|
资源来源于网上。 像许多奢侈品一样,帆船的价值会随着时间和市场条件的变化而有所不同。附加的“2023_MCM_Problem_Y_Boats.xlsx”文件包括了有关欧洲、加勒比海和美国在2020年12月出售的36至56英尺长的大约3500艘帆船的数据。一位热爱帆船的人向COMAP提供了这些数据。像大多数现实世界的数据集一样,它可能存在缺失数据或其他需要在分析之前进行一些数据清理的问题。Excel文件包括两个标签,一个用于单体帆船,另一个用于双体船。在每个标签中,列被标记为制造商、型号、长度(以英尺为单位)、地理区域、国家/地区/州、挂牌价(以美元计)和制造年份。对于给定的制造商、型号和年份,除了所提供的Excel文件之外,可能还有许多其他来源可以提供有关特定帆船功能的详细描述。你可以用任何你选择的额外数据来补充所提供的数据集;但是,你必须将这些数据包含在你的建模中。“2023_MCM_Problem_Y_Boats.xlsx”中包含的所有数据的来源都必须得到充分的确认和记录。帆船经常通过经纪人出售。为了更好地了解帆船市场,中国香港(SAR)的一位帆船经纪人委托你们准备一份有关二手帆船定价的报告。经纪人希望你们: • 开发一个数学模型,解释所提供电子表格中每个帆船的挂牌价。包括你认为有用的任何预测因素。你可以参考其他来源来了解给定帆船的其他功能(例如,横梁、吃水、排水量、索具、帆面积、船体材料、发动机运行时间、睡眠容量、内部空间高度、电子设备等)和按年份和地区划分的经济数据。确认和描述所使用的所有数据源。包括对每个帆船型号价格的估计精度的讨论。 • 利用你的模型解释地区对挂牌价格的影响,如果有的话。讨论任何地区效应是否在所有帆船变种中都是一致的。讨论任何地区效应的实际和统计意义。 • 讨论您所建模的地理区域如何在香港(SAR)市场中有用。从提供的电子表格中选择一组信息丰富的单体和双体船只,找到该子集在香港(SAR)市场上的可比销售价格数据。模拟香港(SAR)的区域效应对子集中每艘船只的价格的影响,如果有的话。区域效应是否对双体和单体船只均产生相同的影响? • 确定并讨论您的团队从数据中得出的任何其他有趣且有意义的推论或结论。 • 为香港(SAR)帆船经纪人准备一份一页至两页的报告。包括几个精心挑选的图形,以帮助经纪人理解您的结论。
您的PDF解决方案不得超过25页,应包括:
• 一页摘要表格,清楚地描述了您解决问题的方法以及您在问题背景下的最重要结论。 • 目录。 • 完整的解决方案。 • 一到两页的经纪人报告。 • 参考文献清单。
注意:MCM竞赛的页数限制为25页。您的提交的所有方面都计入25页限制(摘要表、目录、报告、向经纪人的一到两页报告、参考文献清单以及任何附录)。您必须引用您报告中使用的所有想法、数据、图片和其他材料的来源。
附件: 数据文件.2023_MCM_Problem_Y_Boats.xlsx 单体船 双体船 数据文件入口说明 品牌:船的制造商的名称。 型号:标识船型的特定模型的名称。 长度(英尺):船的长度(英尺)。 地理区域:船位于的地理区域(加勒比海、欧洲、美国)。 国家/地区/州:船位于的具体国家/地区/州。 挂牌价(美元):以美元标价购买船只的广告价格。 年份:船的制造年份。
0 思路
这是一道实际问题,涉及帆船市场的定价和区域效应等问题。解决这个问题需要开发数学模型,并结合给定的数据进行分析和预测。模型应该包括帆船的各种特征和可能影响价格的预测因素,例如帆船的长度、地理区域、年份、船体材料、发动机运行时间、睡眠容量、内部空间高度、电子设备等等。通过数据分析,我们可以探索不同特征对帆船价格的影响,以及不同地理区域的价格变化趋势。
在解决问题的过程中,还需要注意数据清理和验证,确认和记录所有数据来源,并对模型的精确度和可靠性进行讨论。最终需要为香港(SAR)帆船经纪人准备一份一页至两页的报告,并包括精心挑选的图形和解释,以帮助经纪人理解结论。
首先,了解电子表格中的数据。分析数据的分布,缺失值和异常值,并考虑如何清洗和填充缺失值。
探索数据,识别可能影响帆船挂牌价的因素。这些因素可能包括帆船的长度、制造商、型号、制造年份、地理区域、国家/地区/州、横梁、吃水、排水量、索具、帆面积、船体材料、发动机运行时间、睡眠容量、内部空间高度、电子设备等等。建议通过可视化方式探索这些变量之间的关系。
使用线性回归模型等技术,构建帆船挂牌价的预测模型。确保使用交叉验证等技术评估模型的准确性和稳定性,并讨论模型的误差和可靠性。
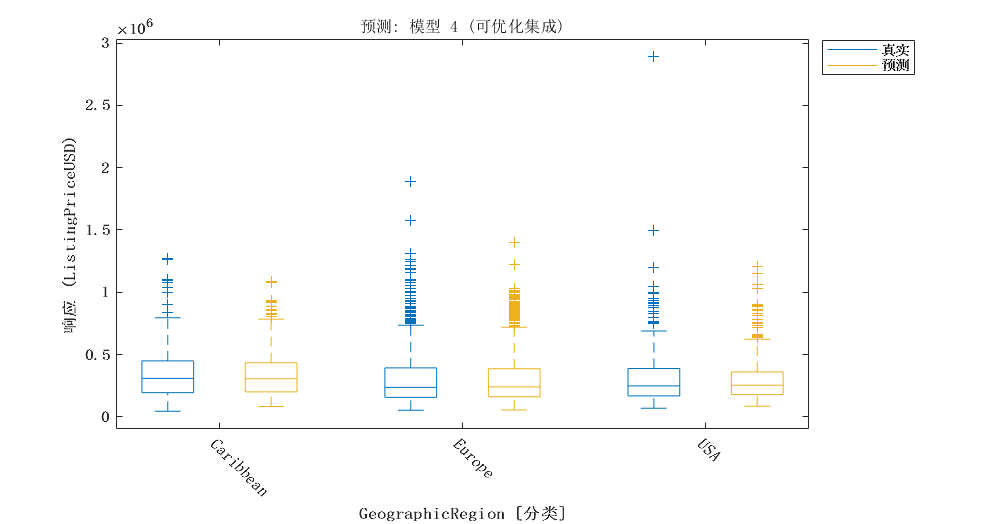
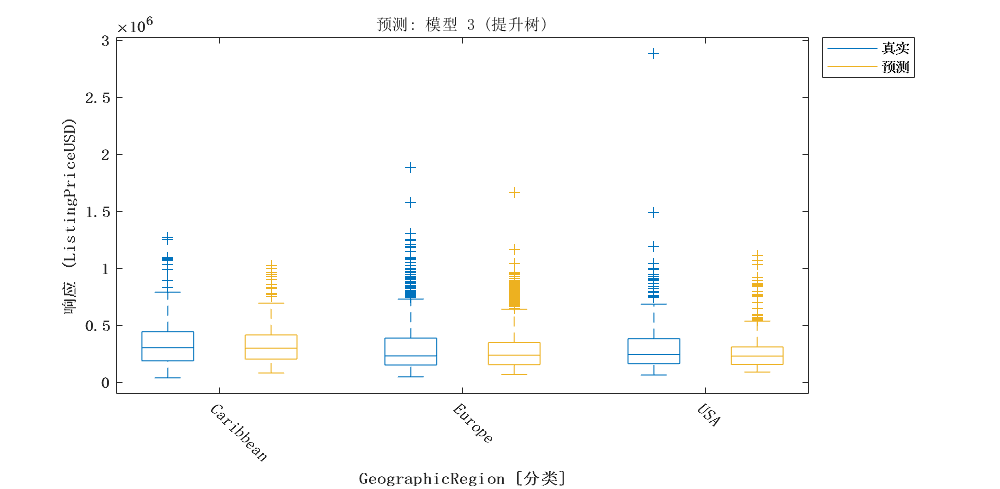
分析地理区域对挂牌价格的影响,并讨论这些影响的实际和统计意义。如果地理区域对挂牌价格有显著影响,建议构建具有交互项的模型,以考虑区域与其他预测因素之间的相互作用。
选择一组信息丰富的单体和双体船只,找到该子集在香港(SAR)市场上的可比销售价格数据。使用模拟方法,估计香港(SAR)区域效应对每艘船只价格的影响,并讨论这些影响是否对双体和单体船只均产生相同的影响。
总结您的分析结果,并讨论团队从数据中得出的任何其他有趣且有意义的推论或结论。
准备一页至两页的报告,其中包括图形和表格,以帮助经纪人理解您的结论。确保您的报告易于理解,重点突出,并具有足够的技术细节来支持您的分析。
1 导入数据
%% 导入电子表格中的数据
%% Set up the Import Options and import the data
opts = spreadsheetImportOptions("NumVariables", 8);
% 指定工作表和范围
opts.Sheet = "Sheet1";
opts.DataRange = "A2:H3492";
% 指定列名称和类型
opts.VariableNames = ["Make", "Variant", "Lengthft", "GeographicRegion", "CountryRegionState", "ListingPriceUSD", "Year", "IsSingle"];
opts.VariableTypes = ["categorical", "categorical", "double", "categorical", "categorical", "double", "double", "categorical"];
