| stable diffusion webui如何工作以及采样方法的对比 | 您所在的位置:网站首页 › 捞面器怎么用 › stable diffusion webui如何工作以及采样方法的对比 |
stable diffusion webui如何工作以及采样方法的对比
|
什么是Stable diffusion Stable diffusion是一中潜在扩散模型(latent diffusion model),这里面除了模型这两个字,潜在和扩散听上去就不太像人话了,这里我们先弄明白什么是扩散模型,它是在训练图像上逐渐添加噪声,最后变成完全随机噪声图。这个过程就像是一滴墨水滴在一杯清水里,会慢慢扩散最终均匀分布在清水里一样,扩散这个名字就是那么来的,参考下图:  这是一个前向扩散的过程,因为让一张图片越来越模糊没什么技术含量。 而扩散模型就是通过训练让上述过程获得逆向从随机噪声图生成清晰图像的过程。实现下图的过程,而训练的重点就是下图中的噪声预测器(noise predictor),它可以通过训练得出每次需要减掉的噪声,每次需要减多少噪声是预测出来的,这就是一个叫U-net的模型(先请记住它,下面还会反复提它),从而实现还原清晰图片的目的。 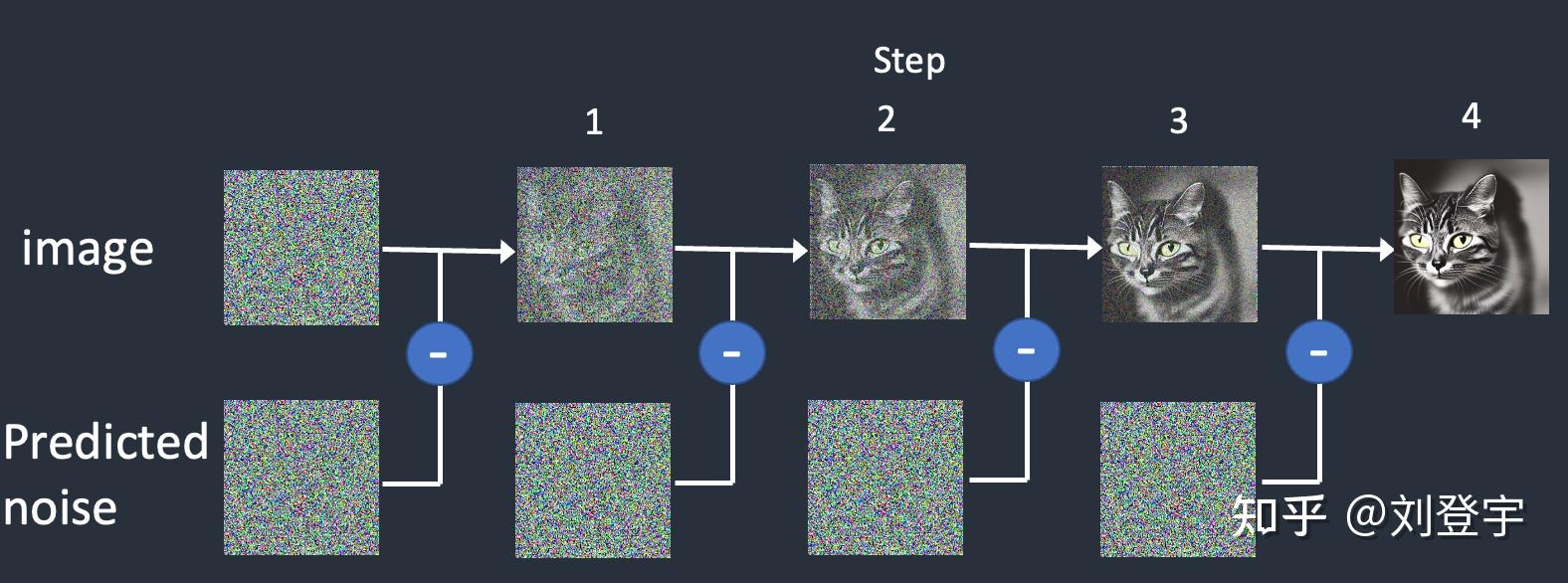 但是,这个过程无论是模型训练,还是推理(你生成图片的过程)都是非常贵的,需要海量的算力支持和内存需求,而stable diffusion就是让它不那么贵的解决方案,核心思想也很简单:压缩图像,它通过一个叫变分自编码器(VAE)的模型,把图像压缩到它亲妈都不认识到的程度,甚至把此类压缩方式称作降维,这种降维级别的压缩且不丢失重要信息与一套理论相关,即流形假说(Manifold hypothesis),认为高维空间的数据集可以对应到低维的潜在流形(latent manifolds )上,训练需要找到就是一些共同的高维特征。所以经过此压缩后,这个时候图像被称作低维潜在(latent)的"图像",作为U-net的输入,去了潜空间(latent space),请参考下图标注latent space的绿色区域,也就是U-net现在工作的地方。在低维的潜空间里一步一步降噪后,完成反向扩散的低维“图片”还得通过VAE的解码器,把图像从潜空间转换回像素空间(pixel space)。 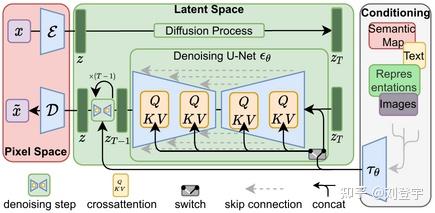 但是这张图片中好像除了刚刚提到潜空间和像素空间,其余的内容是什么鬼我们目前还不知道,目前的重点是压缩,因为这是让反向扩散推理以生成图片的基石,它让Stable Diffusion在消费级GPU上运行成为了可能。