| 爬取华尔街日报的历史数据并翻译 | 您所在的位置:网站首页 › wsj数据集 › 爬取华尔街日报的历史数据并翻译 |
爬取华尔街日报的历史数据并翻译
|
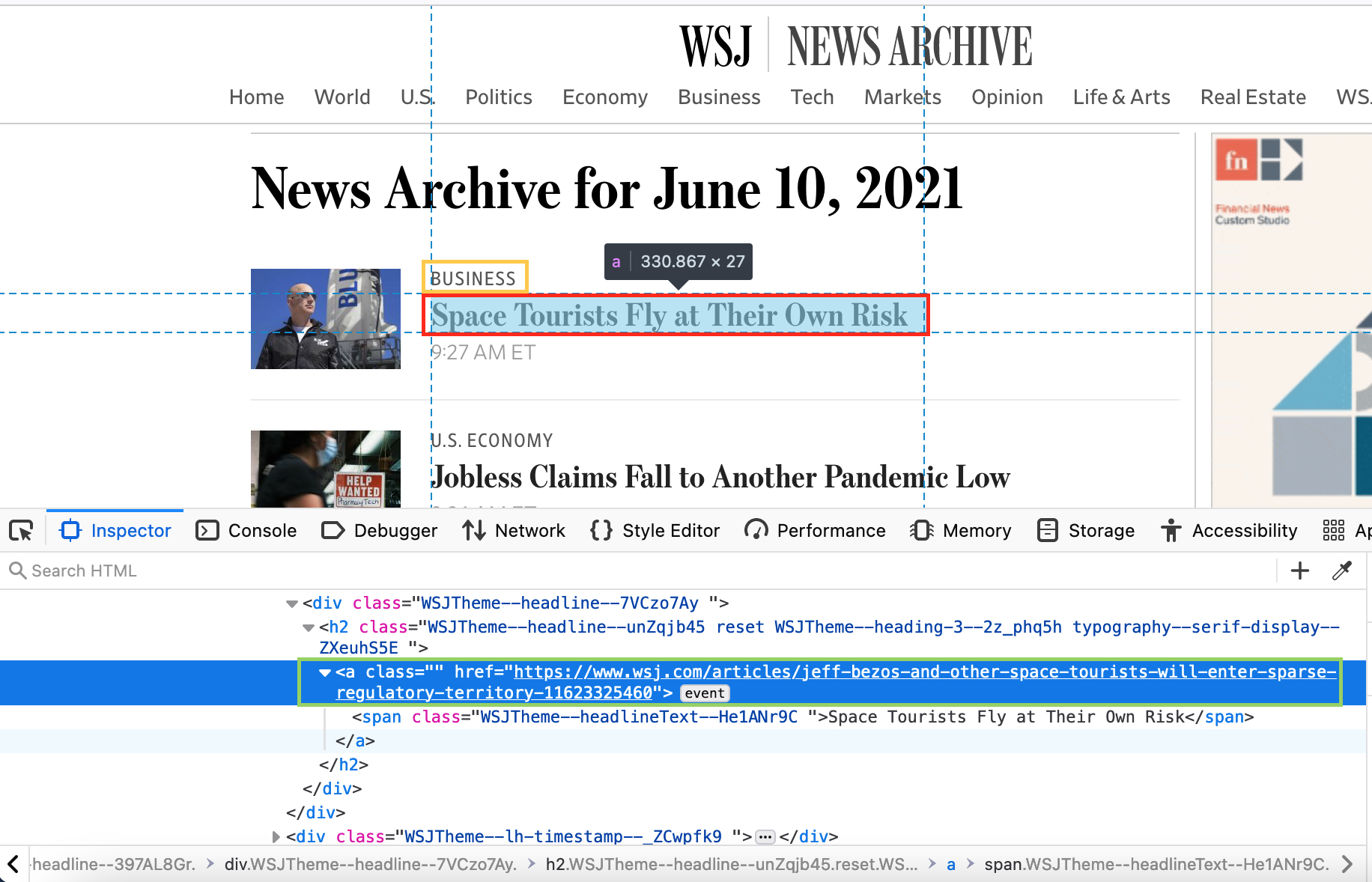
最近搭了个人网站,版面更好看些,地址在 https://mengjiexu.com/ 文章目录 获取 Cookies获取文章列表网页分析代码文章列表文章年份分布文章主题分布 爬取文章内容分析网页爬取文章代码爬取文章样例 翻译翻译文章代码翻译文章样例 参考文献从读论文和写论文的体验来看,传闻证据 (anecdotes) 对论文能不能给人可靠的第一印象有决定性作用。传闻证据到位了,就不会有人追着问一些澄清性问题 (clarification questions),后面论证研究题目的重要性时也会顺利很多 (why care)。此外,很多时候传闻证据对作者本人更好地了解研究背景 (institutional background) 并提出合情合理的研究设计也有很大的帮助作用1。 据我所知,华尔街日报 (Wall Street Journal) 给很多顶刊论文提供了灵感。比如 Zhu (2019 RFS) 与 用停车场数据预测零售公司业绩的报道非常相关 (2014.11.20 WSJ), 一篇关于对冲基金经理与大数据的报道 (2013.12.18 WSJ) 则提出了 Katona et al. (2018 WP, MS R&R) 和 Mukherjee et al. (2021 JFE) 的主要论点。 所以我最近写论文的时候爬了华尔街日报的所有历史数据,源网址是 WSJ Archives,事实证明这个工作在我最近的论文展示中起到了相当正面的作用2。 获取 Cookies按照惯例,还是先获取 Cookies。首先登陆,登陆后等待大概20秒左右会跳出一个小框,要求接受 cookies,需要点击 YES, I AGREE, 经过这步操作的 Cookies 才能顺利获取文章列表或文章内容,否则会被网站识别为爬虫。 另外, Cookies 有失效时间 (expiry time),最好每次爬之前都更新下 Cookies。 from selenium import webdriver import time import json option = webdriver.FirefoxOptions() option.add_argument('-headless') driver = webdriver.Firefox(executable_path='/Users/mengjiexu/Dropbox/Pythoncodes/Bleier/geckodriver') # 填入 WSJ 账户信息 email = 'username' pw = 'password' def login(email, pw): driver.get( "https://sso.accounts.dowjones.com/login?") # 为了不透露个人信息,需要读者自己粘贴登陆界面的 url time.sleep(5) driver.find_element_by_xpath("//div/input[@name = 