| 七爪源码:Python:时间复杂度 | 您所在的位置:网站首页 › python画椭圆形函数算法 › 七爪源码:Python:时间复杂度 |
七爪源码:Python:时间复杂度
|
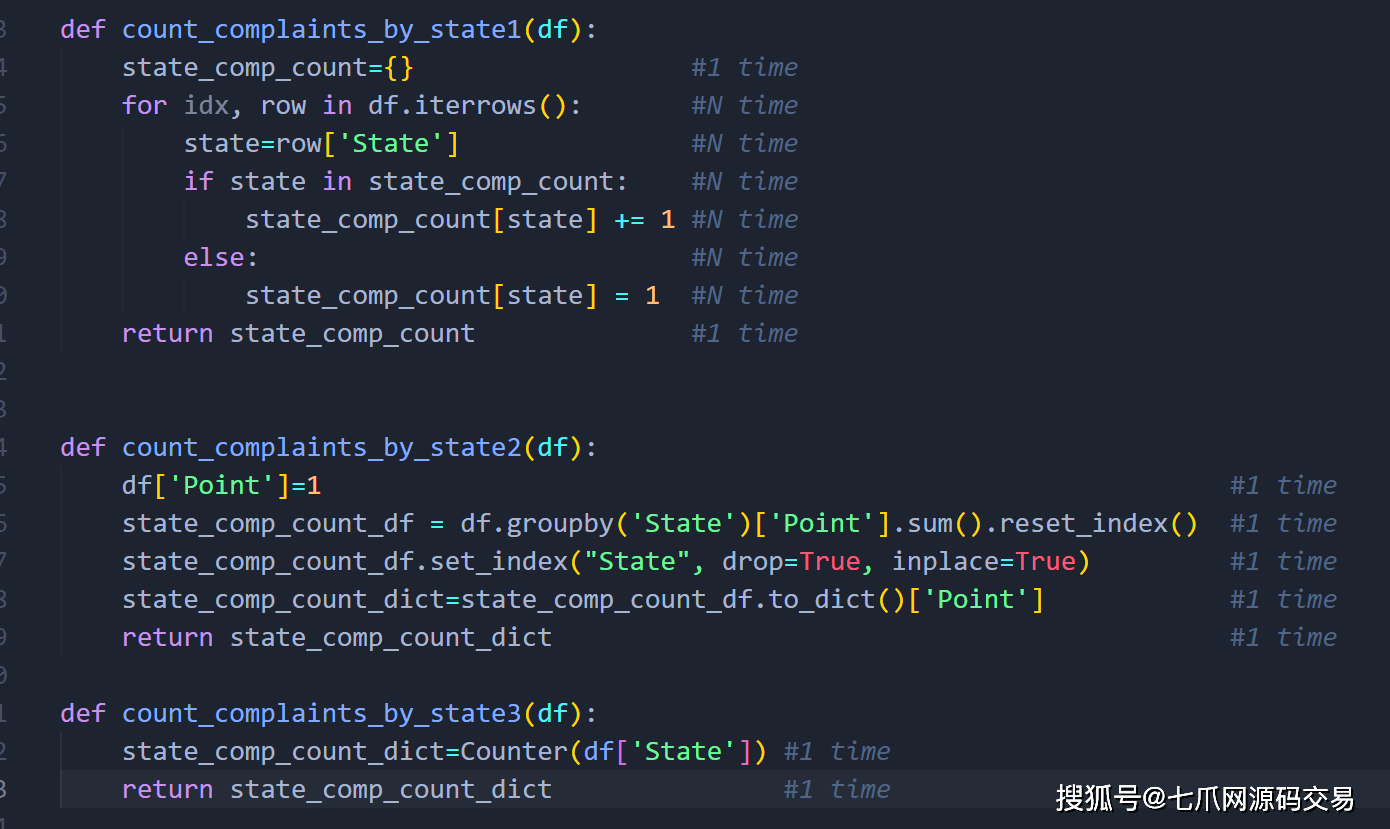
— 创建用于测试的函数/算法:
— 创建一个变量并保存算法执行前的时间,将其命名为 start1。
— 创建一个变量并保存算法执行后的时间,称之为 end1。
— start1 减去 end1 (end1 - start1) 并将差值保存到一个名为 runtime 的变量中。 此运行时是您的函数/算法执行所需的时间。
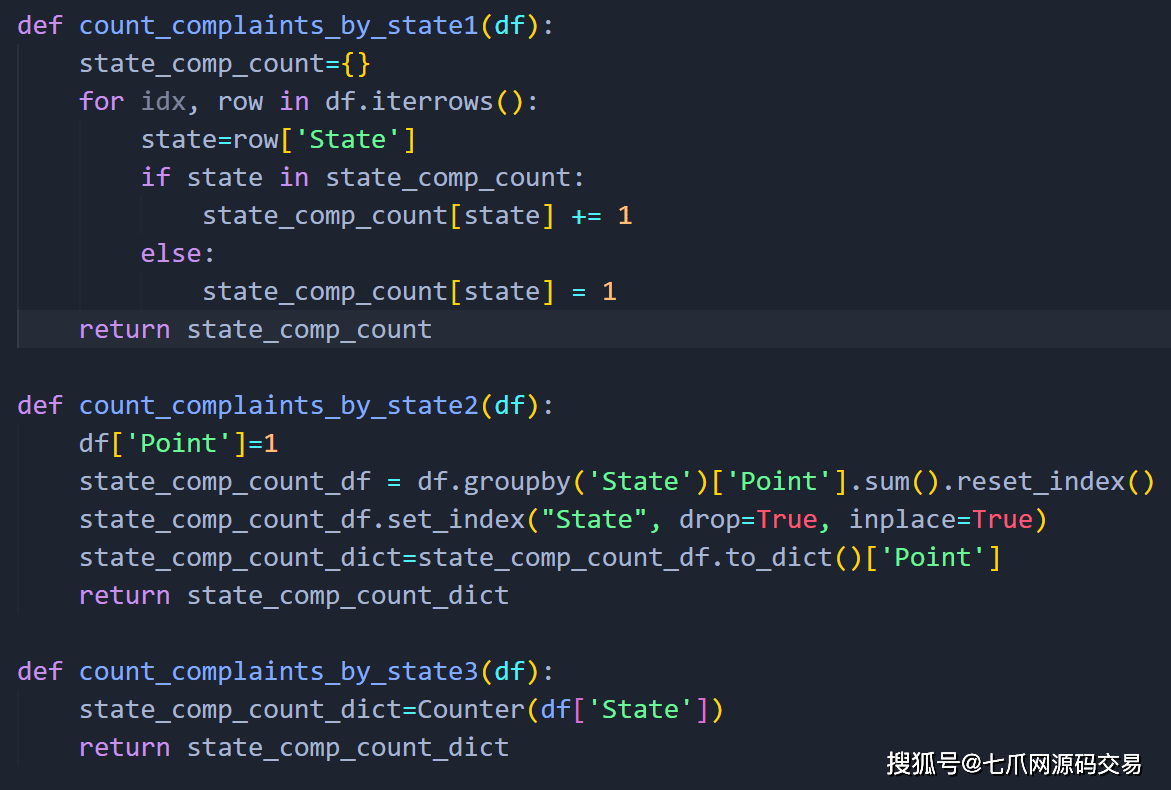
它为什么如此重要? 最终目标是能够分析和预测执行时间将如何随着数据的增长而增长。 想象一下,我们有一个包含 50 行数据的 csv 文件,并且我们有三种算法以不同的方式做同样的事情。
— 现在想象数据从 50 行增长到 500,000 行。 让我们再次运行它,看看会发生什么。
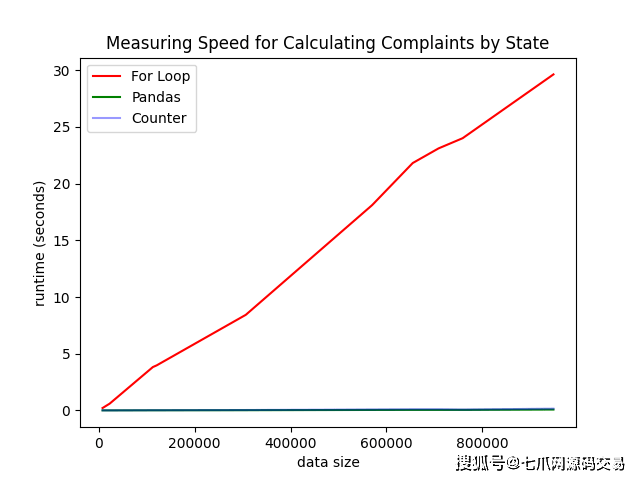
