| 神经网络反向传播原理(作用,为什么要反向传播) | 您所在的位置:网站首页 › 什么是反向输出 › 神经网络反向传播原理(作用,为什么要反向传播) |
神经网络反向传播原理(作用,为什么要反向传播)
|
参考 这里给出关键的一句话: 反向传播就是为了实现最优化,省去了重复的求导步骤 背景在机器学习中,很多算法最后都会转化为求一个目标损失函数(loss function)的最小值。这个损失函数往往很复杂,难以求出最值的解析表达式。而梯度下降法正是为了解决这类问题。直观地说一下这个方法的思想:我们把求解损失函数最小值的过程看做“站在山坡某处去寻找山坡的最低点”。我们并不知道最低点的确切位置,“梯度下降”的策略是每次向“下坡路”的方向走一小步,经过长时间的走“下坡路”最后的停留位置也大概率在最低点附近。这个“下坡路的方向”我们选做是梯度方向的负方向,选这个方向是因为每个点的梯度负方向是在该点处函数下坡最陡的方向。至于为什么梯度负方向是函数下降最陡的方向请参考大一下的微积分教材,或者看看这个直观的解释。在神经网络模型中反向传播算法的作用就是要求出这个梯度值,从而后续用梯度下降去更新模型参数。反向传播算法从模型的输出层开始,利用函数求导的链式法则,逐层从后向前求出模型梯度,那么为什么要从后向前呢? 从一道编程题说起这是leetcode 上的一道编程题 ,这道题不是很难,读者可以自己先做一做。这个问题的原理跟反向传播算法有很大的相似。 这道题目是给出一个三角形的数组,从上到下找到一条路径使得这条路径上数字的和最小,并且路径层与层之间的节点左右需要相邻。详细的题目介绍请到leetcode上看一看。
将以上代码提交后发现Time Limit Exceeded 的超时错误,究其原因是这种从上到下的计算方式中存在大量的重复计算,如2图所示:将一个大的问题分解成两个子问题(红蓝两个三角形)时,这两个三角形之间有交叠,即图2中的紫色圈,这些交叠部分会导致重复计算,使得计算超时。图中仅仅是一个子问题的重复计算,实际上每一次子问题的分解都有这样的重复计算,因此整个问题的重复计算量非常的大。
上面的代码就能够通过测试,我们看到仅仅是改变计算方向就能有效地避免重复的计算,从而加快计算速度。理解了这个算法,我们再看反向传播算法需要“反向”的原因也就觉得理所当然了。 反向传播算法现在来讲反向传播算法,其目的就是要求神经网络模型的输出相对于各个参数的梯度值。以图3为例子讲解,图中输入向量x经过神经网络的输出为y,模型的参数为wi和bi,在输入值x为xi时,将模型的参数看做自变量,于是所谓的求梯度就是求出所有的∂y∂wi|x=xi和∂y∂bi|x=xi。这些导数要怎么求能?如果我不知道反向传播算法,我应该会用如下式子的近似求导方法:
即要求某个参数的导数就让这个参数微变一点点,然后求出结果相对于参数变化量的比值。那么为何我们的神经网络算法没有采用这种方法求导呢? 让我们再看一看图3的例子,现在假设输入向量经过正向传播后,现在要求出参数w1和w2的导数,按照上述方法计算时,对w1微扰后,需要重新计算红框内的节点;对w2微扰后,需要重新计算绿框内的节点。这两次计算中也有大量的“重复单元”即图中的蓝框,实际上神经网络的每一个参数的计算都包含着这样大量的重复单眼,那么神经网络规模一旦变大,这种算法的计算量一定爆炸,没有适用价值。我们再回过头去看我们的编程题,是否有一些似曾相识呢,尤其是图2和图3之间。
|
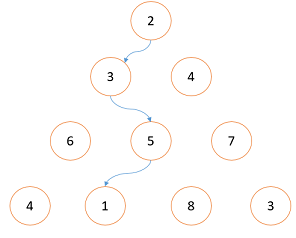 图1 图1中是一个具体的例子,最小和的路径如箭头所示,路径的和为11。最开始做这个题,我的想法是从上到下不断将问题分解成小问题去处理,具体来说上图的大三角形可以分解成3为顶点和4为顶点的两个小三角形,如图2所示,求出这两个子问题的最小路径,选择这两个路径和较小者加上顶点2的值就为整个问题的最小值,而对于每个分解的子问题,再故伎重演地继续分解来处理。具体的代码如下:
