|
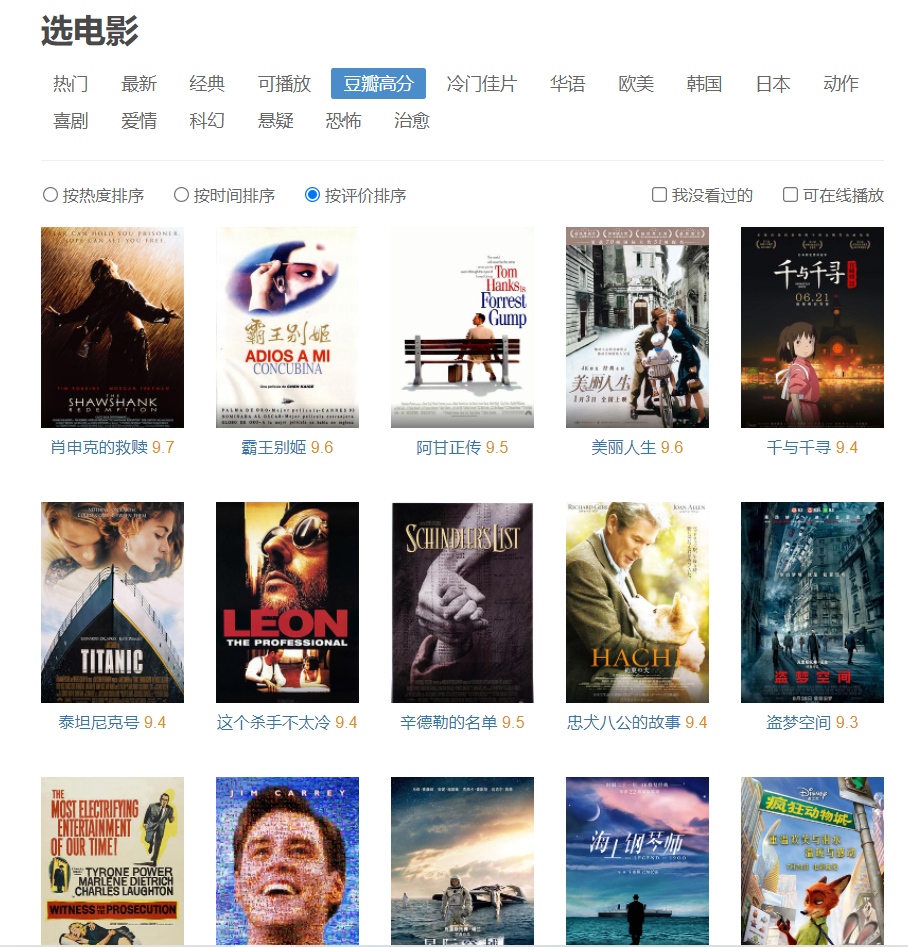
一、查看网页源码
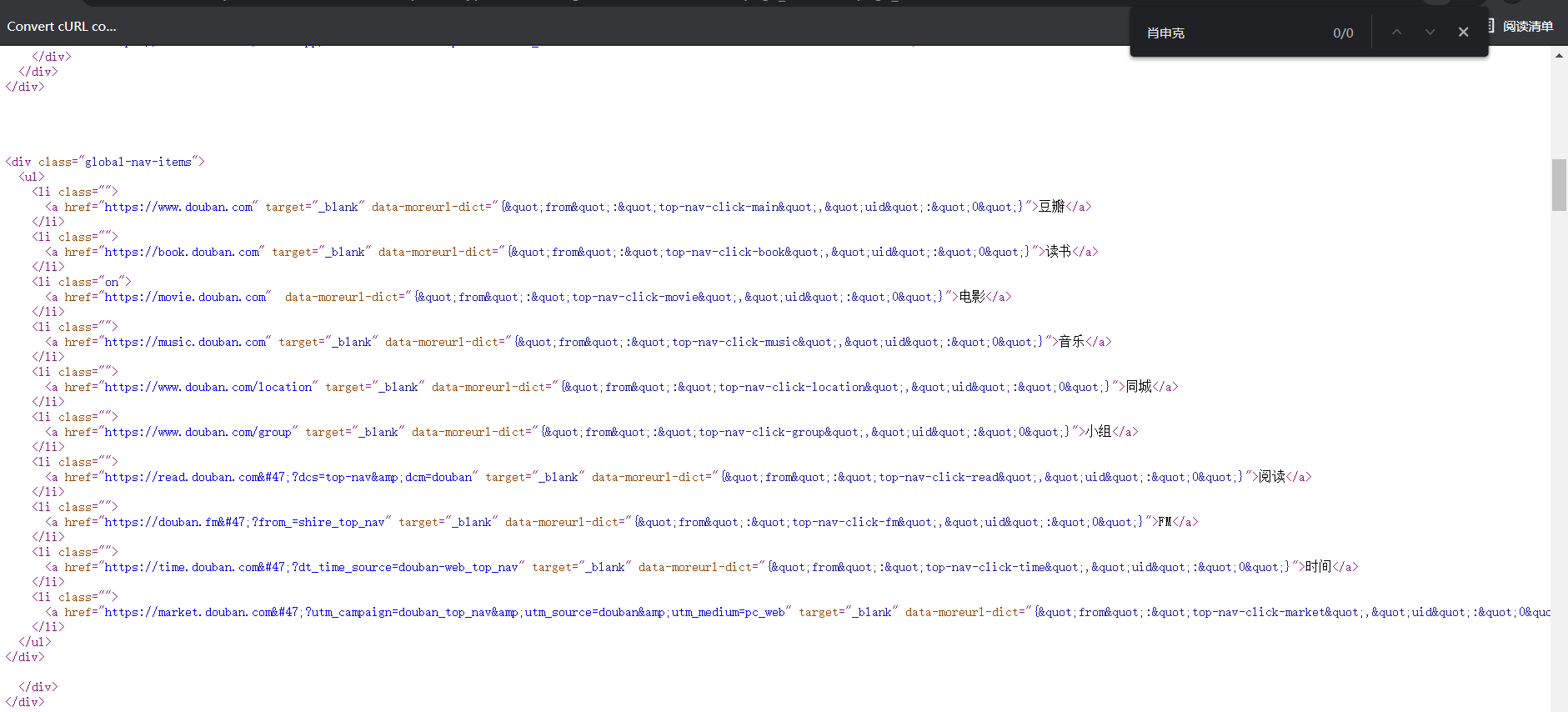 通过搜索我们可以发现网页源码中并没有我们想要抓取的内容 通过搜索我们可以发现网页源码中并没有我们想要抓取的内容
二、打开开发者工具(F12)
重新刷新下网页
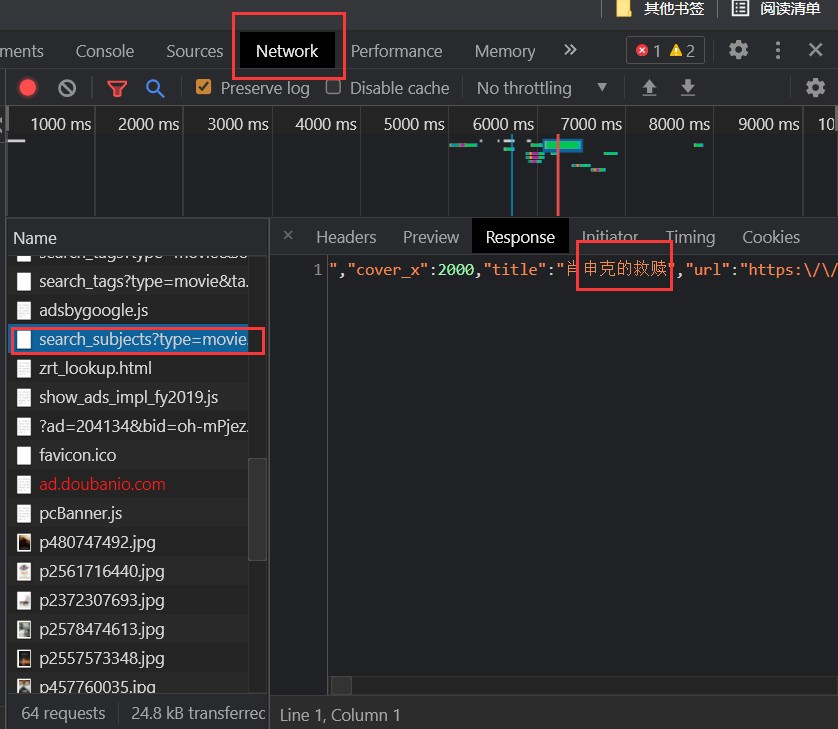 可能有人会要问刷新完有这么多数据这怎么找,我们可以通过搜索关键词来找 可能有人会要问刷新完有这么多数据这怎么找,我们可以通过搜索关键词来找
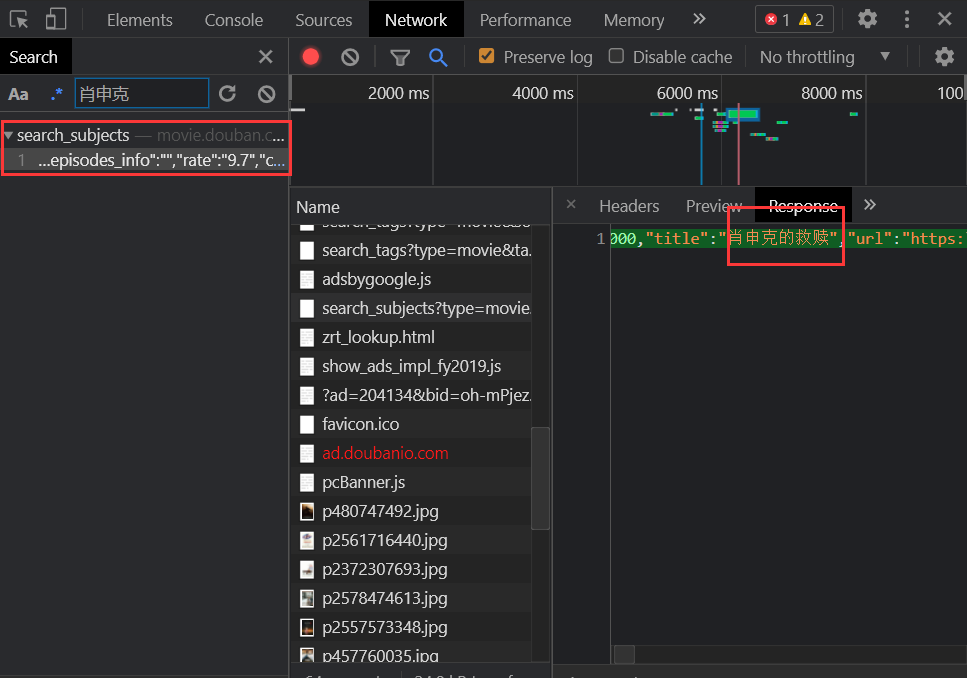 获取请求地址 获取请求地址 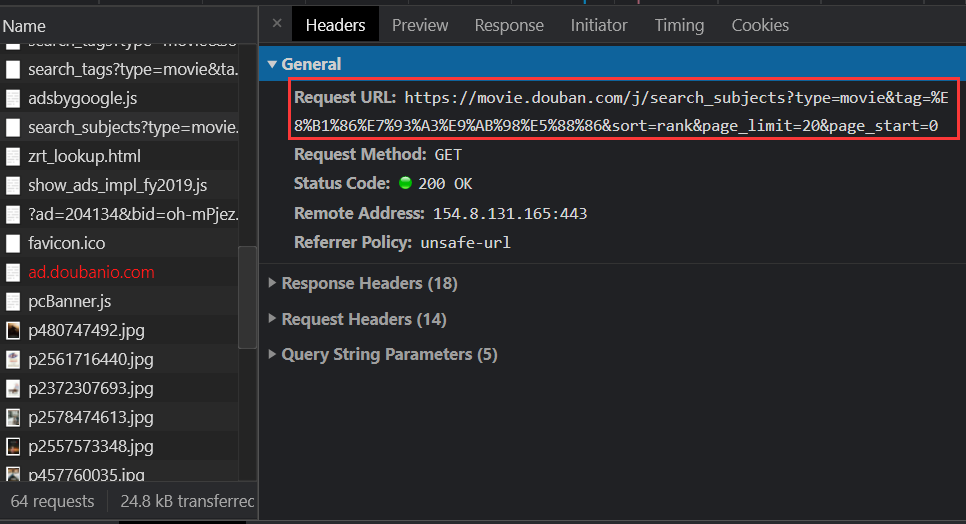
代码
获取数据
def url_parse():