% 指定变量属性
opts = setvaropts(opts, ["Make", "Variant", "GeographicRegion", "CountryRegionState", "IsSingle"], "EmptyFieldRule", "auto");
% 导入数据
alldata = readtable("G:\BaiduNetdiskDownload\2023美赛春季赛原版赛题\美赛Y\单体船\数据合并.xlsx", opts, "UseExcel", false);
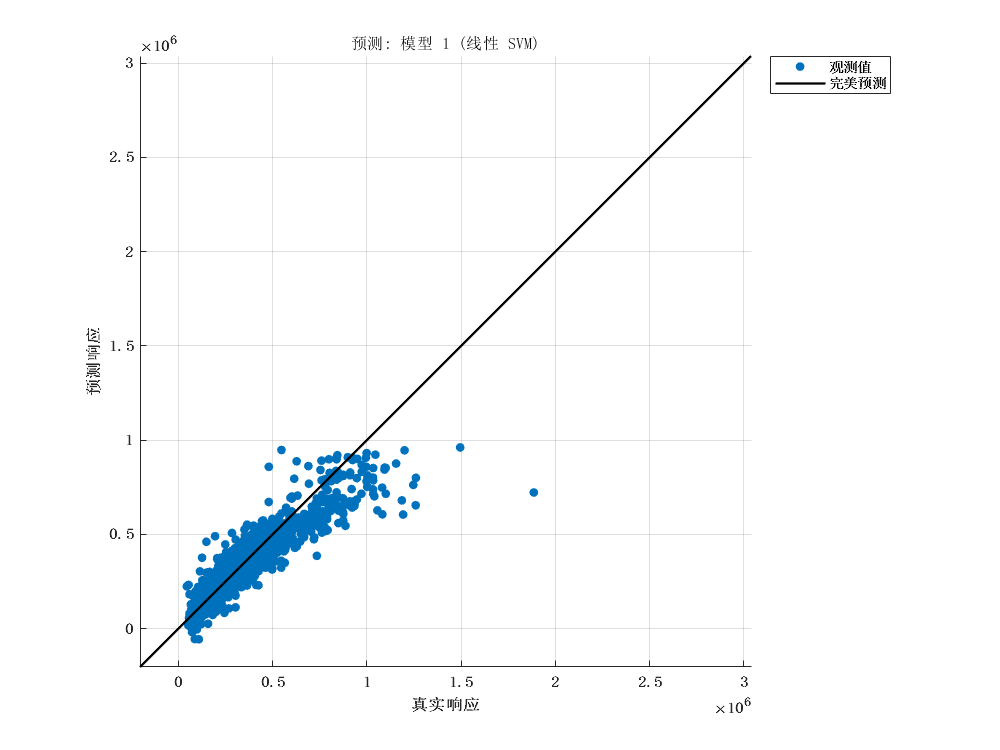 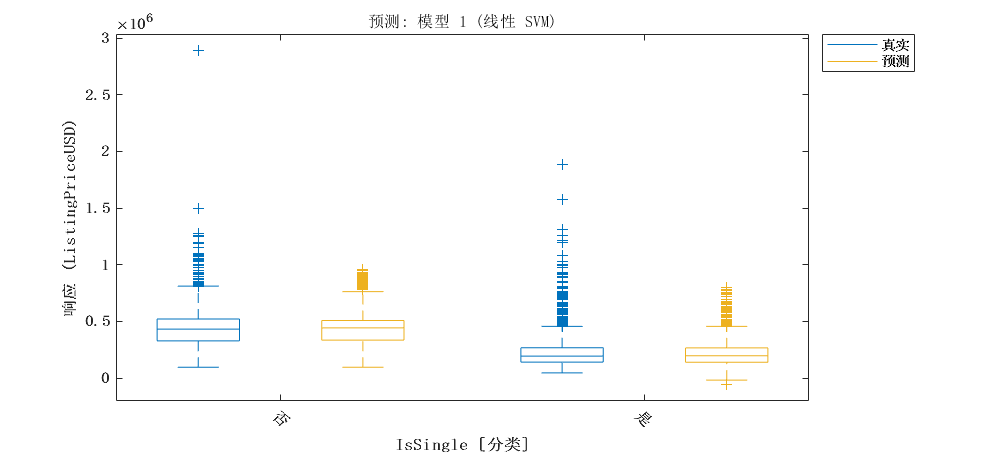 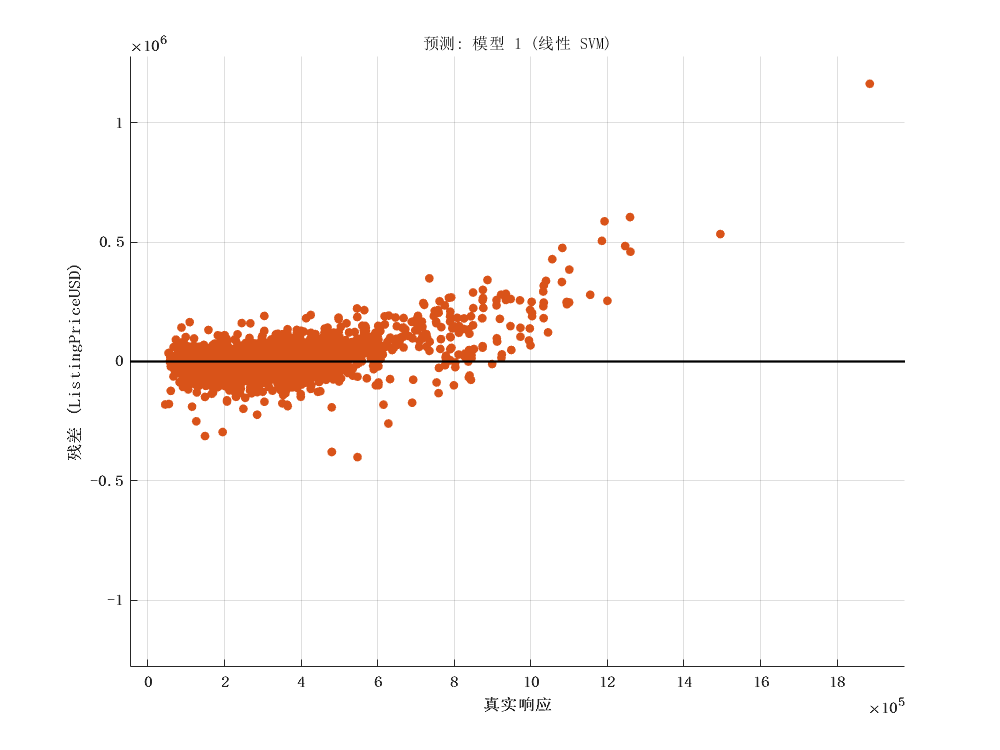 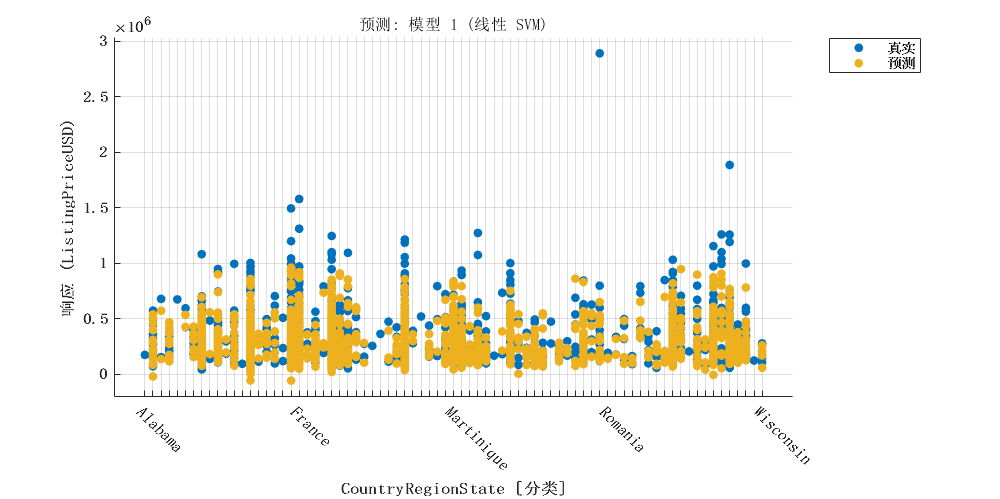 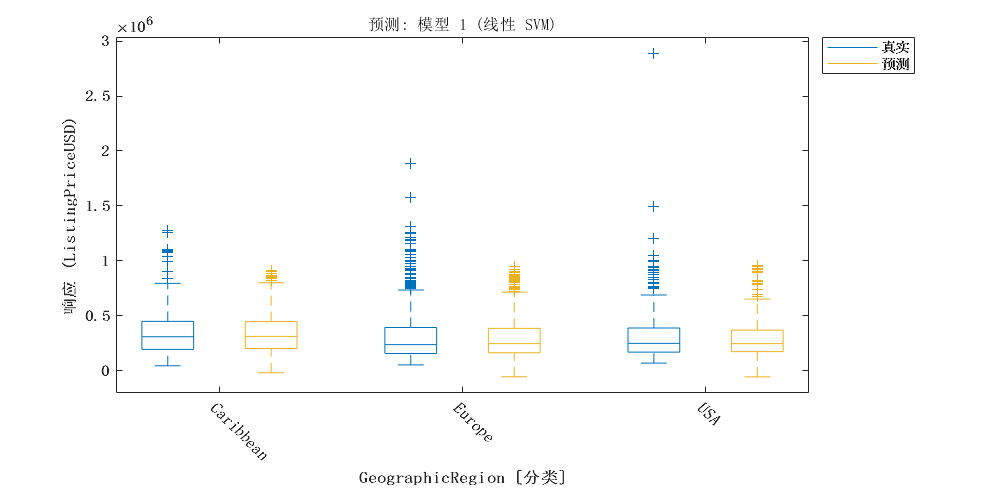 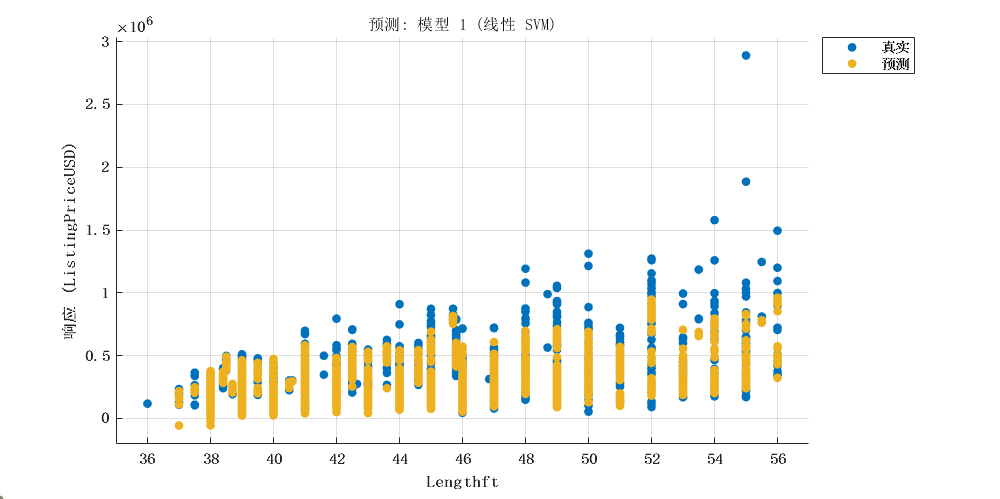 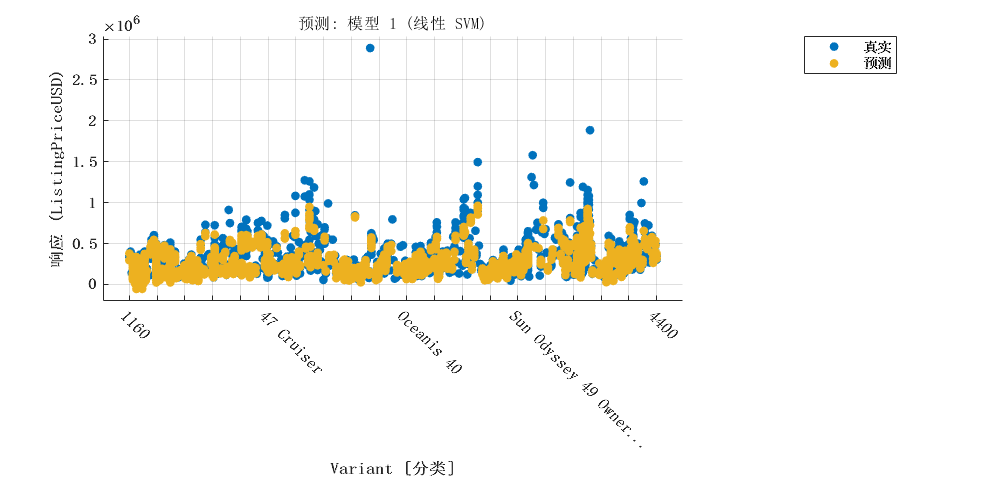
2 模型建立
2.1 线性SVM
function [trainedModel, validationRMSE] = trainRegressionModel(trainingData)
% [trainedModel, validationRMSE] = trainRegressionModel(trainingData)
% 返回经过训练的回归模型及其 RMSE。
%
% 输入:
% trainingData: 一个包含导入 App 中的预测变量和响应列的表。
%
% 输出:
% trainedModel: 一个包含训练的回归模型的结构体。该结构体中具有各种关于所训练模型的
% 信息的字段。
%
% trainedModel.predictFcn: 一个对新数据进行预测的函数。
%
% validationRMSE: 一个包含 RMSE 的双精度值。在 App 中,"历史记录" 列表显示每个
% 模型的 RMSE。
%
% 使用该代码基于新数据来训练模型。要重新训练模型,请使用原始数据或新数据作为输入参数
% trainingData 从命令行调用该函数。
%
% 例如,要重新训练基于原始数据集 T 训练的回归模型,请输入:
% [trainedModel, validationRMSE] = trainRegressionModel(T)
%
% 要使用返回的 "trainedModel" 对新数据 T2 进行预测,请使用
% yfit = trainedModel.predictFcn(T2)
%
% T2 必须是一个表,其中至少包含与训练期间使用的预测变量列相同的预测变量列。有关详细信息,请
% 输入:
% trainedModel.HowToPredict
% 提取预测变量和响应
% 以下代码将数据处理为合适的形状以训练模型。
%
inputTable = trainingData;
predictorNames = {
'Make', 'Variant', 'Lengthft', 'GeographicRegion', 'CountryRegionState', 'Year', 'IsSingle'};
predictors = inputTable(:, predictorNames);
response = inputTable.ListingPriceUSD;
isCategoricalPredictor = [true, true, false, true, true, false, true];
% 将 PCA 应用于预测变量矩阵。
% 仅对数值预测变量运行 PCA。PCA 不会对分类预测变量进行任何处理。
isCategoricalPredictorBeforePCA = isCategoricalPredictor;
numericPredictors = predictors(:, ~isCategoricalPredictor);
numericPredictors = table2array(varfun(@double, numericPredictors));
% 在 PCA 中必须将 'inf' 值视为缺失数据。
numericPredictors(isinf(numericPredictors)) = NaN;
[pcaCoefficients, pcaScores, ~, ~, explained, pcaCenters] = pca(...
numericPredictors);
% 保留足够的成分来解释所需的方差量。
explainedVarianceToKeepAsFraction = 95/100;
numComponentsToKeep = find(cumsum(explained)/sum(explained) >= explainedVarianceToKeepAsFraction, 1);
pcaCoefficients = pcaCoefficients(:,1:numComponentsToKeep);
predictors = [array2table(pcaScores(:,1:numComponentsToKeep)), predictors(:, isCategoricalPredictor)];
isCategoricalPredictor = [false(1,numComponentsToKeep), true(1,sum(isCategoricalPredictor))];
% 训练回归模型
% 以下代码指定所有模型选项并训练模型。
responseScale = iqr(response);
if ~isfinite(responseScale) || responseScale == 0.0
responseScale = 1.0;
end
boxConstraint = responseScale/1.349;
epsilon = responseScale/13.49;