下面聊Stable diffusion的具体工作流程。图片来源[1] 三大核心组成部分VAE:包括Encoder编码器和Decoder解码器,用于图像从像素空间到潜空间的转换,或者叫降维或升维,由于用于降维的VAE Encoder 只在训练模型的阶段使用,推理过程(图像生成)只需要VAE Decoder解码器就ok了,而网上常见的VAE文件,就是对这个VAE Decoder解码器的微调改进版本,用于解决角色面部眼睛等细节方面的问题。 U-net:输出预测的噪声残差,用于每次迭代过程的降噪,提供了交叉注意力层,并且通过交叉注意力机制来消耗CLIP提供的条件文本嵌入U-net,输出预测的噪声残差,实现有条件(被文本指挥)的迭代降噪。 CLIP:将Prompt文本转化成能够让U-net使用的嵌入(embedding),达到实现文本作为条件生成图片的过程,这里反复提到嵌入这个概念是因为,可以通过微调的方式,发出带有关键词的embedding,用于调整图片的样式。你能下载到的textual inversion就是通过这种方式实现调整生成图像效果的,优点是文件的体积非常小。 整体工作流程见下图[2]: 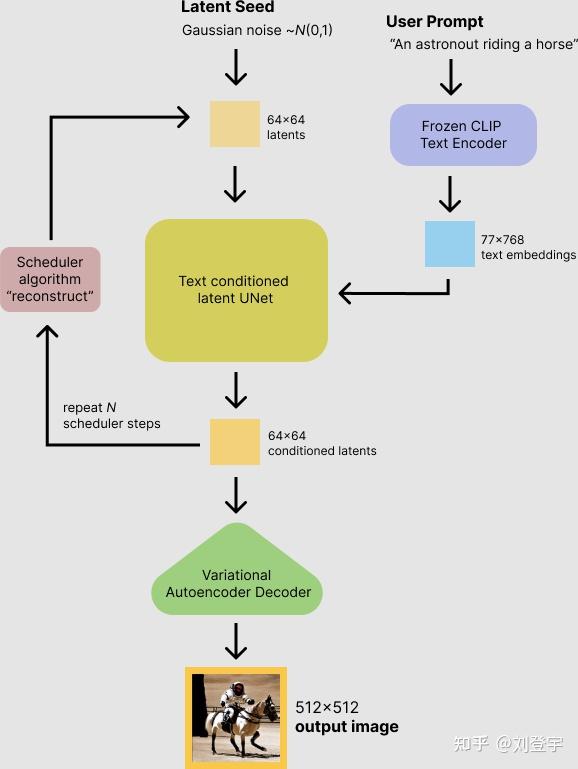 [2] [2]SD在潜空间生成随机的张量,你也可以设置种子(seed)来控制这个初始值,特定的初始值可以起到固定的作用。然后这个在潜在种子生成64 x 64的潜空间图像,Prompt通过CLIP转化77 x 768条件文本嵌入(embedding); U-net以这个嵌入为条件,对潜空间图像迭代降噪。U-net输出噪声的残差,通过调度器(scheduler)进行降噪计算并返回本轮的去噪样本,(而这个调度器也叫采样器或者求解器,对应了不同的算法,有各种优缺点); 在迭代50次后(取决于你选择的采样方法,有些20次迭代就可以达到高质量的结果),最后VAE的解码器把最终的潜空间图像转化输入到像素空间,即我们能看到的像素图片,整个工作流到此结束,你得到了结果图片。 这就stable diffusion的文生图大致工作原理。 采样方法(SD-Webui)Stable diffusion webui是Stable diffusion的GUI是将stable diffusion实现可视化的图像用户操作界面,它本身还集成了很多其它有用的扩展脚本。 webui中集成了很多不同的采样方法,(上述提到的调度算法)这块也是目前AI艺术家们乐忠对比的环节,这里结合设置中提供的选项,简单粗略的介绍下它们的各自区别。 