| python下载某短视频平台音视频、评论、点赞数(详细教程,文末附完整代码 | 您所在的位置:网站首页 › 松柏cp › python下载某短视频平台音视频、评论、点赞数(详细教程,文末附完整代码 |
python下载某短视频平台音视频、评论、点赞数(详细教程,文末附完整代码
|
前言
整理一下python在抖音网页版的应用 以抓取一个视频及评论为例进行讲解 获取视频 url随便找一个视频,点击进入详情,页面中地址栏里就是该视频的 url 。 接下来就是简单的发送请求,唯一需要注意的一点就是 headers 中除了要配置 UA 外,还要配置 cookie 信息,否则拿不到想要的数据,cookie 位置在下图 在页面源码数据中有很长一串数据是经过 url 编码的,而我们需要的数据都在这串数据中,因此我们需要拿到这串数据。通过正则表达式定位并取出这串数据,然后调用 requests 模块下的工具包 utils 里的 unquote 方法解码这串数据(得到的是 string 类型的数据),代码如下: data_en = re.findall('(.*?)',data)[0] data_all = requests.utils.unquote(data_en)后面就是经典的资源定位了,我们先来说视频下载,先在数据中找到视频的链接,会发现有两个 评论数据及标题类似,只是位置不同 comments = re.findall("\"comments\":\[(.*?)],\"consumerTime\":",data_all) title = re.findall('"desc":"(.*?)","authorUserId"',data_all)[0].replace(' ','')再后面的话就是持久化存储了,这个没什么好说的,就不再赘述了,我直接贴一下存视频的代码,评论也是类似的 if not os.path.exists('./video'): os.mkdir('./video') video_content = requests.get(url=video_url,headers=headers).content with open(f'./video/{title}.mp4','wb+') as f: f.write(video_content) 结尾到这我们就基本完成了,批量的话只是稍微调一下的问题,主要问题还是在数据的解析上。 如果有问题的话,可以评论区留言,也可以私信我,欢迎大家一起讨论 完整代码 import requests, re, json, os url = "" headers = { 'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/93.0.4577.82 Safari/537.36', 'cookie' : '' } data = requests.get(url=url, headers=headers) data.encoding = 'utf-8' data = data.text data_en = re.findall('(.*?)',data)[0] data_all = requests.utils.unquote(data_en) # 解析视频url:正则 video_url = 'https:' + re.findall('"playAddr":\[{"src":".*?{"src":"(.*?)"}]',data_all)[0] # print(video_url) # 正则 comments = re.findall("\"comments\":\[(.*?)],\"consumerTime\":",data_all) # print(comments) # title title = re.findall('"desc":"(.