根据时间范围决定按天分析,先将月和天分离新增一列 每天浏览量:计算并排序以便观察 音乐的使用量:从多到少排序 每天作品的发布量:计算并排序 作品完播率:从大到小排序 要计算每天作品的完播率,要用每天完播作品量除每天作品发布量 #完播率 daily_stats = pd.DataFrame() daily_stats['item_id'] = df.groupby('month_day')['item_id'].count() daily_stats.index = daily_stats['item_id'].index daily_stats['finish'] = df.groupby('month_day')['finish'].sum() #计算完播率为完播量/发布量 daily_stats['完播率'] = daily_stats['finish']/daily_stats['item_id'] #显示为百分比 daily_stats['完播率'] = daily_stats['完播率'].map(lambda x:'{:.2%}'.format(x))
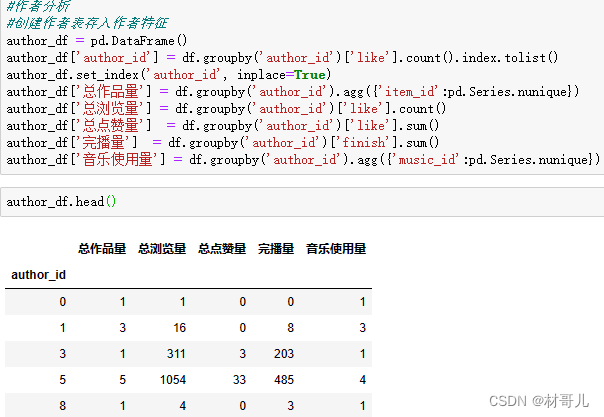
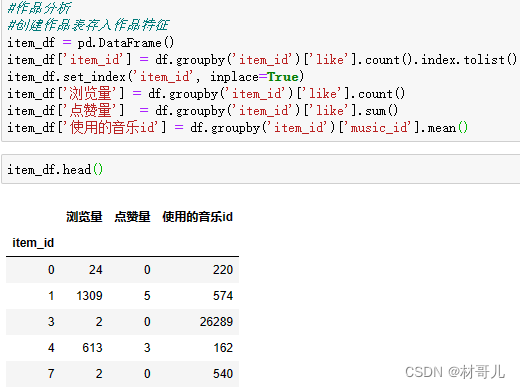
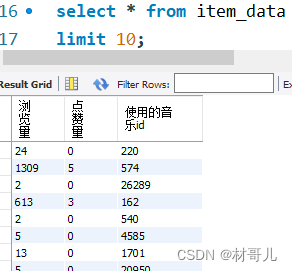
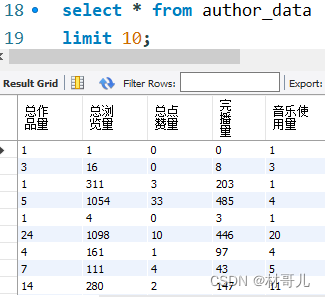
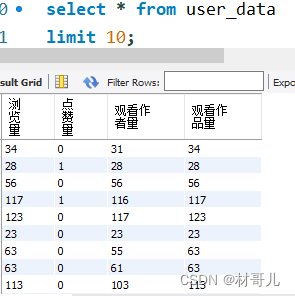
4.2用户特征: 用户:浏览量,点赞量,观看作者量 作者:总作品量,总浏览量,总点赞量,完播量,音乐使用量 作品:被浏览量,点赞量,音乐 得到三个维度的对象特征后保存,后续可对这三种对象建模分类预测,此次不做建模操作。 模拟业务需要: 将清洗过的数据和三个对象特征表保存到MySQL服务器中 连接数据库 #连接到MySQL数据库 db = pymysql.connect(host='127.0.0.1', user='root', password='123456' ) # 创建游标对象 cursor = db.cursor() #查看有哪些数据库 cursor.execute("SHOW DATABASES") cursor.fetchall()创建此次项目数据库douyin_data cursor.execute("CREATE DATABASE IF NOT EXISTS douyin_data") cursor.execute("USE douyin_data")依次创建四个表并导入数据 total_data #创建表total_data create_table_total_data = """ CREATE TABLE IF NOT EXISTS total_data ( uid BIGINT, item_id BIGINT, author_id BIGINT, channel BIGINT, finish INT, _like INT, music_id BIGINT, H BIGINT, _date DATE, month_day VARCHAR(40) ) """ cursor.execute(create_table_total_data) # 建立与MySQL数据库的连接 database_connection = create_engine('mysql+pymysql://root:[email protected]/douyin_data') # 将df插入到total_data表中 df.to_sql('total_data', con=database_connection, if_exists='replace', index=False)item_data #创建表item_data create_table_item_data = """ CREATE TABLE IF NOT EXISTS item_data ( 浏览量 BIGINT, 点赞量 BIGINT, 使用的音乐id BIGINT ) """ cursor.execute(create_table_item_data) # 建立与MySQL数据库的连接 database_connection = create_engine('mysql+pymysql://root:[email protected]/douyin_data') # 将item_df插入到item_data表中 item_df.to_sql('item_data', con=database_connection, if_exists='replace', index=False)author_data #创建表author_data create_table_author_data = """ CREATE TABLE IF NOT EXISTS author_data ( 总作品量 BIGINT, 总浏览量 BIGINT, 总点赞量 BIGINT, 完播量 BIGINT, 音乐使用量 BIGINT ) """ cursor.execute(create_table_author_data) # 建立与MySQL数据库的连接 database_connection = create_engine('mysql+pymysql://root:[email protected]/douyin_data') # 将df插入到total_data表中 author_df.to_sql('author_data', con=database_connection, if_exists='replace', index=False)user_data #创建表user_data create_table_user_data = """ CREATE TABLE IF NOT EXISTS user_data ( 浏览量 BIGINT, 点赞量 BIGINT, 观看作者量 BIGINT, 观看作品量 BIGINT ) """ cursor.execute(create_table_user_data) # 建立与MySQL数据库的连接 database_connection = create_engine('mysql+pymysql://root:[email protected]/douyin_data') # 将df插入到total_data表中 user_df.to_sql('author_data', con=database_connection, if_exists='replace', index=False)导入后查看douyin数据库下的表: 前往数据库查看,确认导入成功 5.数据建模 对用户的点赞预测:在抖音用户浏览行为数据中,希望通过用户的属性,如用户城市、作品id、作者id、作者城市和作品时长等特征来预测用户是否点赞。由于点赞预测是一个二分类问题,逻辑回归是一个合适的模型选择。 