regressionSVM = fitrsvm(...
predictors, ...
response, ...
'KernelFunction', 'linear', ...
'PolynomialOrder', [], ...
'KernelScale', 'auto', ...
'BoxConstraint', boxConstraint, ...
'Epsilon', epsilon, ...
'Standardize', true);
% 使用预测函数创建结果结构体
predictorExtractionFcn = @(t) t(:, predictorNames);
pcaTransformationFcn = @(x) [ array2table((table2array(varfun(@double, x(:, ~isCategoricalPredictorBeforePCA))) - pcaCenters) * pcaCoefficients), x(:,isCategoricalPredictorBeforePCA) ];
svmPredictFcn = @(x) predict(regressionSVM, x);
trainedModel.predictFcn = @(x) svmPredictFcn(pcaTransformationFcn(predictorExtractionFcn(x)));
% 向结果结构体中添加字段
trainedModel.RequiredVariables = {
'CountryRegionState', 'GeographicRegion', 'IsSingle', 'Lengthft', 'Make', 'Variant', 'Year'};
trainedModel.PCACenters = pcaCenters;
trainedModel.PCACoefficients = pcaCoefficients;
trainedModel.RegressionSVM = regressionSVM;
% 提取预测变量和响应
% 以下代码将数据处理为合适的形状以训练模型。
%
inputTable = trainingData;
predictorNames = {
'Make', 'Variant', 'Lengthft', 'GeographicRegion', 'CountryRegionState', 'Year', 'IsSingle'};
predictors = inputTable(:, predictorNames);
response = inputTable.ListingPriceUSD;
isCategoricalPredictor = [true, true, false, true, true, false, true];
% 执行交叉验证
KFolds = 5;
cvp = cvpartition(size(response, 1), 'KFold', KFolds);
% 将预测初始化为适当的大小
validationPredictions = response;
for fold = 1:KFolds
trainingPredictors = predictors(cvp.training(fold), :);
trainingResponse = response(cvp.training(fold), :);
foldIsCategoricalPredictor = isCategoricalPredictor;
% 将 PCA 应用于预测变量矩阵。
% 仅对数值预测变量运行 PCA。PCA 不会对分类预测变量进行任何处理。
isCategoricalPredictorBeforePCA = foldIsCategoricalPredictor;
numericPredictors = trainingPredictors(:, ~foldIsCategoricalPredictor);
numericPredictors = table2array(varfun(@double, numericPredictors));
% 在 PCA 中必须将 'inf' 值视为缺失数据。
numericPredictors(isinf(numericPredictors)) = NaN;
[pcaCoefficients, pcaScores, ~, ~, explained, pcaCenters] = pca(...
numericPredictors);
% 保留足够的成分来解释所需的方差量。
explainedVarianceToKeepAsFraction = 95/100;
numComponentsToKeep = find(cumsum(explained)/sum(explained) >= explainedVarianceToKeepAsFraction, 1);
pcaCoefficients = pcaCoefficients(:,1:numComponentsToKeep);
trainingPredictors = [array2table(pcaScores(:,1:numComponentsToKeep)), trainingPredictors(:, foldIsCategoricalPredictor)];
foldIsCategoricalPredictor = [false(1,numComponentsToKeep), true(1,sum(foldIsCategoricalPredictor))];
% 训练回归模型
% 以下代码指定所有模型选项并训练模型。
responseScale = iqr(trainingResponse);
if ~isfinite(responseScale) || responseScale == 0.0
responseScale = 1.0;
end
boxConstraint = responseScale/1.349;
epsilon = responseScale/13.49;
regressionSVM = fitrsvm(...
trainingPredictors, ...
trainingResponse, ...