url="https://movie.douban.com/j/search_subjects?type=movie&tag=%E8%B1%86%E7%93%A3%E9%AB%98%E5%88%86&sort=rank&page_limit=20&page_start=0"
headers={"User-Agent":UserAgent().random}
response=requests.get(url=url,headers=headers).json()
print(response)
return response
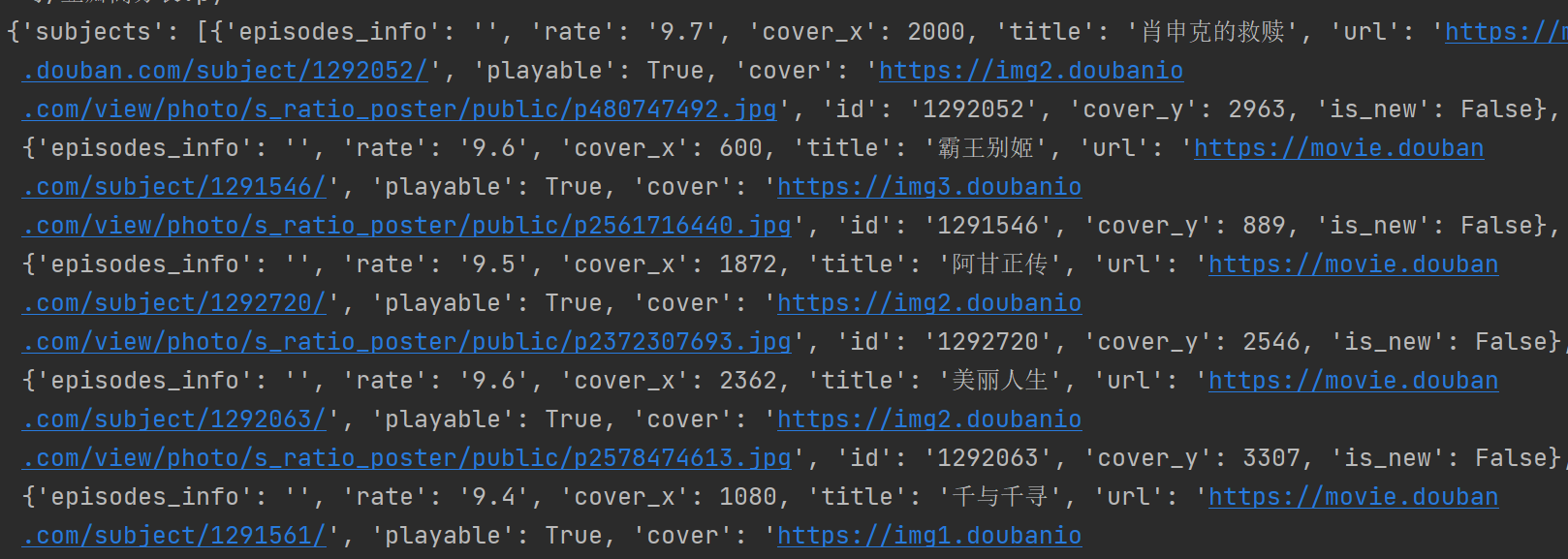
内容解析
def content_parse(res):
vedio_name=[]
vedio_rate=[]
content=res["subjects"]
for i in content:
name=i["title"]
rate=i["rate"]
vedio_name.append(name)
vedio_rate.append(float(rate))
print(name,rate)
return vedio_name ,vedio_rate