这些大部分的采样器是由Katherine Crowson根据论文实现的功能,stable diffusion官方的blog也提到过她,她在github中有一个名为K-diffusion的项目[3],理论基础主要基于Jiaming Song等人的论文[4]、Karras等人的论文[5]以及前不久基于Cheng Lu等人的论文[6] 按照SD webui的顺序 Euler基于Karras论文,在K-diffusion实现,20-30steps就能生成效果不错的图片,采样器设置页面中的 sigma noise,sigma tmin和sigma churn这三个属性会影响到它(后面会提这三个参数的作用); Euler a使用了祖先采样(Ancestral sampling)的Euler方法,受采样器设置中的eta参数影响(后面详细介绍eta); LMS线性多步调度器(Linear multistep scheduler)源于K-diffusion的项目实现; heun基于Karras论文,在K-diffusion实现,受采样器设置页面中的 sigma参数影响; DPM2这个是Katherine Crowson在K-diffusion项目中自创的,灵感来源Karras论文中的DPM-Solver-2和算法2,受采样器设置页面中的 sigma参数影响; DPM2 a使用了祖先采样(Ancestral sampling)的DPM2方法,受采样器设置中的ETA参数影响; DPM++ 2S a基于Cheng Lu等人的论文(改进后,后面又发表了一篇),在K-diffusion实现的2阶单步并使用了祖先采样(Ancestral sampling)的方法,受采样器设置中的eta参数影响;Cheng Lu的github中也提供已经实现的代码,并且可以自定义,1、2、3阶,和单步多步的选择,webui使用的是K-diffusion中已经固定好的版本。对细节感兴趣的小伙伴可以参考Cheng Lu的github和原论文。 DPM++ 2M基于Cheng Lu等人的论文(改进后的版本),在K-diffusion实现的2阶多步采样方法,在Hagging face中Diffusers中被称作已知最强调度器,在速度和质量的平衡最好。这个代表M的多步比上面的S单步在采样时会参考更多步,而非当前步,所以能提供更好的质量。但也更复杂。 