'KernelFunction', 'linear', ...
'PolynomialOrder', [], ...
'KernelScale', 'auto', ...
'BoxConstraint', boxConstraint, ...
'Epsilon', epsilon, ...
'Standardize', true);
% 使用预测函数创建结果结构体
pcaTransformationFcn = @(x) [ array2table((table2array(varfun(@double, x(:, ~isCategoricalPredictorBeforePCA))) - pcaCenters) * pcaCoefficients), x(:,isCategoricalPredictorBeforePCA) ];
svmPredictFcn = @(x) predict(regressionSVM, x);
validationPredictFcn = @(x) svmPredictFcn(pcaTransformationFcn(x));
% 向结果结构体中添加字段
% 计算验证预测
validationPredictors = predictors(cvp.test(fold), :);
foldPredictions = validationPredictFcn(validationPredictors);
% 按原始顺序存储预测
validationPredictions(cvp.test(fold), :) = foldPredictions;
end
% 计算验证 RMSE
isNotMissing = ~isnan(validationPredictions) & ~isnan(response);
validationRMSE = sqrt(nansum(( validationPredictions - response ).^2) / numel(response(isNotMissing) ));
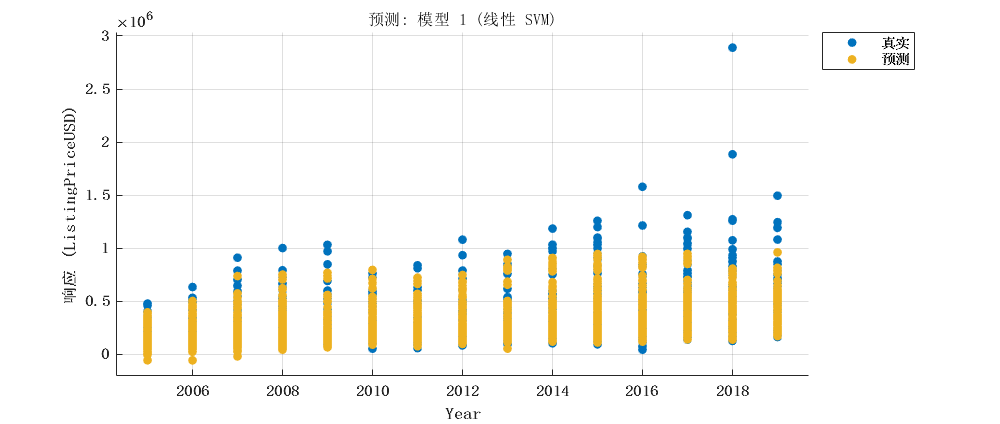
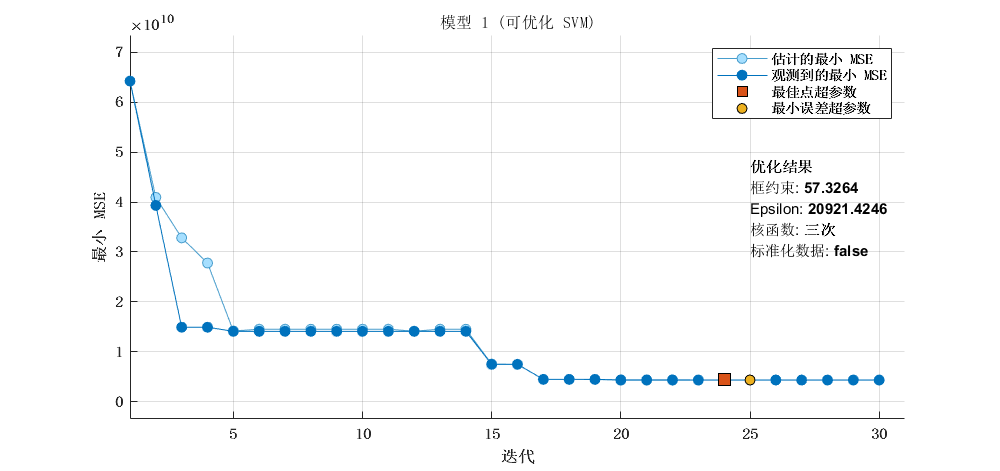
2.1 优化的SVM
function [trainedModel, validationRMSE] = trainRegressionModel(trainingData)
% [trainedModel, validationRMSE] = trainRegressionModel(trainingData)
% 返回经过训练的回归模型及其 RMSE。
%
% 输入:
% trainingData: 一个包含导入 App 中的预测变量和响应列的表。
%
% 输出:
% trainedModel: 一个包含训练的回归模型的结构体。该结构体中具有各种关于所训练模型的
% 信息的字段。
%
% trainedModel.predictFcn: 一个对新数据进行预测的函数。
%
% validationRMSE: 一个包含 RMSE 的双精度值。
%
% 使用该代码基于新数据来训练模型。要重新训练模型,请使用原始数据或新数据作为输入参数
% trainingData 从命令行调用该函数。
%
% 例如,要重新训练基于原始数据集 T 训练的回归模型,请输入:
% [trainedModel, validationRMSE] = trainRegressionModel(T)
%
% 要使用返回的 "trainedModel" 对新数据 T2 进行预测,请使用
% yfit = trainedModel.predictFcn(T2)
%
% T2 必须是一个表,其中至少包含与训练期间使用的预测变量列相同的预测变量列。有关详细信息,请
% 输入:
% trainedModel.HowToPredict
% 提取预测变量和响应
% 以下代码将数据处理为合适的形状以训练模型。
%
inputTable = trainingData;
predictorNames = {
'Make', 'Variant', 'Lengthft', 'GeographicRegion', 'CountryRegionState', 'Year', 'IsSingle'};
predictors = inputTable(:, predictorNames);
response = inputTable.ListingPriceUSD;
isCategoricalPredictor = [true, true, false, true, true, false, true];
% 将 PCA 应用于预测变量矩阵。
% 仅对数值预测变量运行 PCA。PCA 不会对分类预测变量进行任何处理。
isCategoricalPredictorBeforePCA = isCategoricalPredictor;
numericPredictors = predictors(:, ~isCategoricalPredictor);
numericPredictors = table2array(varfun(@double, numericPredictors));
% 在 PCA 中必须将 'inf' 值视为缺失数据。
numericPredictors(isinf(numericPredictors)) = NaN;
[pcaCoefficients, pcaScores, ~, ~, explained, pcaCenters] = pca(...
numericPredictors);
% 保留足够的成分来解释所需的方差量。
explainedVarianceToKeepAsFraction = 95/100;
numComponentsToKeep = find(cumsum(explained)/sum(explained) >= explainedVarianceToKeepAsFraction, 1);
pcaCoefficients = pcaCoefficients(:,1:numComponentsToKeep);
predictors = [array2table(pcaScores(:,1:numComponentsToKeep)), predictors(:, isCategoricalPredictor)];
isCategoricalPredictor = [false(1,numComponentsToKeep), true(1,sum(isCategoricalPredictor))];
% 训练回归模型
% 以下代码指定所有模型选项并训练模型。
regressionSVM = fitrsvm(...
predictors, ...
response, ...
'KernelFunction', 'polynomial', ...
'PolynomialOrder', 3, ...
'KernelScale', 1, ...
'BoxConstraint', 57.32643011549448, ...
'Epsilon', 20921.42456725201, ...
'Standardize', false);
% 使用预测函数创建结果结构体
predictorExtractionFcn = @(t) t(:, predictorNames);
pcaTransformationFcn = @(x) [ array2table((table2array(varfun(@double, x(:, ~isCategoricalPredictorBeforePCA))) - pcaCenters) * pcaCoefficients), x(:,isCategoricalPredictorBeforePCA) ];
svmPredictFcn = @(x) predict(regressionSVM, x);
trainedModel.predictFcn = @(x) svmPredictFcn(pcaTransformationFcn(predictorExtractionFcn(x)));
% 向结果结构体中添加字段
trainedModel.RequiredVariables = {
'CountryRegionState', 'GeographicRegion', 'IsSingle', 'Lengthft', 'Make', 'Variant', 'Year'};
trainedModel.PCACenters = pcaCenters;
trainedModel.PCACoefficients = pcaCoefficients;
trainedModel.RegressionSVM = regressionSVM;
% 提取预测变量和响应
% 以下代码将数据处理为合适的形状以训练模型。
%
inputTable = trainingData;
predictorNames = {
'Make', 'Variant', 'Lengthft', 'GeographicRegion', 'CountryRegionState', 'Year', 'IsSingle'};
predictors = inputTable(:, predictorNames);
response = inputTable.ListingPriceUSD;
isCategoricalPredictor = [true, true, false, true, true, false, true];
% 执行交叉验证
KFolds = 5;
cvp = cvpartition(size(response, 1), 'KFold', KFolds);
% 将预测初始化为适当的大小
validationPredictions = response;
for fold = 1:KFolds
trainingPredictors = predictors(cvp.training(fold), :);
trainingResponse = response(cvp.training(fold), :);
foldIsCategoricalPredictor = isCategoricalPredictor;
% 将 PCA 应用于预测变量矩阵。
% 仅对数值预测变量运行 PCA。PCA 不会对分类预测变量进行任何处理。
isCategoricalPredictorBeforePCA = foldIsCategoricalPredictor;
numericPredictors = trainingPredictors(:, ~foldIsCategoricalPredictor);
numericPredictors = table2array(varfun(@double, numericPredictors));
% 在 PCA 中必须将 'inf' 值视为缺失数据。
numericPredictors(isinf(numericPredictors)) = NaN;
[pcaCoefficients, pcaScores, ~, ~, explained, pcaCenters] = pca(...