'username']").send_keys(email) driver.find_element_by_xpath("//div/input[@name = 'password']").send_keys(pw) driver.find_element_by_xpath("//div/button[@type = 'submit']").click() # 登陆 login(email, pw) time.sleep(20) # 切换到跳出的小框 driver.switch_to_frame("sp_message_iframe_490357") # 点击接受收集 Cookies driver.find_element_by_xpath("//button[@title='YES, I AGREE']").click() time.sleep(5) # 将 Cookies 写入文件 orcookies = driver.get_cookies() print(orcookies) cookies = {} for item in orcookies: cookies[item['name']] = item['value'] with open("wsjcookies.txt", "w") as f: f.write(json.dumps(cookies)) 获取文章列表 网页分析WSJ 每日文章列表 url 的命名方式十分简单,由以下两部分组成: https://www.wsj.com/news/archive/年/月/日所以在指定时间范围内遍历每一天即可得到每一天的文章列表。不过我爬的时候顺手爬了所有的日期列表,所以代码中直接遍历了日期列表。 WSJ Daylist: 链接: https://pan.baidu.com/s/1kPYlot5lmYtQwWlHxA6OpQ 密码: 0b44 以 2021 年 6 月 10 日的文章列表为例 (如下图),对于每一篇文章,主要关注四个变量: 文章所属板块 - 黄色框文章标题 - 红色框文章链接 - 绿色框文章日期 - 前定很多日期的文章列表都不止一页,所以需要: 判断翻页条件:详见代码中 pagenation(page) 函数如果满足翻页条件,进行翻页:newdaylink = daylink + "?page=%s"%pagenum
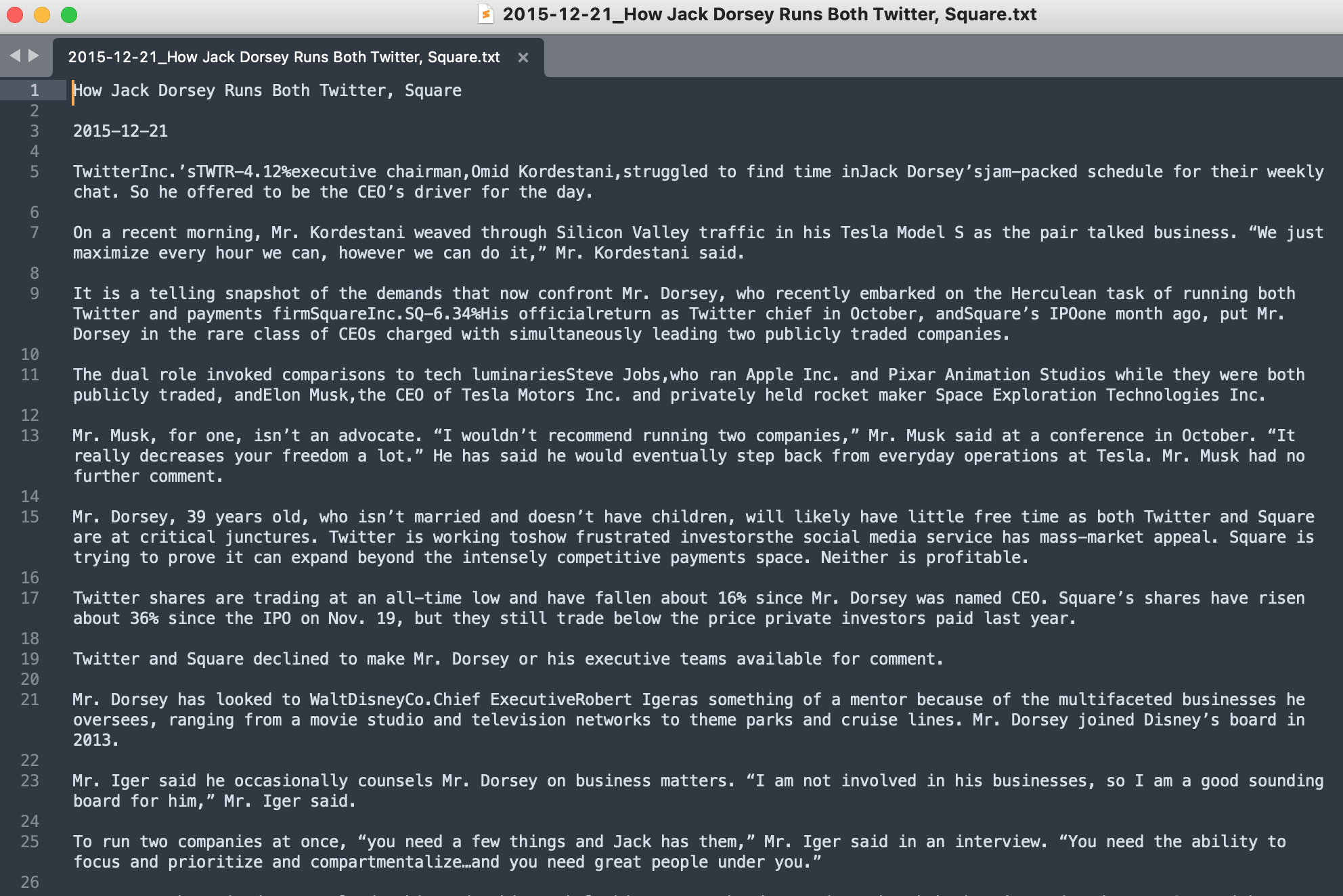
排除空白主题,1997-2021年共有 5822 个不同的主题。这里列出使用次数超出 10,000 的主题。 SectorArticleNumBusiness60119Markets34663U.S.23402Heard on the Street23340Major Business News22598Letters21531Politics20991Tech Center18511Earnings18178Technology17346U.S. Business News17109Europe15134Economy14432Photos14290Review & Outlook13759Business and Finance - Europe13530Commentary13428Health12979Business and