DPM++ SDE基于Cheng Lu等人的论文的,DPM++的SDE版本,即随机微分方程(stochastic differential equations),而DPM++原本是ODE的求解器即常微分方程(ordinary differential equations),在K-diffusion实现的版本,代码中调用了祖先采样(Ancestral sampling)方法,所以受采样器设置中的ETA参数影响; DPM fast基于Cheng Lu等人的论文,在K-diffusion实现的固定步长采样方法,用于steps小于20的情况,受采样器设置中的ETA参数影响; DPM adaptive基于Cheng Lu等人的论文,在K-diffusion实现的自适应步长采样方法,DPM-Solver-12 和 23,受采样器设置中的ETA参数影响; Karras后缀LMS Karras 基于Karras论文,运用了相关Karras的noise schedule的方法,可以算作是LMS使用Karras noise schedule的版本; DPM2 Karras,DPM2 a Karras,DPM++ 2S a Karras,DPM++ 2M Karras,DPM++ SDE Karras这些含有Karras名字的采样方法和上面LMS Karras意思相同,都是相当于使用Karras noise schedule的版本; DDIM“官方采样器”随latent diffusion的最初repository一起出现, 基于Jiaming Song等人的论文,也是目前最容易被当作对比对象的采样方法,它在采样器设置界面有自己的ETA; PLMS同样是元老,随latent diffusion的最初repository一起出现; UniPC最新被添加到webui中的采样器,基于Wenliang Zhao等人的论文[7],应该是目前最快最新的采样方法,10步就可以生成高质量结果;在采样器设置界面可以自定义的参数目前也比较多,因为只针对它,所以直接展开聊一下怎么设置,先参考下图 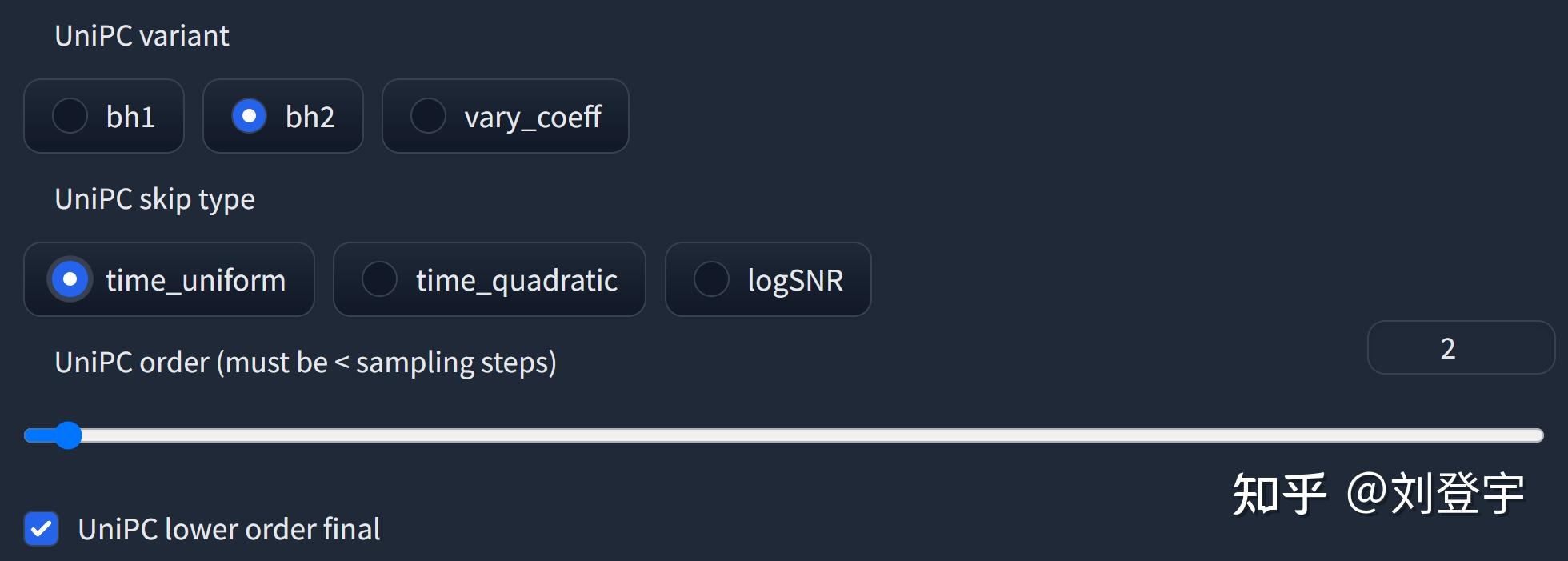 UniPC variant bh1和bh2和vary_coeff是三种变体 hugging face的团队在diffuser中给出了他们的建议:bh1适合在无条件(没指挥,无引导)且步数小于10情况下使用,其余情况全部使用bh2。 至于vary_coeff这个,作者在论文中实验对比了在“无条件”的和bh1和bh2的区别,即bh1在5,6步表现最好,vary_coeff在7,8或9表现最好,10步以上还是bh2。 由于我们在webui的使用场景使用提示词就是“有条件”了,所以看上去bh2更合适,除非你热衷于10步以内生成图片,但webui的github上有人反应vary_coeff生成的图片背景细节更加丰富[8]。