— 我们可以看到我们的运行时排名发生了变化。 当数据被缩放时,我们的 count_complaints_by_state1 函数的运行时运行最慢,而之前它排在第二位。 最后出现的 count_complaints_by_state2 现在是第一个。 由于 count_complaints_by_state2 使用 Pandas,它在内存中完成所有处理。 图表: 当您想捕捉您的算法/函数在数据扩展得更高时的表现时,最好使用某种图表(更具体地说是折线图)将它们可视化。 有一个视觉表示可以帮助我们以更少的努力获得一个总体概念,而不是比较某种桌子上的时间差异。
— 我们可以在这里看到,使用 for 循环的函数在缩放数据大小时的运行时间比其他两个要慢。 与运行时间接近 0 的数据相比,循环遍历 100 万+ 的数据需要 30 秒。 — 有点难看,但表示 pandas 函数的绿线位于 Counter 函数的蓝线下方。 请随意放大并亲自查看。 时间建模: 查看算法并从高层次上了解运行时也很重要。 这样你就可以得到一个粗略的想法,看看是否值得重新审视和优化它。 让我们学习如何对函数的时间复杂度进行建模,看看执行时间是如何增长的。
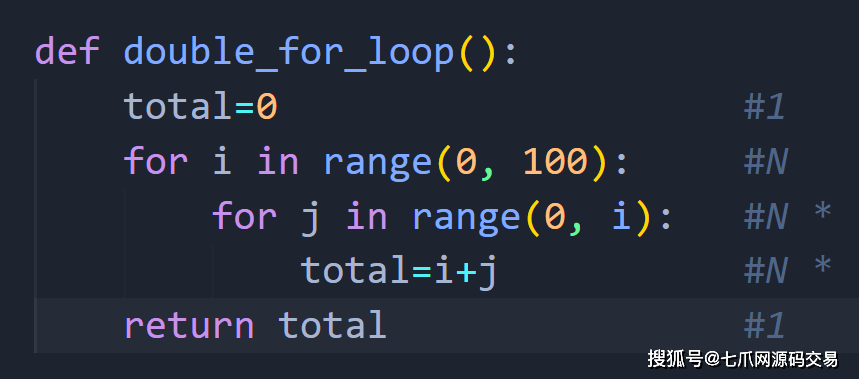