先引入建模所需的库: import pandas as pd from sklearn.model_selection import train_test_split from sklearn.linear_model import LogisticRegression from sklearn.metrics import accuracy_score处理所需要的数据:删除不需要的数据 df = pd.read_csv('C:/Users/hx/Desktop/douyin_dataset.csv') del df['Unnamed: 0'], df['H'], df['date'], df['finish'], df['channel'] df.head()建模:划分训练集比测试集 8:2 # 特征选择:选择需要用于预测的特征 features = df[["user_city", "item_id", "author_id", "duration_time", "item_city"]] # 目标变量:选择需要预测的目标变量 target = df["like"] # 数据预处理:处理缺失值和非数值特征 features = features.fillna(0) # 处理缺失值 features = pd.get_dummies(features) # 处理非数值特征 # 划分训练集和测试集 X_train, X_test, y_train, y_test = train_test_split(features, target, test_size=0.2) # 创建并训练模型 model = LogisticRegression() model.fit(X_train, y_train) # 在测试集上进行预测 predictions = model.predict(X_test)计算准确率 6.可视化 将运营情况可视化能够提高数据分析效率,发现潜在问题与机遇,促进跨部门沟通,支持实时监控与预警,有助于企业提高业务效益。 使用Power BI Desktop进行可视化可以快速地将大量数据转化为直观、易懂的图表,从而提高数据分析效率,实现高效运营。 选择从MySQL数据库中导入数据 导入后即可开始做可视化分析 此处就不演示制作图表了 7.结果应用 结果应用可输出为文档或其他,此处直接输出结果 运营分析 - 根据时间和浏览量走势可以得到浏览量是逐步上升的,表明运营情况在逐步向好. - 根据音乐使用量能够提取出最受大众喜爱的音乐,能针对音乐属性,如类型,曲风等再获取相似歌曲版权引入,能再提升用户的体验,获得更多流量. - 根据时间和作品发布量走势可以得到发布量在逐步上升,此趋势能够为浏览用户提供更多的选择,可以为平台吸引更多用户. - 根据作品每天的完播率趋势从表面看到是在下降,但每天的作品发布量在上升,且上升趋势大于完播率的下降趋势,所以整体完播率也是在逐步向好的,要提高完播率,可以从引入用户方面,也可以从提升视频质量方面,具体要结合业务实施. 特征分析 - 通过对用户特征的分析,可以将用户分类,根据不同类别的用户定制实施不同的运营方案和推广信息. - 通过对作者特征的分析,将作者分类,给予特征满业务要求的作者推广流量,可以提高作者的创作积极性,从而产生更多高质量作品. - 通过对作品特征的分析,可以找到客户喜欢的类型,可以推送优秀的作品给客户,能提高作品的浏览量. 建模分析 对用户点赞预测建模分析可以帮助抖音平台了解用户的偏好和行为习惯,从而为用户个性化推荐内容,提高用户留存率和使用体验。可以帮助抖音平台了解哪些类型的内容更容易被用户点赞,从而指导作者创作更受欢迎的视频。还可以帮助抖音平台发现和识别热门视频和用户,通过推广合作等方式增加平台的收入和影响力。 (PS:此篇文章为个人总结,如有错误欢迎指出) |







 建模完成后只需将新产生的用户浏览数据带入该模型即可预测用户点赞行为
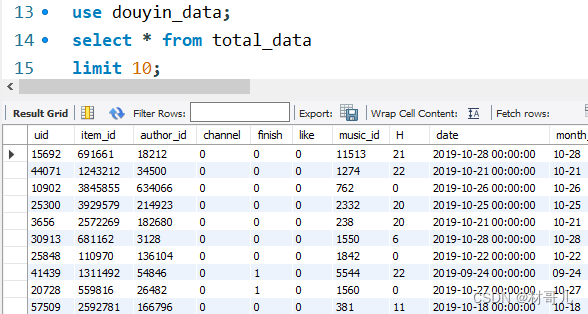
建模完成后只需将新产生的用户浏览数据带入该模型即可预测用户点赞行为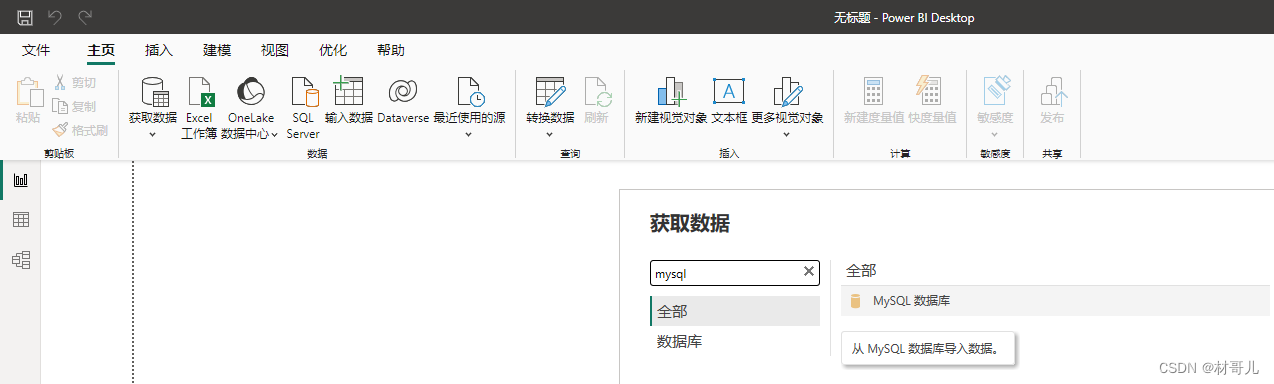 此处只分析运营情况,所以只导入表total_data
此处只分析运营情况,所以只导入表total_data
【本文地址】