我个人使用下来看,区别不算大,可以自己对比。 一句话总结:懒得对比的话就默认bh2。 UniPC skip type 如果你生成的图片是512 x 512或者更大的话,选uniform。它更适合高分辨率图(512目前相对算高分别率)logSNR适合低分别率 下图为logSNR(注意看某些步数的图片异常情况)  logSNR BH2 logSNR BH2logSNR在512 x 512下会出现一些奇怪的细节(模型SD1.5),quadratic稍微好一些(就不放图片了) 下图是uniform,请注意和上面相比细节的合理度。  uniform BH2 uniform BH2结论:512 x 512细节更合理, 推荐uniform 这个order最后两项都有提,作者在原论文也有对比,diffuser也有推荐:有条件(有引导)用2阶,无条件(无引导)用3阶,并且在在推理步数小于15时,打开lower order final,即在最后step使用低阶采样。 请看下图,在不开lower order final的情况下 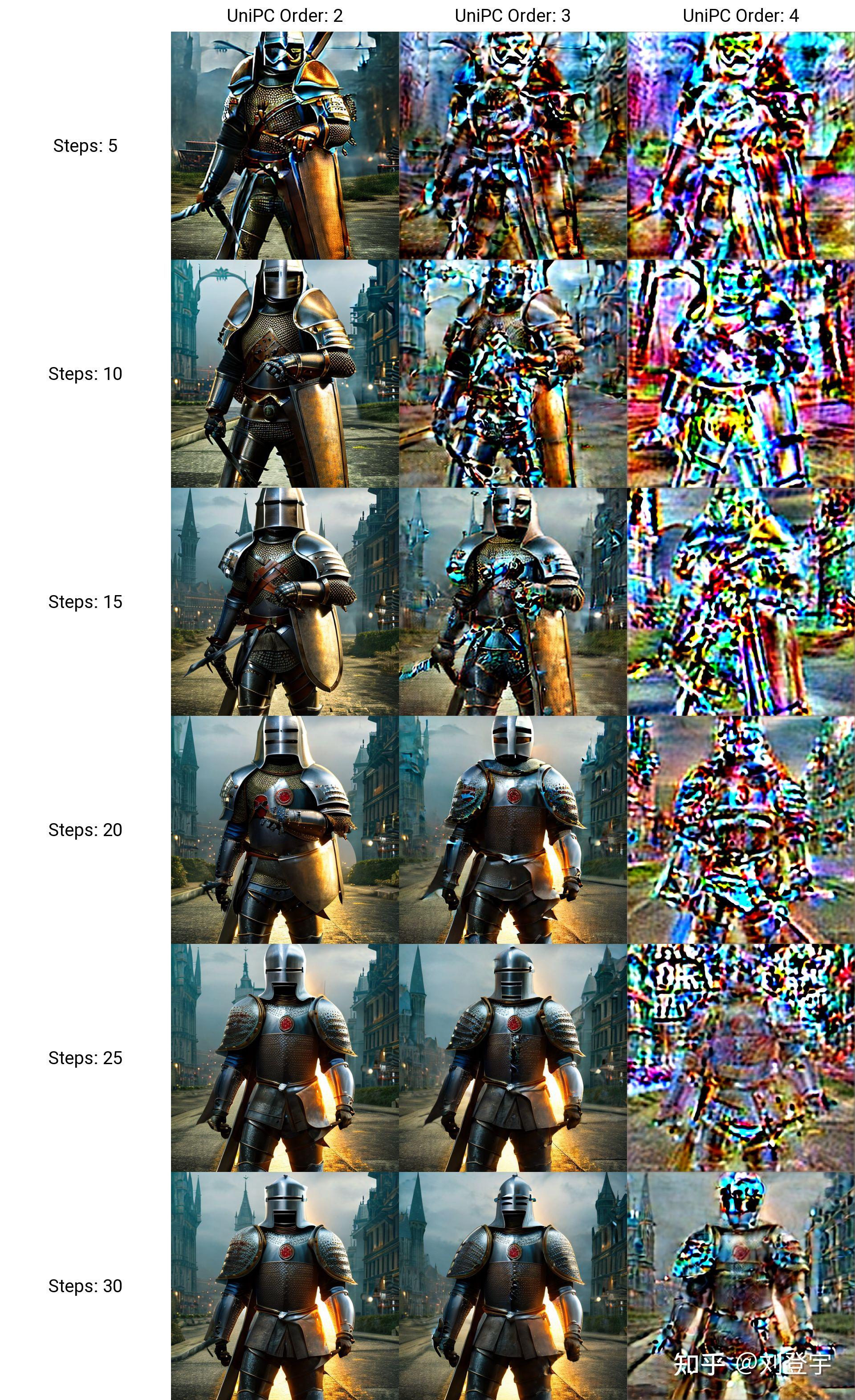 BH2,time_uniform BH2,time_uniform上面在UniPC skip type的对比环节都是开lower order final的情况下生成的。 结论:开lower order final,别犹豫,order我个人推荐2阶。 eta参数综合所有采样器,上面提到了eta eta (noise multiplier) for DDIM只作用DDIM,不为零时,DDIM在推理时图像会一直改变,生成的图像不会最终收敛; eta (noise multiplier) for ancestral samplers作用于名字后缀带a和SDE的所有采样器,不为零时,生成的图像也不会收敛; Eta noise seed delta也是seed值,在eta不为零时起到固定初始值,这样你就可以使用相同值还原某些其它人使用了对应eta值的图片。 请看下图(汇集了所有受eta参数影响的采样方法),在所有eta设定为1时的结果,盔甲的细节结构即使在高步数时也会改变  ETA for DDIM和ETA for a都为1 ETA for DDIM和ETA for a都为1 ETA for DDIM和ETA for a都为0 ETA for DDIM和ETA for a都为0eta为0,除了Euler a和DDIM还会有少量的变化外,其余带a的采样方法,带SDE的,以及DPM fast和DPM adaptive都会收敛稳定(上面的两张图片,除eta值,其余设置完全一样。) 