numericPredictors);
% 保留足够的成分来解释所需的方差量。
explainedVarianceToKeepAsFraction = 95/100;
numComponentsToKeep = find(cumsum(explained)/sum(explained) >= explainedVarianceToKeepAsFraction, 1);
pcaCoefficients = pcaCoefficients(:,1:numComponentsToKeep);
trainingPredictors = [array2table(pcaScores(:,1:numComponentsToKeep)), trainingPredictors(:, foldIsCategoricalPredictor)];
foldIsCategoricalPredictor = [false(1,numComponentsToKeep), true(1,sum(foldIsCategoricalPredictor))];
% 训练回归模型
% 以下代码指定所有模型选项并训练模型。
regressionSVM = fitrsvm(...
trainingPredictors, ...
trainingResponse, ...
'KernelFunction', 'polynomial', ...
'PolynomialOrder', 3, ...
'KernelScale', 1, ...
'BoxConstraint', 57.32643011549448, ...
'Epsilon', 20921.42456725201, ...
'Standardize', false);
% 使用预测函数创建结果结构体
pcaTransformationFcn = @(x) [ array2table((table2array(varfun(@double, x(:, ~isCategoricalPredictorBeforePCA))) - pcaCenters) * pcaCoefficients), x(:,isCategoricalPredictorBeforePCA) ];
svmPredictFcn = @(x) predict(regressionSVM, x);
validationPredictFcn = @(x) svmPredictFcn(pcaTransformationFcn(x));
% 向结果结构体中添加字段
% 计算验证预测
validationPredictors = predictors(cvp.test(fold), :);
foldPredictions = validationPredictFcn(validationPredictors);
% 按原始顺序存储预测
validationPredictions(cvp.test(fold), :) = foldPredictions;
end
% 计算验证 RMSE
isNotMissing = ~isnan(validationPredictions) & ~isnan(response);
validationRMSE = sqrt(nansum(( validationPredictions - response ).^2) / numel(response(isNotMissing) ));
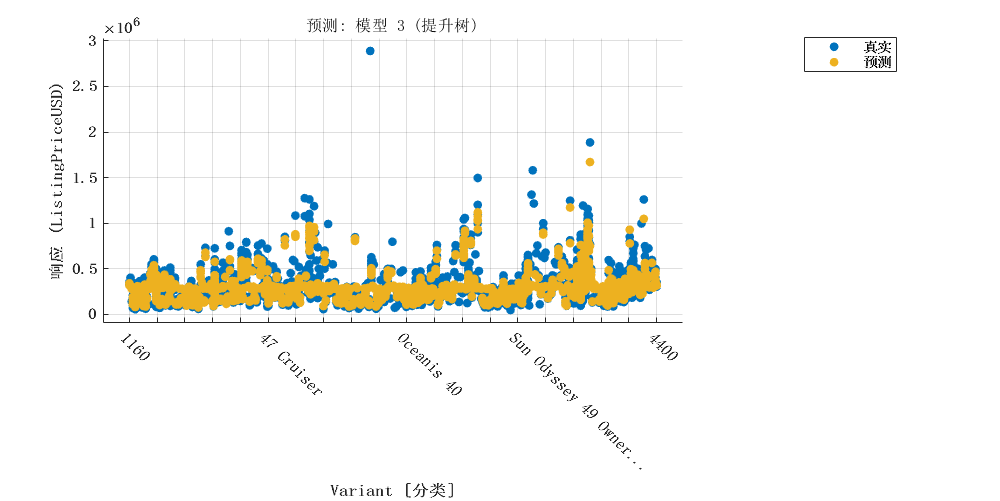
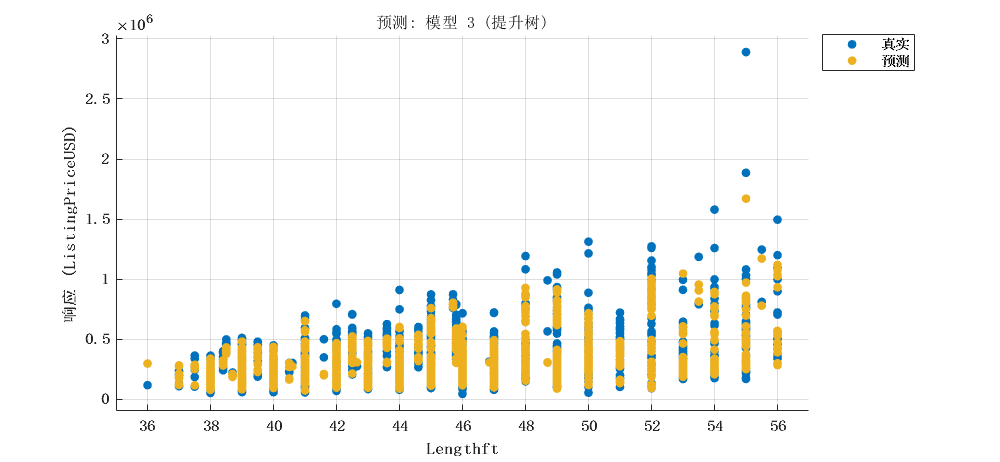
2.2 集成学习
function [trainedModel, validationRMSE] = trainRegressionModel(trainingData)
% [trainedModel, validationRMSE] = trainRegressionModel(trainingData)
% 返回经过训练的回归模型及其 RMSE。
%
% 输入:
% trainingData: 一个包含导入 App 中的预测变量和响应列的表。
%
% 输出:
% trainedModel: 一个包含训练的回归模型的结构体。该结构体中具有各种关于所训练模型的
% 信息的字段。
%
% trainedModel.predictFcn: 一个对新数据进行预测的函数。
%
% validationRMSE: 一个包含 RMSE 的双精度值。在 App 中,"历史记录" 列表显示每个
% 模型的 RMSE。
%
% 使用该代码基于新数据来训练模型。要重新训练模型,请使用原始数据或新数据作为输入参数
% trainingData 从命令行调用该函数。
%
% 例如,要重新训练基于原始数据集 T 训练的回归模型,请输入:
% [trainedModel, validationRMSE] = trainRegressionModel(T)
%
% 要使用返回的 "trainedModel" 对新数据 T2 进行预测,请使用
% yfit = trainedModel.predictFcn(T2)
%
% T2 必须是一个表,其中至少包含与训练期间使用的预测变量列相同的预测变量列。有关详细信息,请
% 输入:
% trainedModel.HowToPredict
% 提取预测变量和响应
% 以下代码将数据处理为合适的形状以训练模型。
%
inputTable = trainingData;
predictorNames = {
'Make', 'Variant', 'Lengthft', 'GeographicRegion', 'CountryRegionState', 'Year', 'IsSingle'};
predictors = inputTable(:, predictorNames);
response = inputTable.ListingPriceUSD;
isCategoricalPredictor = [true, true, false, true, true, false, true];
% 将 PCA 应用于预测变量矩阵。
% 仅对数值预测变量运行 PCA。PCA 不会对分类预测变量进行任何处理。
isCategoricalPredictorBeforePCA = isCategoricalPredictor;
numericPredictors = predictors(:, ~isCategoricalPredictor);
numericPredictors = table2array(varfun(@double, numericPredictors));
% 在 PCA 中必须将 'inf' 值视为缺失数据。
numericPredictors(isinf(numericPredictors)) = NaN;
[pcaCoefficients, pcaScores, ~, ~, explained, pcaCenters] = pca(...
numericPredictors);
% 保留足够的成分来解释所需的方差量。
explainedVarianceToKeepAsFraction = 95/100;
numComponentsToKeep = find(cumsum(explained)/sum(explained) >= explainedVarianceToKeepAsFraction, 1);
pcaCoefficients = pcaCoefficients(:,1:numComponentsToKeep);
predictors = [array2table(pcaScores(:,1:numComponentsToKeep)), predictors(:, isCategoricalPredictor)];
isCategoricalPredictor = [false(1,numComponentsToKeep), true(1,sum(isCategoricalPredictor))];
% 训练回归模型
% 以下代码指定所有模型选项并训练模型。
template = templateTree(...
'MinLeafSize', 8);
regressionEnsemble = fitrensemble(...
predictors, ...
response, ...
'Method', 'LSBoost', ...
'NumLearningCycles', 30, ...
'Learners', template, ...
