| MobileNet系列(万文长字详细讲解,一篇足以) | 您所在的位置:网站首页 › yolov3v4v5的主干网络都采用了mobilenet › MobileNet系列(万文长字详细讲解,一篇足以) |
MobileNet系列(万文长字详细讲解,一篇足以)
|
前言
本篇讲一下CV相关的东西,MobileNet,想必大家已经很熟悉了,包括里面的一些模块,一些轻量型思想也是经常用到的。在这里我也是想着做一下总结,整理一下,也讲一讲自己的理解和看法。卷积神经网络CNN已经普遍应用在计算机视觉领域,并且已经取得了不错的效果。近年来CNN模型深度越来越深,模型复杂度也越来越高,如深度残差网络(ResNet)其层数已经多达152层。然而,在某些真实的应用场景如移动或者嵌入式设备,如此大而复杂的模型时难以被应用的。首先是模型过于庞大,面临着内存不足的问题,其次这些场景要求低延迟,或者说响应速度要快,想象一下自动驾驶汽车的行人检测系统如果速度很慢会发生什么可怕的事情。所以,研究小而高效的CNN模型在这些场景至关重要,至少目前是这样,尽管未来硬件也会越来越快。 目前的研究总结来看分为两个方向: 一是对训练好的复杂模型进行压缩得到小模型; 二是直接设计小模型并进行训练。不管如何,其目标在保持模型性能(accuracy)的前提下降低模型大小(parameters size),同时提升模型速度(speed, low latency)。本文的主角MobileNet属于后者,其是Google最近提出的一种小巧而高效的CNN模型,其在accuracy和latency之间做了折中。 一、MobileNet V1详解在V1中主要创新点是将普通卷积换成了深度可分离卷积,并引入了两个超参数使得可以根据资源来更加灵活的控制自己模型的大小。 那什么是深度分离卷积(Depthwise separable convolution)呢? 根据史料记载,可追溯到2012年的论文Simplifying ConvNets for Fast Learning,作者提出了可分离卷积的概念:
Laurent Sifre博士2013年在谷歌实习期间,将可分离卷积拓展到了深度(depth),并且在他的博士论文Rigid-motion scattering for image classification中有详细的描写,感兴趣的同学可以去看看论文。其中可分离卷积主要有两种类型:空间可分离卷积和深度可分离卷积。 空间可分离卷积顾名思义,空间可分离就是将一个大的卷积核变成两个小的卷积核,比如将一个3*3的核分成一个3*1 和一个 1*3 的核:
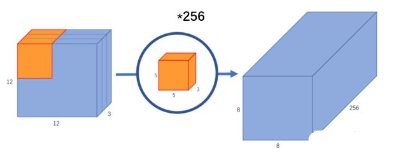
因为MobileNet并没有用到这块,所以在这里就不详细的讲了。 深度可分离卷积深度级可分离卷积其实是一种可分解卷积操作(factorized convolutions)。其可以分解为两个更小的操作:深度卷积(depthwise convolution) 和点卷积( pointwise convolution)。 对于一个标准卷积,输入一个12*12*3的一个输入特征图,经过 5*5*3的卷积核得到一个8*8*1的输出特征图。如果我们此时有256个特征图,我们将会得到一个8*8*256的输出特征图,如下图所示:
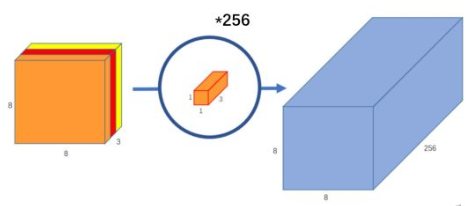
对于深度卷积(其实就是组为1 的分组卷积)来说,将特征图通道全部进行分解,每个特征图都是单通道模式,并对每一个单独的通道特征图进行卷积操作。这样就会得到和原特征图一样通道数的生成特征图。假设输入12*12*3 的特征图,经过5*5*1*3的深度卷积之后,得到了8*8*3的输出特征图。输入和输出的维度是不变的3,这样就会有一个问题,通道数太少,特征图的维度太少,不能够有效的获得信息。
逐点卷积就是1*1卷积,主要作用就是对特征图进行升维和降维。在深度卷积的过程中,我们得到了8*8*3的输出特征图,我们用256个1*1*3的卷积核对输入特征图进行卷积操作,输出的特征图和标准的卷积操作一样都是8*8*256了。如下图:
标准卷积与深度可分离卷积的过程对比如下: |

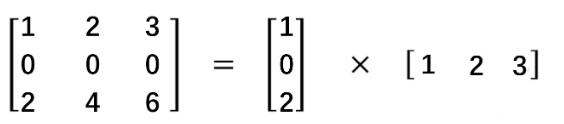

【本文地址】