图1 图1中是一个具体的例子,最小和的路径如箭头所示,路径的和为11。最开始做这个题,我的想法是从上到下不断将问题分解成小问题去处理,具体来说上图的大三角形可以分解成3为顶点和4为顶点的两个小三角形,如图2所示,求出这两个子问题的最小路径,选择这两个路径和较小者加上顶点2的值就为整个问题的最小值,而对于每个分解的子问题,再故伎重演地继续分解来处理。具体的代码如下: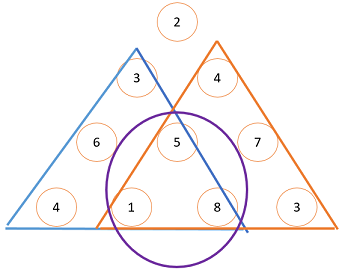 图2 实际上这个问题的正确解决方法是使用动态规划算法,动态规划要解决的正是这种包含重复子问题的情况。其实现方法一般分为两种,一种是将计算过的子问题都缓存起来,当遇到了相同的问题就直接取出缓存的值,避免重复计算;另一种是方式是换一个“计算方向”(或者说计算的先后次序),使得在这个计算方向上没有重复的子问题。对于上述编程题我们的解法就是将这一算法换一个计算方向,由从上到下变换为从下到上。从最底层开始由下到上计算以当前点为顶点的“三角形”最小路径值,下层的顶点先计算,上层可以利用下层的计算结果,这就避免了重复计算。具体代码如下:
图2 实际上这个问题的正确解决方法是使用动态规划算法,动态规划要解决的正是这种包含重复子问题的情况。其实现方法一般分为两种,一种是将计算过的子问题都缓存起来,当遇到了相同的问题就直接取出缓存的值,避免重复计算;另一种是方式是换一个“计算方向”(或者说计算的先后次序),使得在这个计算方向上没有重复的子问题。对于上述编程题我们的解法就是将这一算法换一个计算方向,由从上到下变换为从下到上。从最底层开始由下到上计算以当前点为顶点的“三角形”最小路径值,下层的顶点先计算,上层可以利用下层的计算结果,这就避免了重复计算。具体代码如下: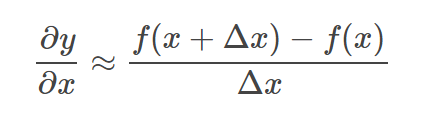
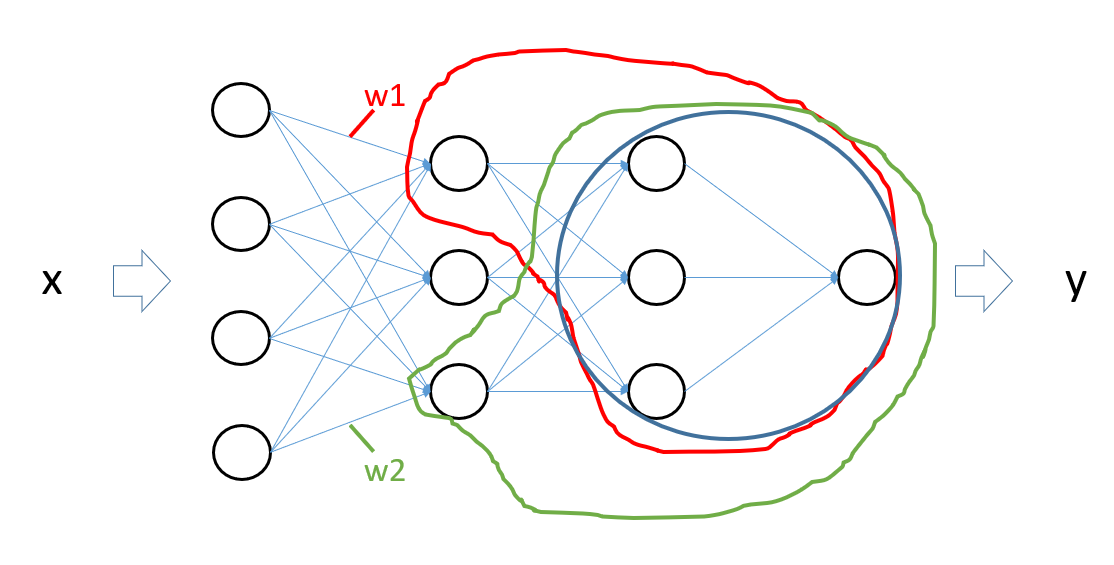 图3 在解决上述编程题时,我们选了一条相反的计算线路解决重复计算的问题。在神经网络中,那些牛逼的大神同样选择了另一条计算方向去计算梯度,这个方向就是从后向前“反向”地计算各层参数的梯度。这里不详细讨论方向传播算法的原理了,简单来说这种方法利用了函数求导的链式法则,从输出层到输入层逐层计算模型参数的梯度值,只要模型中每个计算都能求导,那么这种方法就没问题。可以看到按照这个方向计算梯度,各个神经单元只计算了一次,没有重复计算。这个计算方向能够高效的根本原因是,在计算梯度时前面的单元是依赖后面的单元的计算,而“从后向前”的计算顺序正好“解耦”了这种依赖关系,先算后面的单元,并且记住后面单元的梯度值,计算前面单元之就能充分利用已经计算出来的结果,避免了重复计算。
图3 在解决上述编程题时,我们选了一条相反的计算线路解决重复计算的问题。在神经网络中,那些牛逼的大神同样选择了另一条计算方向去计算梯度,这个方向就是从后向前“反向”地计算各层参数的梯度。这里不详细讨论方向传播算法的原理了,简单来说这种方法利用了函数求导的链式法则,从输出层到输入层逐层计算模型参数的梯度值,只要模型中每个计算都能求导,那么这种方法就没问题。可以看到按照这个方向计算梯度,各个神经单元只计算了一次,没有重复计算。这个计算方向能够高效的根本原因是,在计算梯度时前面的单元是依赖后面的单元的计算,而“从后向前”的计算顺序正好“解耦”了这种依赖关系,先算后面的单元,并且记住后面单元的梯度值,计算前面单元之就能充分利用已经计算出来的结果,避免了重复计算。【本文地址】