'LearnRate', 0.1);
% 使用预测函数创建结果结构体
predictorExtractionFcn = @(t) t(:, predictorNames);
pcaTransformationFcn = @(x) [ array2table((table2array(varfun(@double, x(:, ~isCategoricalPredictorBeforePCA))) - pcaCenters) * pcaCoefficients), x(:,isCategoricalPredictorBeforePCA) ];
ensemblePredictFcn = @(x) predict(regressionEnsemble, x);
trainedModel.predictFcn = @(x) ensemblePredictFcn(pcaTransformationFcn(predictorExtractionFcn(x)));
% 向结果结构体中添加字段
trainedModel.RequiredVariables = {
'CountryRegionState', 'GeographicRegion', 'IsSingle', 'Lengthft', 'Make', 'Variant', 'Year'};
trainedModel.PCACenters = pcaCenters;
trainedModel.PCACoefficients = pcaCoefficients;
trainedModel.RegressionEnsemble = regressionEnsemble;
% 提取预测变量和响应
% 以下代码将数据处理为合适的形状以训练模型。
%
inputTable = trainingData;
predictorNames = {
'Make', 'Variant', 'Lengthft', 'GeographicRegion', 'CountryRegionState', 'Year', 'IsSingle'};
predictors = inputTable(:, predictorNames);
response = inputTable.ListingPriceUSD;
isCategoricalPredictor = [true, true, false, true, true, false, true];
% 执行交叉验证
KFolds = 5;
cvp = cvpartition(size(response, 1), 'KFold', KFolds);
% 将预测初始化为适当的大小
validationPredictions = response;
for fold = 1:KFolds
trainingPredictors = predictors(cvp.training(fold), :);
trainingResponse = response(cvp.training(fold), :);
foldIsCategoricalPredictor = isCategoricalPredictor;
% 将 PCA 应用于预测变量矩阵。
% 仅对数值预测变量运行 PCA。PCA 不会对分类预测变量进行任何处理。
isCategoricalPredictorBeforePCA = foldIsCategoricalPredictor;
numericPredictors = trainingPredictors(:, ~foldIsCategoricalPredictor);
numericPredictors = table2array(varfun(@double, numericPredictors));
% 在 PCA 中必须将 'inf' 值视为缺失数据。
numericPredictors(isinf(numericPredictors)) = NaN;
[pcaCoefficients, pcaScores, ~, ~, explained, pcaCenters] = pca(...
numericPredictors);
% 保留足够的成分来解释所需的方差量。
explainedVarianceToKeepAsFraction = 95/100;
numComponentsToKeep = find(cumsum(explained)/sum(explained) >= explainedVarianceToKeepAsFraction, 1);
pcaCoefficients = pcaCoefficients(:,1:numComponentsToKeep);
trainingPredictors = [array2table(pcaScores(:,1:numComponentsToKeep)), trainingPredictors(:, foldIsCategoricalPredictor)];
foldIsCategoricalPredictor = [false(1,numComponentsToKeep), true(1,sum(foldIsCategoricalPredictor))];
% 训练回归模型
% 以下代码指定所有模型选项并训练模型。
template = templateTree(...
'MinLeafSize', 8);
regressionEnsemble = fitrensemble(...
trainingPredictors, ...
trainingResponse, ...
'Method', 'LSBoost', ...
'NumLearningCycles', 30, ...
'Learners', template, ...
'LearnRate', 0.1);
% 使用预测函数创建结果结构体
pcaTransformationFcn = @(x) [ array2table((table2array(varfun(@double, x(:, ~isCategoricalPredictorBeforePCA))) - pcaCenters) * pcaCoefficients), x(:,isCategoricalPredictorBeforePCA) ];
ensemblePredictFcn = @(x) predict(regressionEnsemble, x);
validationPredictFcn = @(x) ensemblePredictFcn(pcaTransformationFcn(x));
% 向结果结构体中添加字段
% 计算验证预测
validationPredictors = predictors(cvp.test(fold), :);
foldPredictions = validationPredictFcn(validationPredictors);
% 按原始顺序存储预测
validationPredictions(cvp.test(fold), :) = foldPredictions;
end
% 计算验证 RMSE
isNotMissing = ~isnan(validationPredictions) & ~isnan(response);
validationRMSE = sqrt(nansum(( validationPredictions - response ).^2) / numel(response(isNotMissing) ));

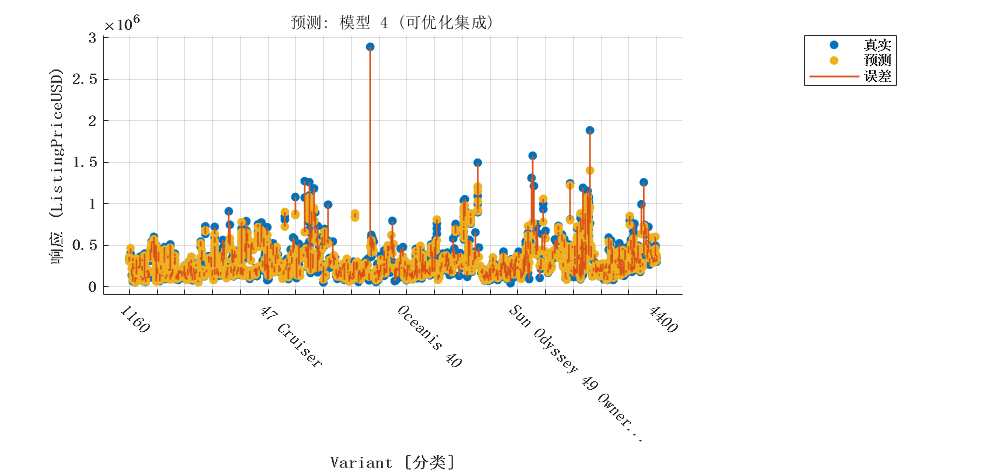
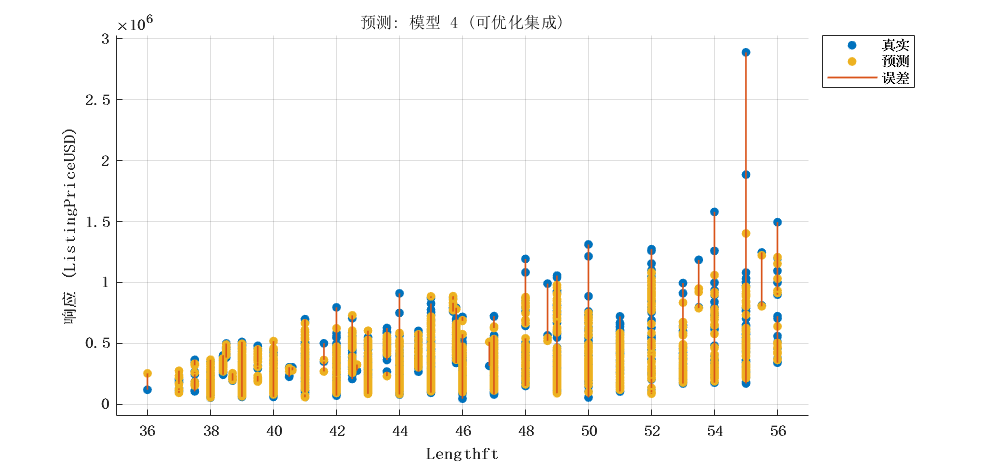
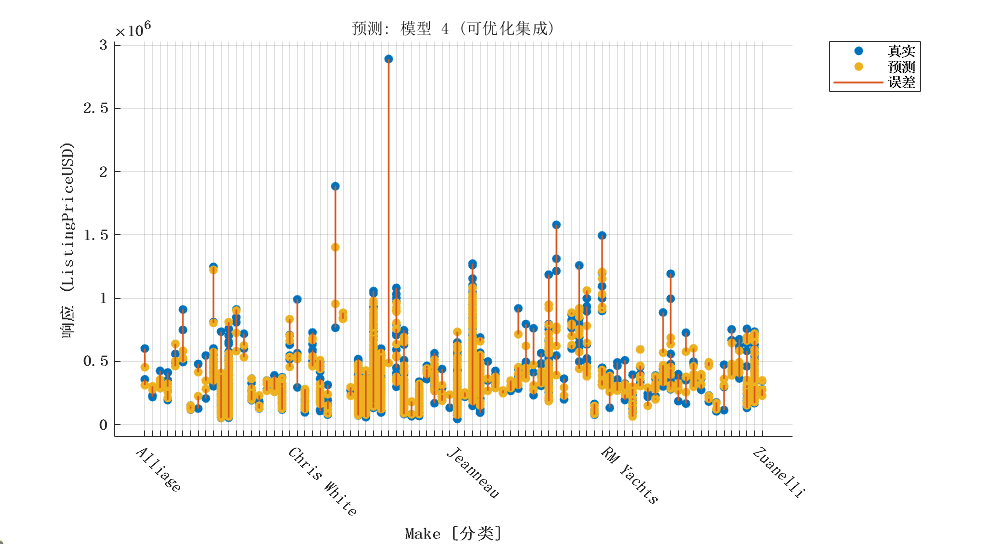
2.4 优化的集成学习模型
function [trainedModel, validationRMSE] = trainRegressionModel(trainingData)
% [trainedModel, validationRMSE] = trainRegressionModel(trainingData)
% 返回经过训练的回归模型及其 RMSE。
% 输入:
% trainingData: 一个包含导入 App 中的预测变量和响应列的表。
%
% 输出:
% trainedModel: 一个包含训练的回归模型的结构体。该结构体中具有各种关于所训练模型的
% 信息的字段。
%
% trainedModel.predictFcn: 一个对新数据进行预测的函数。
%
% validationRMSE: 一个包含 RMSE 的双精度值。在 App 中,"历史记录" 列表显示每个
% 模型的 RMSE。
%
% 使用该代码基于新数据来训练模型。要重新训练模型,请使用原始数据或新数据作为输入参数
% trainingData 从命令行调用该函数。
%
% 例如,要重新训练基于原始数据集 T 训练的回归模型,请输入:
% [trainedModel, validationRMSE] = trainRegressionModel(T)
%
% 要使用返回的 "trainedModel" 对新数据 T2 进行预测,请使用
% yfit = trainedModel.predictFcn(T2)
%
% T2 必须是一个表,其中至少包含与训练期间使用的预测变量列相同的预测变量列。有关详细信息,请
% 输入:
% trainedModel.HowToPredict
% 提取预测变量和响应
% 以下代码将数据处理为合适的形状以训练模型。
%
inputTable = trainingData;
predictorNames = {
'Make', 'Variant', 'Lengthft', 'GeographicRegion', 'CountryRegionState', 'Year', 'IsSingle'};
predictors = inputTable(:, predictorNames);
response = inputTable.ListingPriceUSD;
isCategoricalPredictor = [true, true, false, true, true, false, true];
% 将 PCA 应用于预测变量矩阵。
% 仅对数值预测变量运行 PCA。PCA 不会对分类预测变量进行任何处理。
isCategoricalPredictorBeforePCA = isCategoricalPredictor;
numericPredictors = predictors(:, ~isCategoricalPredictor);
numericPredictors = table2array(varfun(@double, numericPredictors));
% 在 PCA 中必须将 'inf' 值视为缺失数据。
numericPredictors(isinf(numericPredictors)) = NaN;
[pcaCoefficients, pcaScores, ~, ~, explained, pcaCenters] = pca(...