再看下带a(祖先采样)的和原本的采样方式在不同的eta下的对比结果如下图: 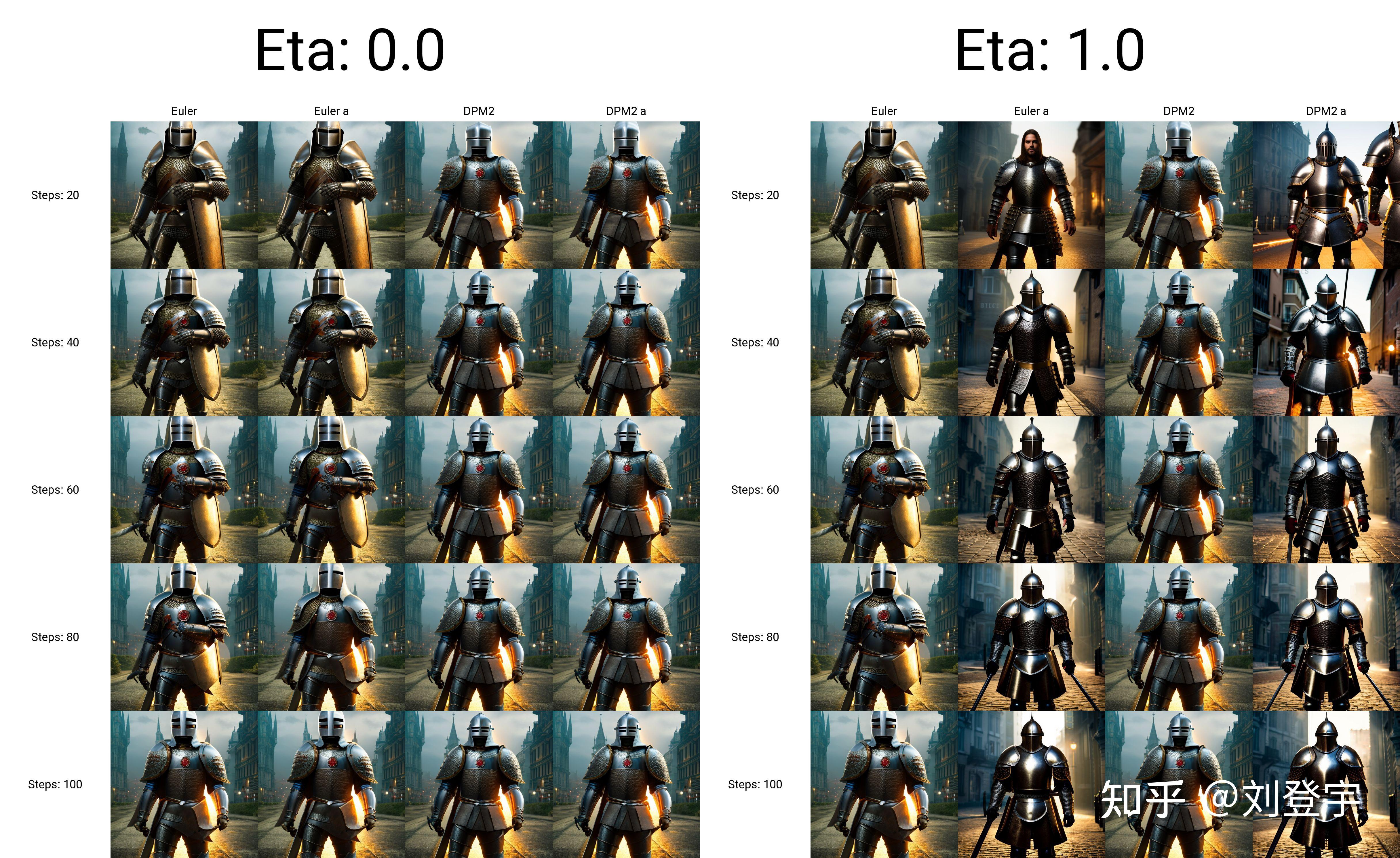 在eta为0时,带a和原始的采样方法生成的图片基本上相同了。 小结:使用上述图中采样方法时记得注意相应的eta,不然会失去所谓的的“多样性”和“想象力” sigma参数sigma包含:sigma churn,sigma tmin,sigma noise,仅对euler, heun和dpm2这三个采样器有效 sigma churn:决定sigma noise值如何被使用,如果churn值为0,即使noise值不为0,也没有任何效果。 sigma tmin:决定最小值范围的限制,可以为0 sigma noise:噪声本身的数值大小(注意,churn>0时,噪声值本身才有意义) 图片对比(图片中带a的采样方法不受sigma影响,所以作为对照组一同出现) 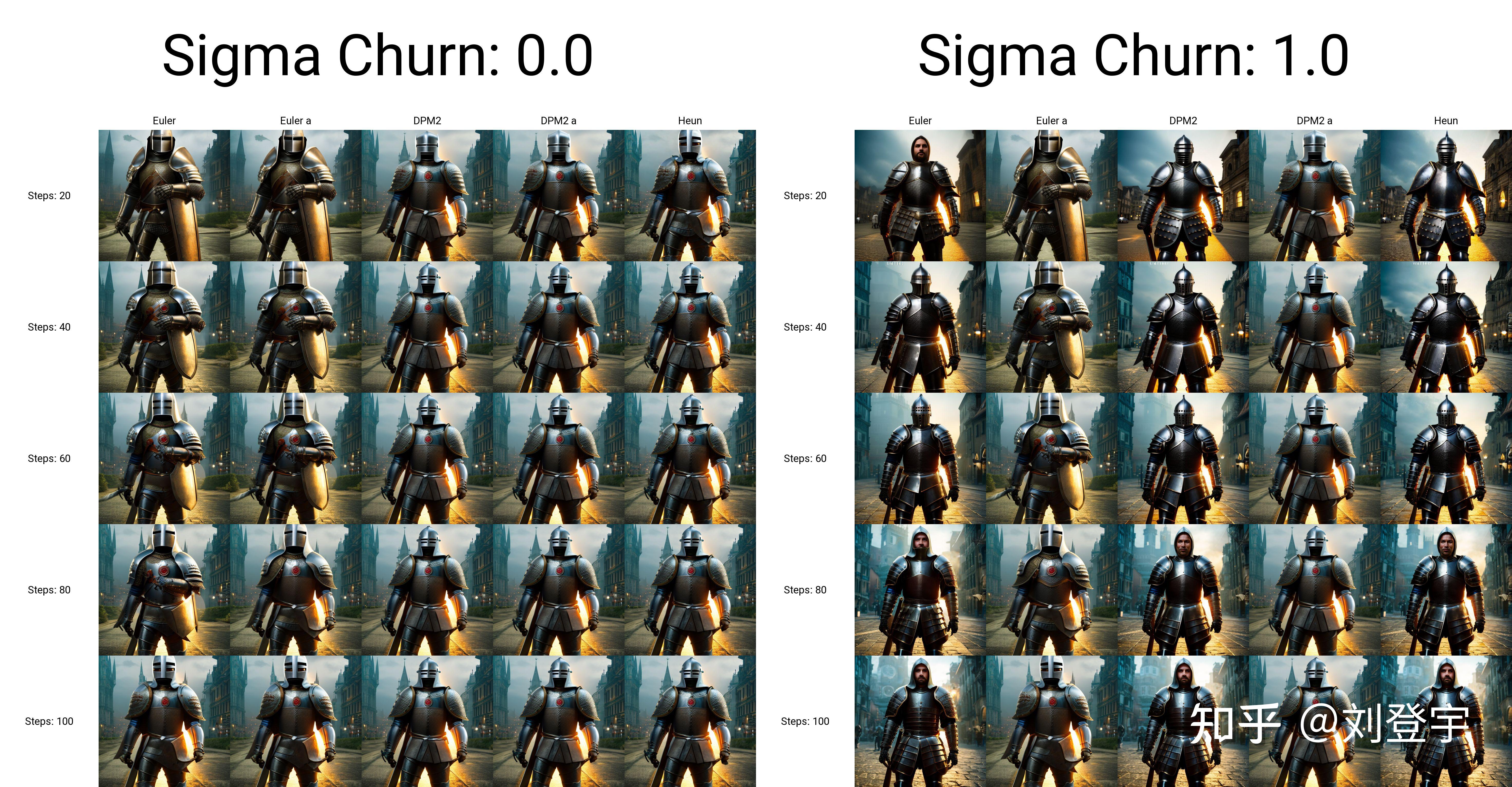 sigma值也是“多样性”或者“想象力”的相关数值。 采样方法小结1.建议根据自己使用的checkpoint使用脚本跑网格图(用自己关心的参数)然后选择自己想要的结果。 2.懒得对比:请使用DPM++ 2M或DPM++ 2M Karras或UniPC,想要点惊喜和变化,Euler a、DPM++ SDE、DPM++ SDE Karras、DPM2 a Karras(注意调正对应eta值) 3.eta和sigma都是多样性相关的,但是它们的多样性来自步数的变化,追求更大多样性的话应该关注seed的变化,这两项参数应该是在图片框架被选定后,再在此基础上做微调时使用的参数。 面部修复Face restoration下面我们看下面部修复  可以在设置界面选择:CodeFormer和GFPGAN都是面部修复的AI模型,可以修改权重值。 CodeFormer细节参考[9] GFPGAN细节参考[10] 这两个目前是风格有细微的区别,根据个人喜好选择。区别参考下图,来源:[11] 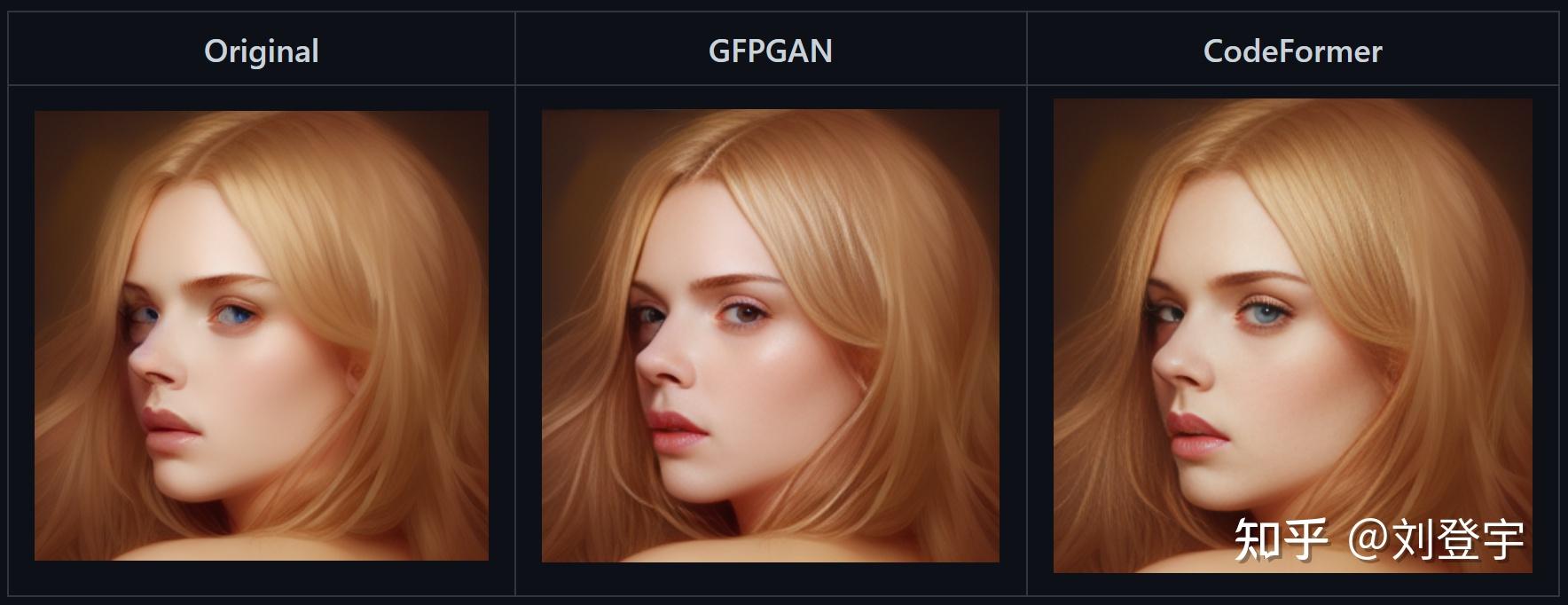 面部修复小结: 面部修复小结:根据个人喜好选择 超分辨率Hires.fix和Upscaler或者说图片放大器,在放大分辨率的同时根据AI模型添加相应的细节 在txt2img文生图中位于Hires. fix选项中的Upscaler Latent系列的放大器工作在潜空间(latent space)上文介绍基础工作原理时提到的那个降维空间。