Finance - Asia12723Asia11163Bookshelf11128World10833Media & Marketing10629Asian Business News10428Commodities10159Tech10153主题中包含中国的文章有 SectorArticleNumChina 20081China 20091Snow in China1China Stocks1China’s Changing Workforce1China’s Money Trail2China’s Rising Risks4China: The People’s Republic at 5012My China12China Trade Breakthrough19China’s World79China Circuit86Chinas World127China News1101China1875Total3322 爬取文章内容 分析网页从网页中获取所有文字信息并不难,但是 WSJ 文章会在文章中插入超链接,如果不做处理的话,爬下来的文字会有很多不符合阅读习惯的换行。我做的处理有: 使用函数 translist(infolist) 筛掉不必要的空格和换行没有采用直接获取符合条件 html element 下的所有文字的方法,而是对每个 element 进行遍历进行更加精细的筛选。这样做的速度稍微慢一点,但是基本上能呈现比较好的视觉呈现效果 爬取文章代码 import time from lxml import etree import csv import re from tqdm import tqdm import requests import json import pandas as pd import csv import unicodedata from string import punctuation df = pd.read_excel("/Users/mengjiexu/Dropbox/wsj0512/wsj0513.xlsx",header=0) headers = {'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10.15; rv:88.0) Gecko/20100101 Firefox/88.0', "content-type": "application/json; charset=UTF-8", "Connection": "keep-alive" } def translist(infolist): out = list(filter(lambda s: s and (type(s) != str or len(s.strip()) > 0), [i.strip() for i in infolist])) return(out) def parsearticle(title, date, articlelink): with open("wsjcookies.txt", "r")as f: cookies = f.read() cookies = json.loads(cookies) session = requests.session() data = session.get(articlelink, headers=headers, cookies = cookies) time.sleep(1) page = etree.HTML(data.content) arcontent = title + '\n\n' + date +'\n\n' content = page.xpath("//div[@class='article-content ']//p") for element in content: subelement = etree.tostring(element).decode() subpage = etree.HTML(subelement) tree = subpage.xpath('//text()') line = ''.join(translist(tree)).replace('\n','').replace('\t','').replace(' ','').strip()+'\n\n' arcontent += line return(arcontent) for row in tqdm(df.iterrows()): title = row[1][0].replace('/','-') articlelink = row[1][2] date = row[1][3].replace('/','-') arcontent = parsearticle(title, date, articlelink) with open("/Users/mengjiexu/Dropbox/articles/%s_%s.txt"%(date,title),'w') as g: g.write(''.join(arcontent)) 爬取文章样例
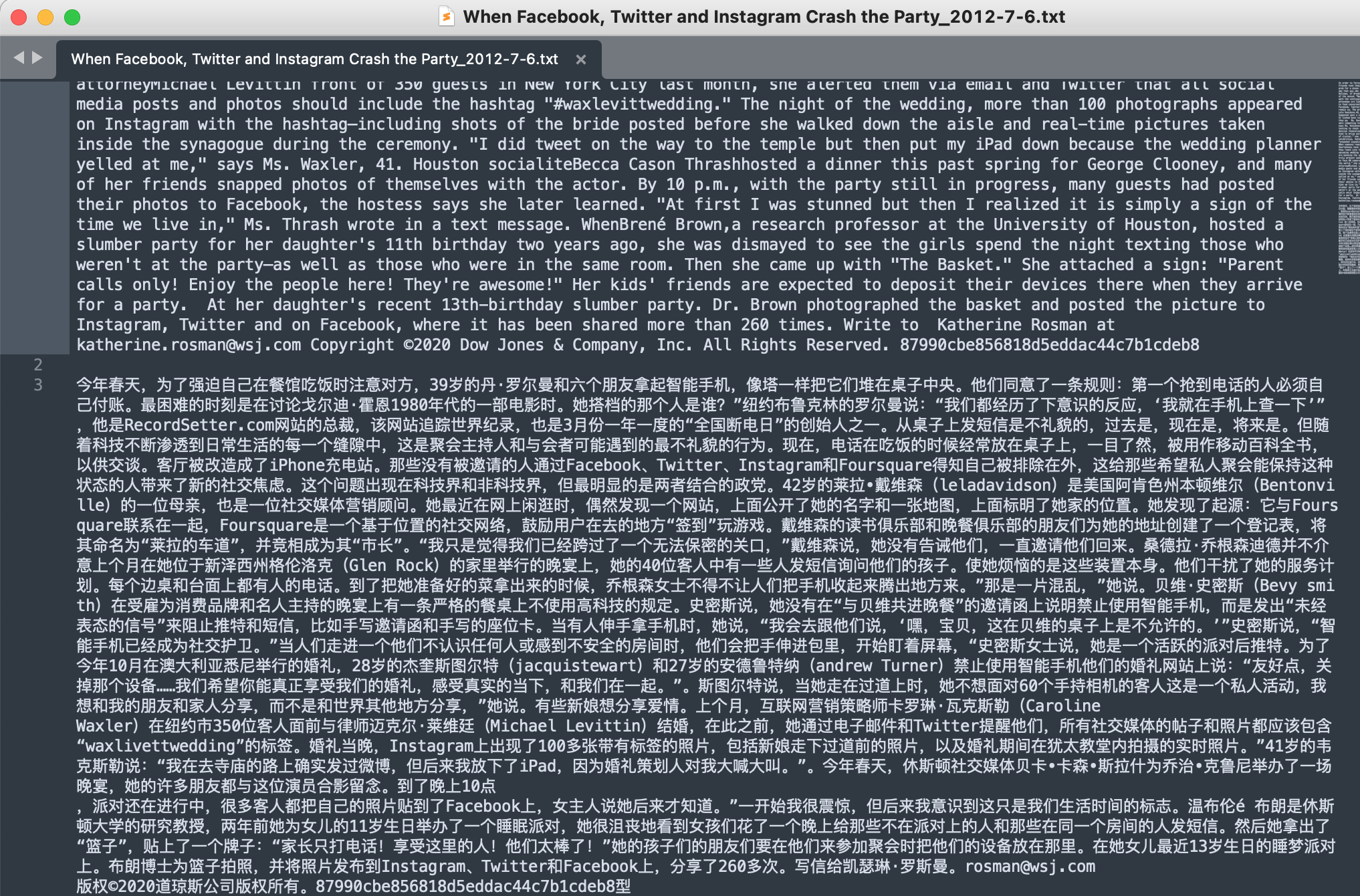
英语阅读速度比较慢的朋友可以调用 百度 API 对文章进行翻译,这样可以一目十行快速提取大量文章信息。为了提高翻译速度,最好整篇文章作为一个文字整体翻译。 翻译文章代码 import os import requests import random import json from hashlib import md5 from tqdm import tqdm file_list = os.listdir("/Users/mengjiexu/Dropbox/articles/") # Set your own appid/appkey. appid = 'xxx' appkey = 'xxx' # For list of language codes, please refer to `https://api.fanyi.baidu.com/doc/21` from_lang = 'en' to_lang = 'zh' endpoint = 'http://api.fanyi.baidu.com' path = '/api/trans/vip/translate' url = endpoint + path # Generate salt and sign def make_md5(s, encoding='utf-8'): return