numericPredictors);
% 保留足够的成分来解释所需的方差量。
explainedVarianceToKeepAsFraction = 95/100;
numComponentsToKeep = find(cumsum(explained)/sum(explained) >= explainedVarianceToKeepAsFraction, 1);
pcaCoefficients = pcaCoefficients(:,1:numComponentsToKeep);
predictors = [array2table(pcaScores(:,1:numComponentsToKeep)), predictors(:, isCategoricalPredictor)];
isCategoricalPredictor = [false(1,numComponentsToKeep), true(1,sum(isCategoricalPredictor))];
% 训练回归模型
% 以下代码指定所有模型选项并训练模型。
template = templateTree(...
'MinLeafSize', 826, ...
'NumVariablesToSample', 1);
regressionEnsemble = fitrensemble(...
predictors, ...
response, ...
'Method', 'LSBoost', ...
'NumLearningCycles', 153, ...
'Learners', template, ...
'LearnRate', 0.9987466306963503);
% 使用预测函数创建结果结构体
predictorExtractionFcn = @(t) t(:, predictorNames);
pcaTransformationFcn = @(x) [ array2table((table2array(varfun(@double, x(:, ~isCategoricalPredictorBeforePCA))) - pcaCenters) * pcaCoefficients), x(:,isCategoricalPredictorBeforePCA) ];
ensemblePredictFcn = @(x) predict(regressionEnsemble, x);
trainedModel.predictFcn = @(x) ensemblePredictFcn(pcaTransformationFcn(predictorExtractionFcn(x)));
% 向结果结构体中添加字段
trainedModel.RequiredVariables = {
'CountryRegionState', 'GeographicRegion', 'IsSingle', 'Lengthft', 'Make', 'Variant', 'Year'};
trainedModel.PCACenters = pcaCenters;
trainedModel.PCACoefficients = pcaCoefficients;
trainedModel.RegressionEnsemble = regressionEnsemble;
% 提取预测变量和响应
% 以下代码将数据处理为合适的形状以训练模型。
%
inputTable = trainingData;
predictorNames = {
'Make', 'Variant', 'Lengthft', 'GeographicRegion', 'CountryRegionState', 'Year', 'IsSingle'};
predictors = inputTable(:, predictorNames);
response = inputTable.ListingPriceUSD;
isCategoricalPredictor = [true, true, false, true, true, false, true];
% 执行交叉验证
KFolds = 5;
cvp = cvpartition(size(response, 1), 'KFold', KFolds);
% 将预测初始化为适当的大小
validationPredictions = response;
for fold = 1:KFolds
trainingPredictors = predictors(cvp.training(fold), :);
trainingResponse = response(cvp.training(fold), :);
foldIsCategoricalPredictor = isCategoricalPredictor;
% 将 PCA 应用于预测变量矩阵。
% 仅对数值预测变量运行 PCA。PCA 不会对分类预测变量进行任何处理。