在Denoising强度低于0.5时会出现图片模糊等问题,高于0.5会显著解决问题,但是会改变原图更多的内容,失去之前的面貌。Denoising强度0.5以下请使用其它放大器。 其它非Latent系列的放大不工作在潜空间,所以就比较灵活了,txt2img和img2img都能使用。 Lanczos,Nearest 是比较老的传统算法,不是AI模型,不推荐使用。(接触过计算机图形学的话肯定知道这两个算法,经典算法肯定对后人的工作有启发作用。没有不尊重的意思)参考下图[12]  ESRGAN系列[13] ESRGAN系列[13]ESRGAN_4x适用于照片写实类(可能出现细节过于锐利的效果,但有些人喜欢这样的风格),R-ESRGAN 4x+(全能型),R-ESRGAN 4x+ Anime6B(适用于二次元),R-ESRGAN-General-WDN-4xV3(适用于厚涂插画) SwinIR_4x[14]SwinIR_4x需要表现光影的厚涂插画表现优于照片和二次元的图片放大,但逊于R-ESRGAN-General-WDN-4xV3 LDSRLDSR照片写实类图片表现很好,插画和二次元图片不行,而且体积很大,速度很慢(好奇的话,可以尝试) 超分模型小结:上面的这些超分模型并不是固定用于某一类风格的图片放大,你可以自行尝试。(个别除外,例如Anime6B) 懒得尝试可以按照这个来:照片类ESRGAN_4x,插画风R-ESRGAN-General-WDN-4xV3,二次元R-ESRGAN 4x+ Anime6B 更懒版本:照片类ESRGAN_4x,其余R-ESRGAN 4x+ 不想动版本:R-ESRGAN 4x+ seed和CFG Scale这两个设置使用过stable diffuion Webui应该都知道功能,暂时不展开。 Clip skip参数这个Clip skip设置被很多人说是玄学,记得上面聊三大组成部分的时候提到的Clip吗?调大Clip skip的数值会让Clip更早结束文本嵌入,让prompt提示的指挥力度被削弱,听上去是不是和CFG Scale唱反调?可能有人会问那都用CFG Scale不就好了吗?确实,平时你可以放着默认的设置不去管他,但是有些模型在训练时会调整这个Clip skip对层的影响深度,所以在使用的时候也需要相应的调整,比如设置为2,大多数我们口中的自己训练SD模型,其实都是对原本模型的微调,而实现微调的原理就是微调三大组件中的Clip或者调整Clip加U-net,说到本地模型训练,今后有时间再写吧。 