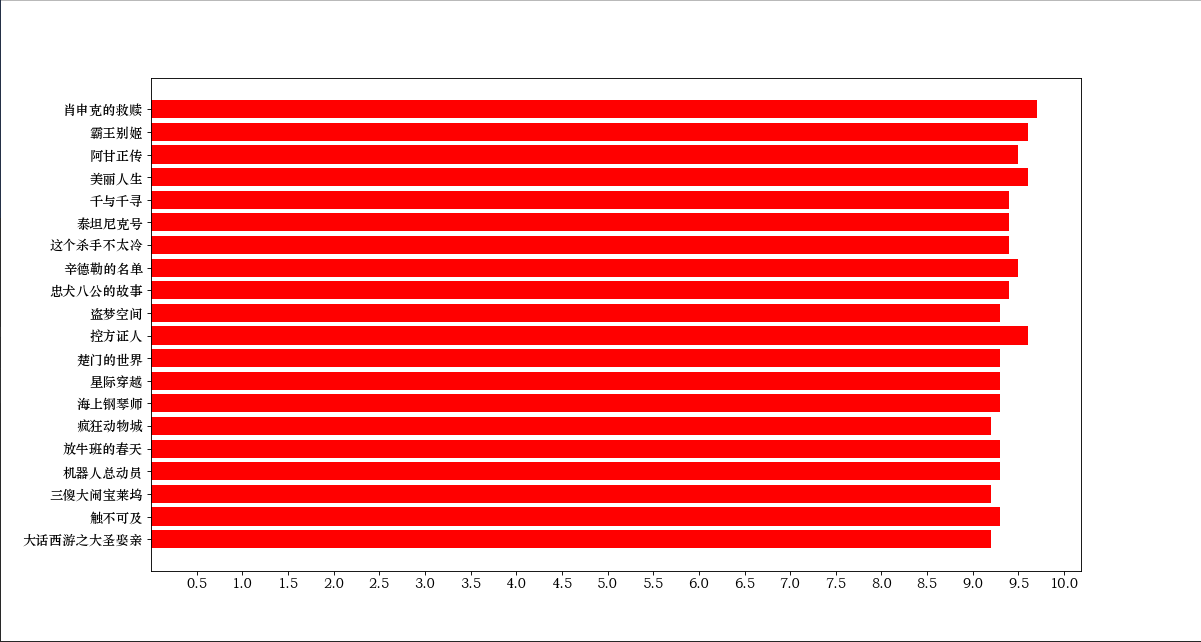
制作图表
def make_pic(name,rate):
fig=plt.figure(figsize=(15,8),dpi=80)
font=FontProperties(fname=r"STZHONGS.TTF",size=12)
plt.barh(name[::-1],rate[::-1],color="red")
x_=[i*0.5 for i in range(1,21)]
plt.xticks(x_,fontproperties=font)
plt.yticks(name,fontproperties=font)
plt.savefig("豆瓣.png")
plt.show()
完整代码
import requests
from fake_useragent import UserAgent
from matplotlib import pyplot as plt
from matplotlib.font_manager import FontProperties
#获取数据
def url_parse():
url="https://movie.douban.com/j/search_subjects?type=movie&tag=%E8%B1%86%E7%93%A3%E9%AB%98%E5%88%86&sort=rank&page_limit=20&page_start=0"
headers={"User-Agent":UserAgent().random}
response=requests.get(url=url,headers=headers).json()
#print(response)
return response
#处理内容
def content_parse(res):
vedio_name=[]
vedio_rate=[]
content=res["subjects"]
for i in content:
name=i["title"]
rate=i["rate"]
vedio_name.append(name)
vedio_rate.append(float(rate))
print(name,rate)
return vedio_name ,vedio_rate
#制作图表
# def make_pic(name,rate):
# fig=plt.figure(figsize=(15,8),dpi=80)
# font=FontProperties(fname=r"STZHONGS.TTF",size=12)
# plt.barh(name[::-1],rate[::-1],color="red")
# plt.xticks(fontproperties=font)
# plt.yticks(name,fontproperties=font)
# plt.savefig("豆瓣.png")
# plt.show()
#主函数
def main():
data=url_parse()
name,rate=content_parse(data)
# make_pic(name,rate)
if __name__ == '__main__':
main()
|