*?)","authorUserId"',data_all)[0].replace(' ','') #保存 if not os.path.exists('./video'): os.mkdir('./video') video_content = requests.get(url=video_url, headers=headers).content with open(f'./video/{title}.mp4', 'wb+') as f: f.write(video_content)自己配置上 url 和 cookie 就能直接运行 2022.06.14更新今天看评论说会报错,我运行了一下,还真是,估计是官方有所更新。所有又改了一下,逻辑没什么变化,主要是正则有所改变 import requests, re, json, os url = "" headers = { 'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:100.0) Gecko/20100101 Firefox/100.0', 'cookie' : '' } data = requests.get(url=url, headers=headers) data.encoding = 'utf-8' data = data.text # print(data) data_en = re.findall('(.*?)',data)[0] data_all = requests.utils.unquote(data_en) # 解析视频url:正则 video_url = 'https:' + re.findall('"playAddr":\[{"src":".*?{"src":"(.*?)"}]',data_all)[0] print(video_url) # 正则 comments = re.findall("\"comments\":\[(.*?)],\"consumerTime\":",data_all) print(comments) # title title = re.findall(']}},"desc":"(.*?)","authorUserId"',data_all)[0].replace(' ','') print('-----------------------------------------------------------------------------------------') print(title) #保存 if not os.path.exists('./video'): os.mkdir('./video') video_content = requests.get(url=video_url, headers=headers).content # 由于直接将文案作为保存视频的文件名,所以在文案过长的时候会报错,把这两行注释然后打开最后两行的注释就行,一个简单的切片,也可以用自己的方法替换 with open(f'./video/{title}.mp4', 'wb+') as f: f.write(video_content) # with open(f'./video/{title[0:10]}.mp4', 'wb+') as f: # f.write(video_content)还有就是有时候会报Latin-1编码异常,这个问题大概率是由于请求头里含有…引起的,打开原始按钮重复复制就解决了。其他问题的话都可以留言讨论。 |
 手机端复制链接后,先粘到浏览器地址栏访问,url 会自动转换,这时候复制地址栏的 url 即可。
手机端复制链接后,先粘到浏览器地址栏访问,url 会自动转换,这时候复制地址栏的 url 即可。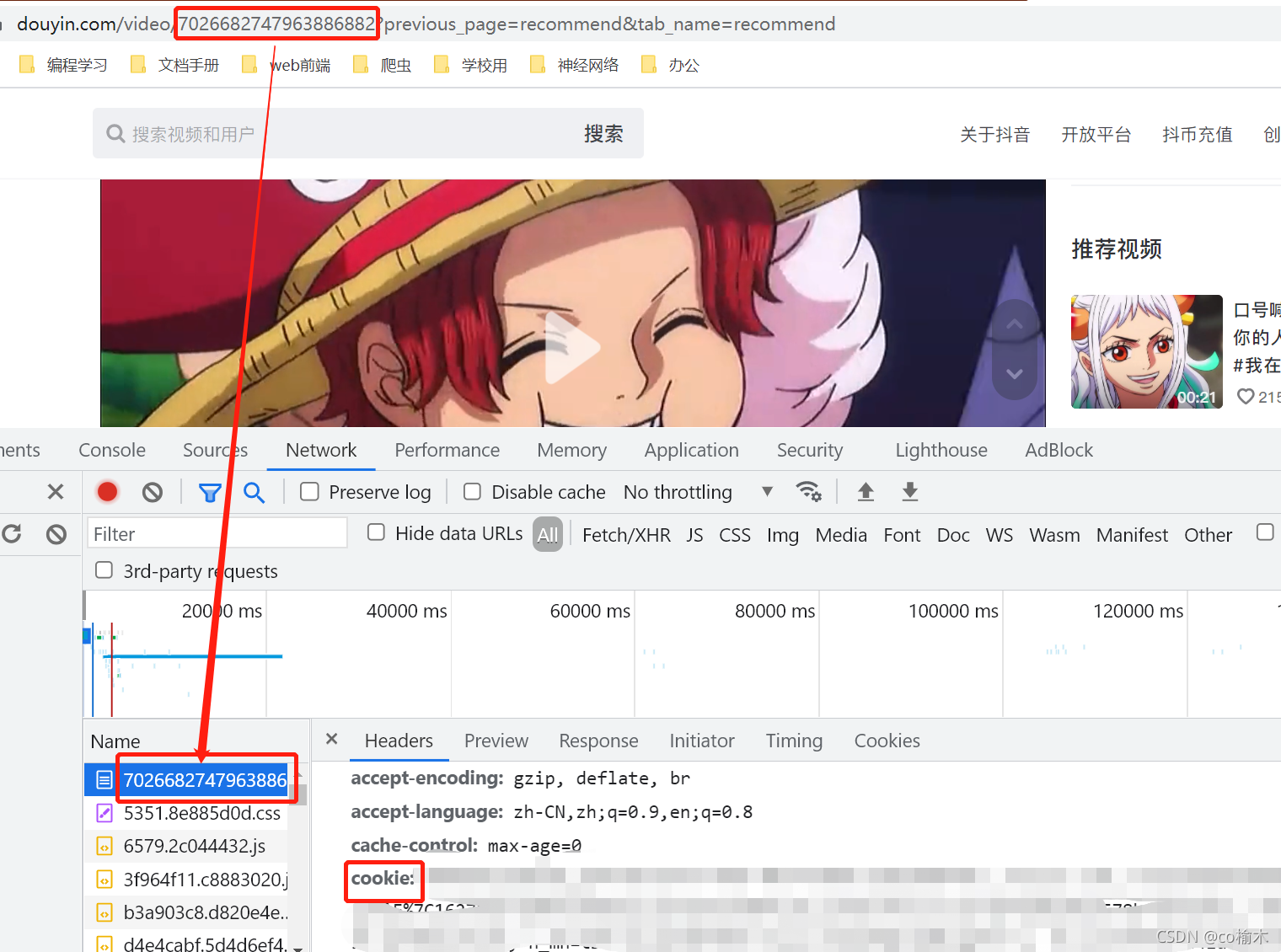 配置好 headers 之后,发送 get 请求,拿到页面源码数据
配置好 headers 之后,发送 get 请求,拿到页面源码数据 经过我的测试,第一个链接的视频带有水印,而第二个没有,这个根据自己的需要选择就行,只是改个索引的问题,我这里选择第二个无水印的,编写正则表达式将其取出
经过我的测试,第一个链接的视频带有水印,而第二个没有,这个根据自己的需要选择就行,只是改个索引的问题,我这里选择第二个无水印的,编写正则表达式将其取出
【本文地址】