isCategoricalPredictorBeforePCA = foldIsCategoricalPredictor;
numericPredictors = trainingPredictors(:, ~foldIsCategoricalPredictor);
numericPredictors = table2array(varfun(@double, numericPredictors));
% 在 PCA 中必须将 'inf' 值视为缺失数据。
numericPredictors(isinf(numericPredictors)) = NaN;
[pcaCoefficients, pcaScores, ~, ~, explained, pcaCenters] = pca(...
numericPredictors);
% 保留足够的成分来解释所需的方差量。
explainedVarianceToKeepAsFraction = 95/100;
numComponentsToKeep = find(cumsum(explained)/sum(explained) >= explainedVarianceToKeepAsFraction, 1);
pcaCoefficients = pcaCoefficients(:,1:numComponentsToKeep);
trainingPredictors = [array2table(pcaScores(:,1:numComponentsToKeep)), trainingPredictors(:, foldIsCategoricalPredictor)];
foldIsCategoricalPredictor = [false(1,numComponentsToKeep), true(1,sum(foldIsCategoricalPredictor))];
% 训练回归模型
% 以下代码指定所有模型选项并训练模型。
template = templateTree(...
'MinLeafSize', 826, ...
'NumVariablesToSample', 1);
regressionEnsemble = fitrensemble(...
trainingPredictors, ...
trainingResponse, ...
'Method', 'LSBoost', ...
'NumLearningCycles', 153, ...
'Learners', template, ...
'LearnRate', 0.9987466306963503);
% 使用预测函数创建结果结构体
pcaTransformationFcn = @(x) [ array2table((table2array(varfun(@double, x(:, ~isCategoricalPredictorBeforePCA))) - pcaCenters) * pcaCoefficients), x(:,isCategoricalPredictorBeforePCA) ];
ensemblePredictFcn = @(x) predict(regressionEnsemble, x);
validationPredictFcn = @(x) ensemblePredictFcn(pcaTransformationFcn(x));
% 向结果结构体中添加字段
% 计算验证预测
validationPredictors = predictors(cvp.test(fold), :);
foldPredictions = validationPredictFcn(validationPredictors);
% 按原始顺序存储预测
validationPredictions(cvp.test(fold), :) = foldPredictions;
end
% 计算验证 RMSE
isNotMissing = ~isnan(validationPredictions) & ~isnan(response);
validationRMSE = sqrt(nansum(( validationPredictions - response ).^2) / numel(response(isNotMissing) ));
   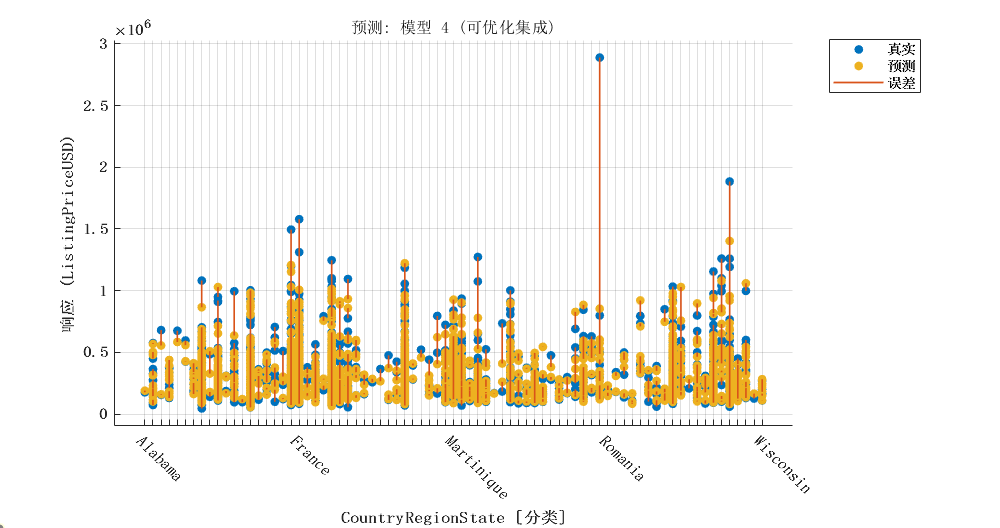  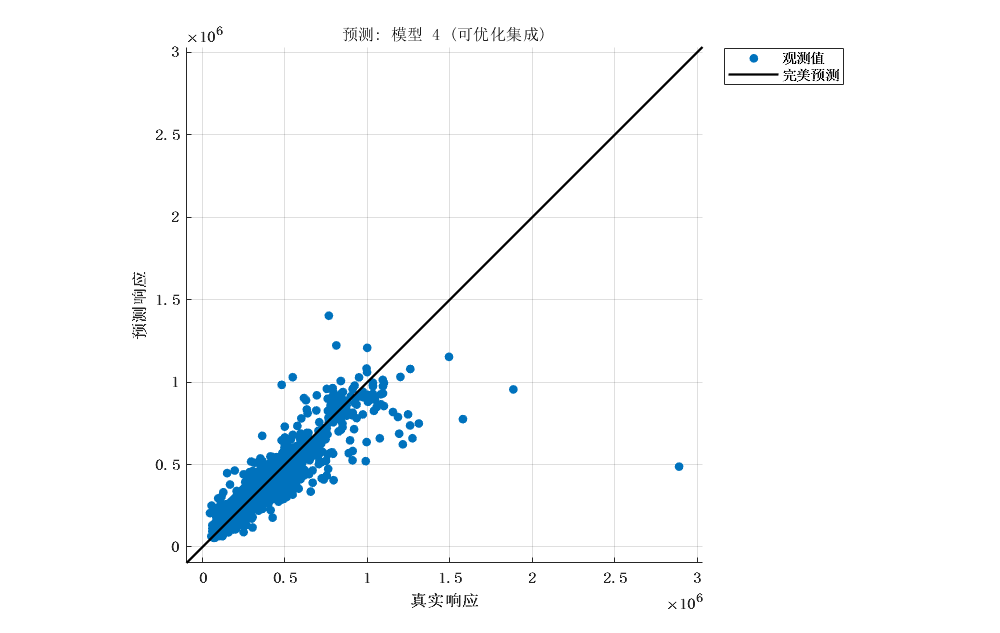 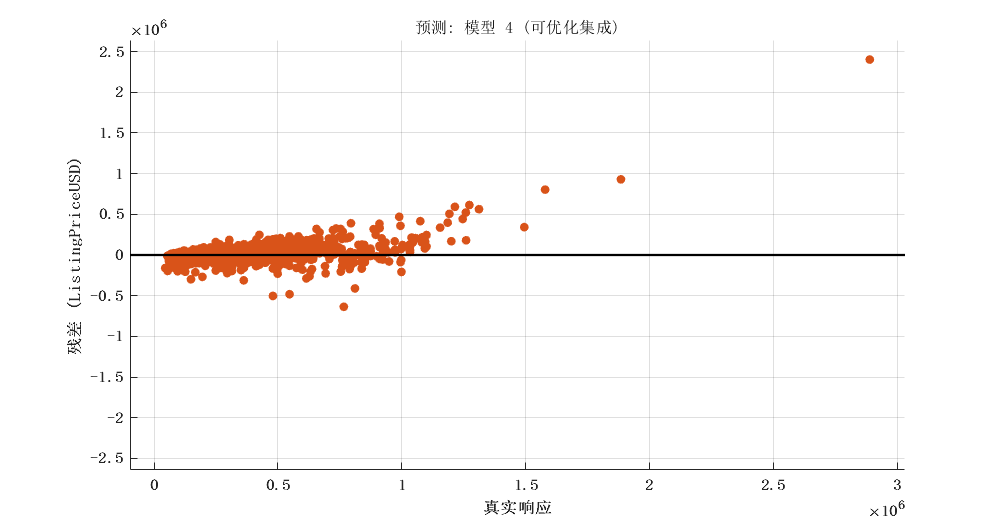 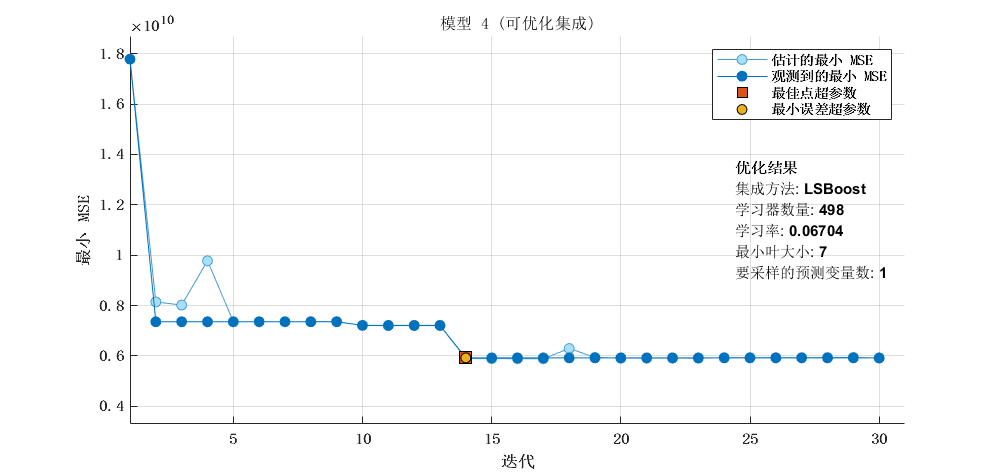     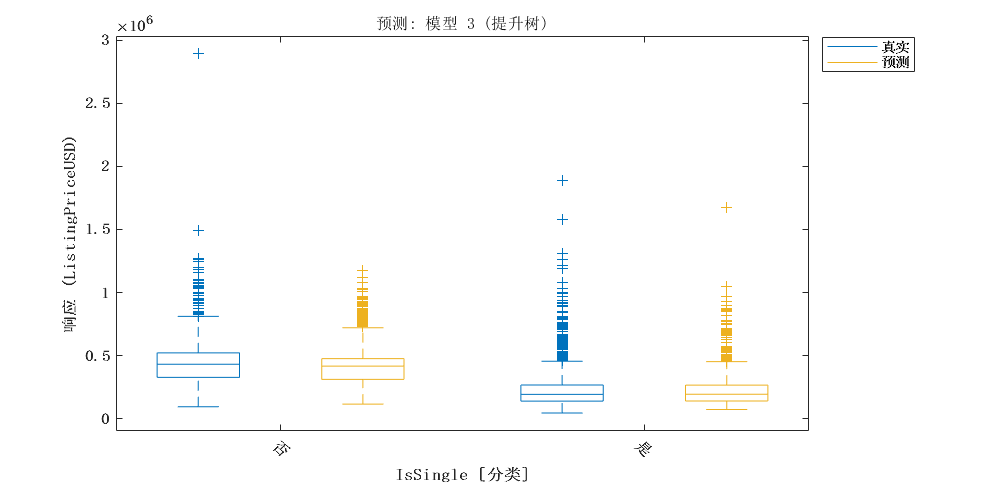 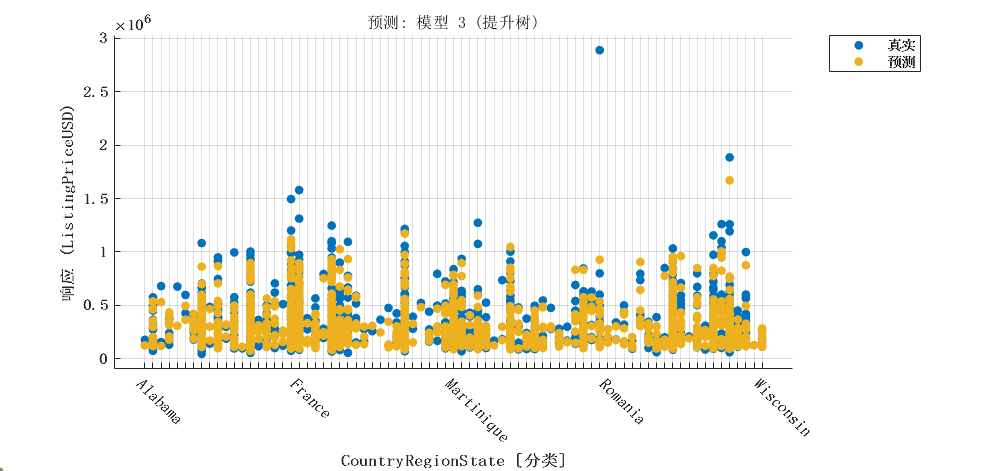 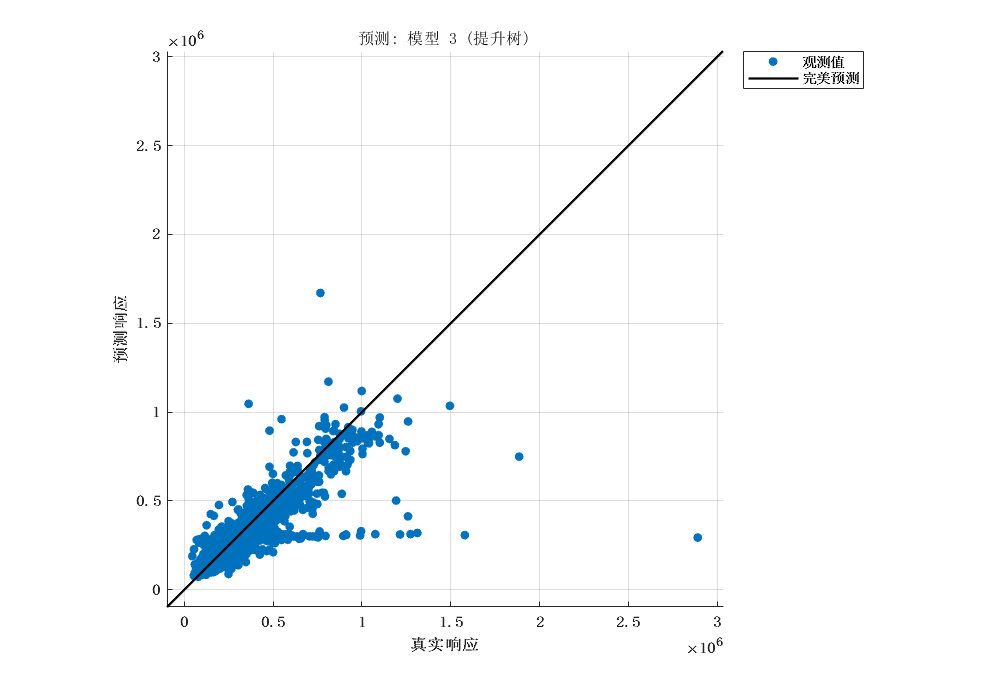 
|