— 在查看函数中的每一行时,您假设每一行的运行时间为 1,因此为 1。当您查看 for 循环时,您假设它根据需要运行多次 数据的大小,所以我们将使用 N 来表示它。正如我们所见,count_complaints_by_state1 包含一个 for 循环,这意味着 for 循环中的每一行都执行了多次。 如果您正在处理的数据有 50 行,它将运行 50 次,如果它有 100 万行,它将运行 100 万次等等……要了解函数的实际时间复杂度,我们查看每一行 有一个恒定的运行时间 1 并添加它们。 这仅留下具有 N 运行时的行。 所以我们的函数将有 2+O(n) 的运行时间。 — 如果我们有一个嵌套的 for 循环,其中一个 for 循环在另一个循环中,那么我们将每个 for 循环的执行时间测量为 N。
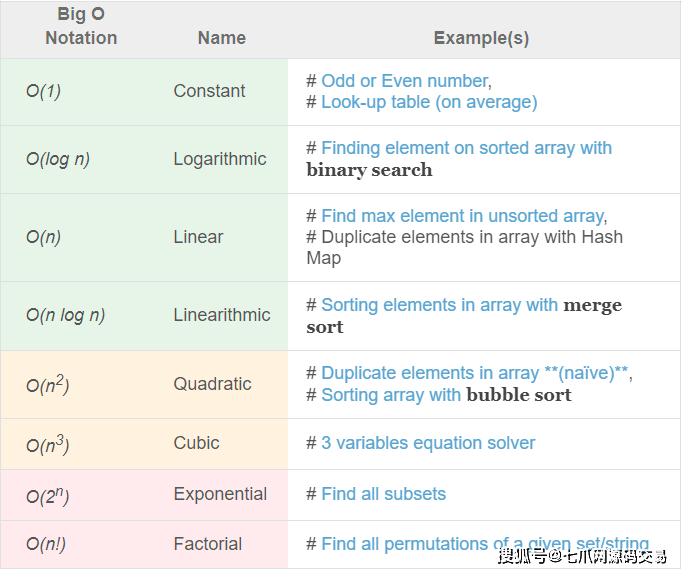
— 所以我们可以看到我们的第一个 for 循环运行 N 次或 2+O(n) 也称为线性运行时。 当我们查看嵌套的 for 循环时,它会在我们的第一个 for 循环运行之后运行多次。 因此,我们将第一个 for 循环的运行时间乘以第二个 for 循环的运行时间,(1+1)+N * N 或 2+(n^2)。 — 这是一张关于时间复杂度大 O 表示法类别的图表:
结论: 学习如何测量算法的时间复杂度是一项非常有用的技能。 它可以帮助您根据业务需求优化代码。 减少运行时间,最终更有效地做出决策。返回搜狐,查看更多 |





【本文地址】