| MySQL面试题 | 您所在的位置:网站首页 › mysql优化的面试题 › MySQL面试题 |
MySQL面试题
|
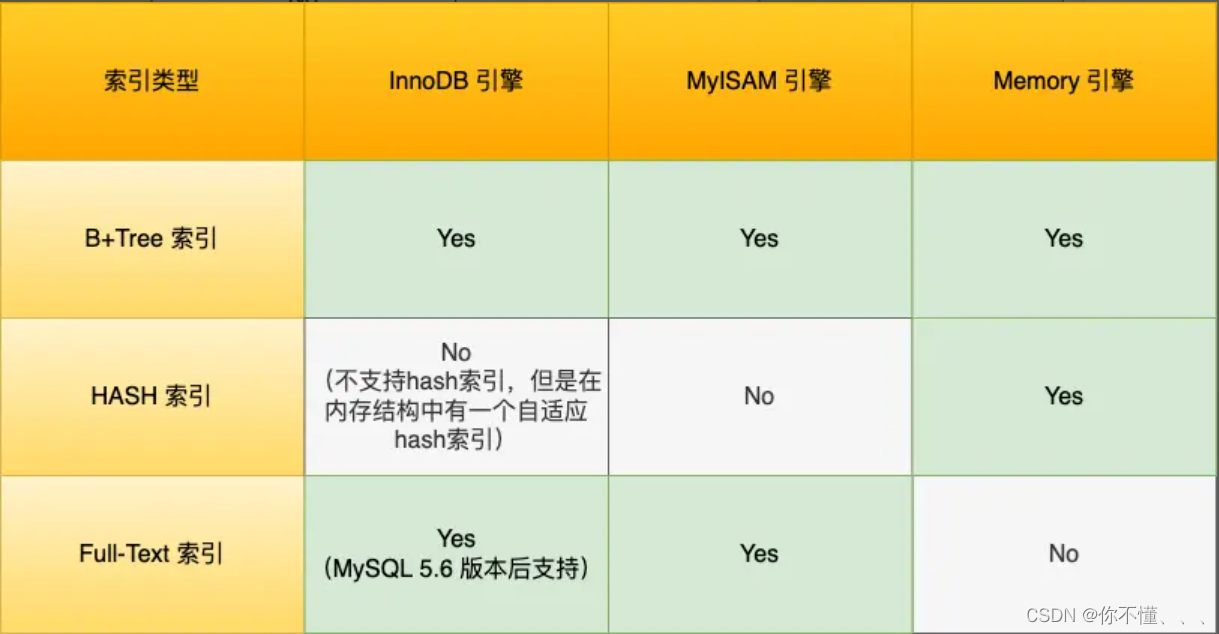
数据库中,索引的定义就是帮助存储引擎快速获取数据的一种数据结构,形象的说就是索引是数据的目录。 2、索引的分类有哪些?(1)按数据结构分类:B+Tree 索引、HASH 索引、Full-Text 索引。 主键索引的 B+Tree 的叶子节点存放的是实际数据,所有完整的用户记录都存放在主键索引的 B+Tree 的叶子节点里; 二级索引的 B+Tree 的叶子节点存放的是主键值,而不是实际数据。 聚簇索引字段选择: 01.如果有主键,默认会使用主键作为聚簇索引的索引键(key); 02.如果没有主键,就选择第一个不包含 NULL 值的唯一列作为聚簇索引的索引键(key); 03.在上面两个都没有的情况下,InnoDB 将自动生成一个隐式自增 id 列作为聚簇索引的索引键(key);
主键索引就是建立在主键字段上的索引,通常在创建表的时候一起创建,一张表最多只有一个主键索引,索引列的值不允许有空值。 唯一索引建立在 UNIQUE 字段上的索引,一张表可以有多个唯一索引,索引列的值必须唯一,但是允许有空值。 普通索引就是建立在普通字段上的索引,既不要求字段为主键,也不要求字段为 UNIQUE。 前缀索引是指对字符类型字段的前几个字符建立的索引,而不是在整个字段上建立的索引,前缀索引可以建立在字段类型为 char、 varchar、binary、varbinary 的列上。使用前缀索引的目的是为了减少索引占用的存储空间,提升查询效率。 (4)按「字段个数」分类:单列索引、联合索引。 使用联合索引时,存在最左匹配原则,也就是按照最左优先的方式进行索引的匹配。在使用联合索引进行查询的时候,如果不遵循「最左匹配原则」,联合索引会失效,这样就无法利用到索引快速查询的特性了。 (a, b, c) 联合索引,是先按 a 排序,在 a 相同的情况再按 b 排序,在 b 相同的情况再按 c 排序。所以,b 和 c 是全局无序,局部相对有序的,这样在没有遵循最左匹配原则的情况下,是无法利用到索引的。 3、联合索引的最左匹配规则与范围查询的关系(1)select from t_table where a > 1 and b = 2 ==> 只有 a 字段用到了联合索引进行索引查询,而 b 字段并没有使用到联合索引。 (2)select from t_table where a >= 1 and b = 2 ==> 这条查询语句 a 和 b 字段都用到了联合索引进行索引查询。 (3)SELECT FROM t_table WHERE a BETWEEN 2 AND 8 AND b = 2 ==> 这条查询语句 a 和 b 字段都用到了联合索引进行索引查询。 (4)SELECT FROM t_user WHERE name like ‘j%’ and age = 22 ==> 这条查询语句 a 和 b 字段都用到了联合索引进行索引查询。 综上所示,联合索引的最左匹配原则,在遇到范围查询(如 >、=、、in、between 等关键词,只检索给定范围的行,属于范围查找。从这一级别开始,索引的作用会越来越明显,因此我们需要尽量让 SQL 查询可以使用到 range 这一级别及以上的 type 访问方式。 ref 类型表示采用了非唯一索引,或者是唯一索引的非唯一性前缀,返回数据返回可能是多条。因为虽然使用了索引,但该索引列的值并不唯一,有重复。这样即使使用索引快速查找到了第一条数据,仍然不能停止,要进行目标值附近的小范围扫描。但它的好处是它并不需要扫全表,因为索引是有序的,即便有重复值,也是在一个非常小的范围内扫描。 eq_ref 类型是使用主键或唯一索引时产生的访问方式,通常使用在多表联查中。 const 类型表示使用了主键或者唯一索引与常量值进行比较 const 类型和 eq_ref 都使用了主键或唯一索引,不过这两个类型有所区别,const 是与常量进行比较,查询效率会更快,而 eq_ref 通常用于多表联查中。 8、count()函数的效率比较count() 是一个聚合函数,函数的参数不仅可以是字段名,也可以是其他任意表达式,该函数作用是统计符合查询条件的记录中,函数指定的参数不为 NULL 的记录有多少个。 效率:cout(1) = count(*) > count(主键) > count(字段) count(1)、 count(*)、 count(主键字段)在执行的时候,如果表里存在二级索引,优化器就会选择二级索引进行扫描。 所以,如果要执行 count(1)、 count(*)、 count(主键字段) 时,尽量在数据表上建立二级索引,这样优化器会自动采用 key_len 最小的二级索引进行扫描,相比于扫描主键索引效率会高一些。 再来,就是不要使用 count(字段) 来统计记录个数,因为它的效率是最差的,会采用全表扫描的方式来统计。如果你非要统计表中该字段不为 NULL 的记录个数,建议给这个字段建立一个二级索引。 |

 (2)按「物理存储」分类:聚簇索引(主键索引)、二级索引(辅助索引)。
(2)按「物理存储」分类:聚簇索引(主键索引)、二级索引(辅助索引)。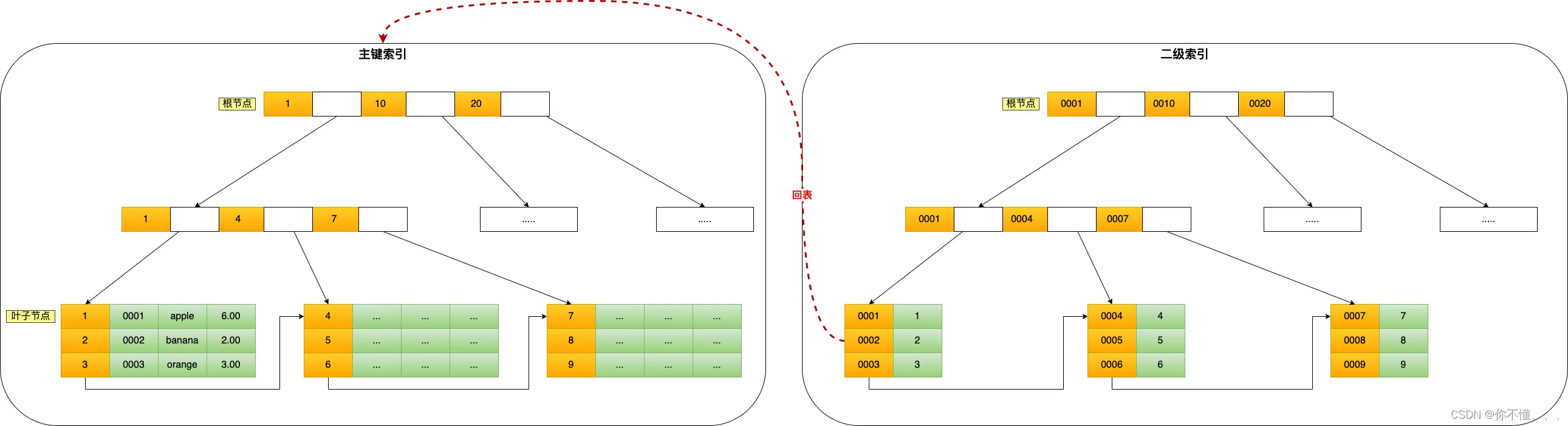 (3)按「字段特性」分类:主键索引、唯一索引、普通索引、前缀索引。
(3)按「字段特性」分类:主键索引、唯一索引、普通索引、前缀索引。【本文地址】