参考^High-Resolution Image Synthesis with Latent Diffusion Models https://arxiv.org/abs/2112.10752^how-stable-diffusion-work https://huggingface.co/blog/stable_diffusion#how-does-stable-diffusion-work^k_diffusion/sampling https://github.com/crowsonkb/k-diffusion/blob/master/k_diffusion/sampling.py^Denoising Diffusion Implicit Models https://arxiv.org/abs/2010.02502^Elucidating the Design Space of Diffusion-Based Generative Models https://arxiv.org/abs/2206.00364^DPM-Solver: A Fast ODE Solver for Diffusion Probabilistic Model Sampling in Around 10 Steps https://arxiv.org/abs/2206.00927^UniPC: A Unified Predictor-Corrector Framework for Fast Sampling of Diffusion Models https://arxiv.org/abs/2302.04867^UniPC Sampler support https://github.com/easydiffusion/sdkit/pull/12^CodeFormer https://github.com/sczhou/CodeFormer^GFPGAN https://github.com/TencentARC/GFPGAN^Face restoration in webui https://github.com/AUTOMATIC1111/stable-diffusion-webui/wiki/Features#face-restoration^ai-upscaler https://stable-diffusion-art.com/ai-upscaler/^ESRGAN https://github.com/xinntao/Real-ESRGAN^SwinIR https://github.com/JingyunLiang/SwinIR |
【本文地址】