md5(s.encode(encoding)).hexdigest() salt = random.randint(32768, 65536) headers = {'Content-Type': 'application/x-www-form-urlencoded'} def trans(query): sign = make_md5(appid + query + str(salt) + appkey) # Build request payload = {'appid': appid, 'q': query, 'from': from_lang, 'to': to_lang, 'salt': salt, 'sign': sign} # Send request r = requests.post(url, params=payload, headers=headers) result = r.json() # Show response rusult = json.dumps(result, indent=4, ensure_ascii=False) return(result["trans_result"][0]["dst"]) for file in tqdm(file_list): content =open("/Users/mengjiexu/Dropbox/articles/%s"%file, 'r').read() print(trans(content.strip())) 翻译文章样例
Zhu, Christina. 2019. “Big Data as a Governance Mechanism.” The Review of Financial Studies 32 (5): 2021–61. https://doi.org/10.1093/rfs/hhy081. Katona, Zsolt, Marcus Painter, Panos N. Patatoukas, and Jean Zeng. 2018. “On the Capital Market Consequences of Alternative Data: Evidence from Outer Space.” SSRN Scholarly Paper ID 3222741. Rochester, NY: Social Science Research Network. https://doi.org/10.2139/ssrn.3222741. Mukherjee, Abhiroop, George Panayotov, and Janghoon Shon. 2021. “Eye in the Sky: Private Satellites and Government Macro Data.” Journal of Financial Economics, March. https://doi.org/10.1016/j.jfineco.2021.03.002. 写上对应的英语表达是确保读者理解的意思和我表达的意思不出现偏差而做的一个双重解释。 ↩︎ 获取 WSJ Archive 信息需要购买 WSJ 账号,本文只做交流学习使用,不建议使用本文内容获利。 ↩︎ |

【本文地址】