| MLE的数值确定:Newton | 您所在的位置:网站首页 › latticeeasy › MLE的数值确定:Newton |
MLE的数值确定:Newton
|
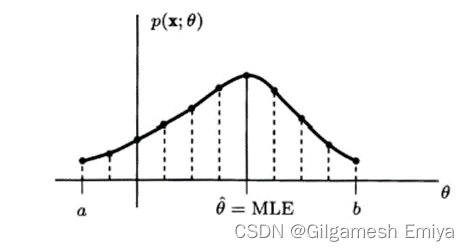
本篇随笔主要参考Steven M. Kay的《Fundamentals of Statistical Signal Processing: Estimation Theory》第七章节最大似然估计,用作为平时的学习记录。在此我们主要来分析两种迭代算法,即Newton-Raphson迭代法和得分法。相对于K的论述,本文在此补充了一些详细的推理过程和计算步骤。 MLE的一个独特的优点在于对于一个给定的数据集,总能在数值上求出他。(因为当一个已知函数即似然函数取最大值时,MLE就可确定下来)。 如果的θ可允许范围在区间[a,b]中(控制在有限区间内),那么只需在此区间上使得p(x;θ)最大即可,采用网络搜索法;(对于给定的数据集,只要θ 值的间隔足够小,我们就保证可求出其MLE;当然对于一个新的数据集,因为似然函数肯定会改变,所以将不得不重复使用网格搜寻法) remark:有些情况下我们很难知道似然函数和参数θ之间函数是什么样的,参数的取值范围、似然函数关于参数θ的单调性、极值、最值等可能会很复杂难以把握。
如果θ的范围没有控制在有限范围内,那么从数值计算角度来看,网络搜索法也许是不可行的,这种情况下可通过迭代法求最大值。此处的迭代法可以理解为一种数值最大化的技术。迭代法也存在一些问题:如果设定的初始值接近于真实最大值,那么这些方法可求出MLE,否则迭代就不会收敛,或者只会收敛到局部最大值,即事先不知道它们是否收敛,收敛的话所求的是否为MLE。 先给出问题模型:WGN中的指数信号 观测数据为 概率密度函数(PDF)为: 等效为使式子 对于J(r)求导,并令它等于零, 即 这是一个r的非线性方程,不能直接求解。 接下来以Newton-Raphson法、得分法两种迭代法入手解决该例题。(一般还会介绍EM数学期望最大算法,本文暂且不做介绍) 一、Newton-Raphson迭代法: 通过求导函数的零值而使对数似然函数最大,
接着,使用迭代方法求解此方程,令 同时,假设我们有一个求解(7.26)式的初始猜测值,将该初始猜测值称为θ0。因此,如果g(θ)在θ0附近是近似线性的,我们就能将它近似表示为 remark:对于该式,我们要联想到高等数学中的微分思想来理解。 利用上式,求解零值所对应的θ1.(因此,令g(θ1)=0并解出θ1),具体计算步骤如下,
利用这个新的猜测值θ1作为线性化点,对函数g在此进行线性化,并重复前面的方法来求新的零值。这个猜测值序列将收敛到g(θ)的真零值。 总而言之,Newton-Raphson迭代法是根据前一个猜测值
我们可以参考下图以便有更为直观的理解。(tag:上述数学式子中的dg(θ)/dθ即为下图中两个theta之间的斜率,从图中我们可以发现随着不断迭代,斜率越来越小、函数曲线越来越趋向于水平,我们越来越能够逼近所谓的真零值)
正如所期望的,迭代在
注意:关于Newton-Rapson迭代法我们还需注意两点。一是,迭代可能不收敛(修正项的起伏可能很大);二是,即使迭代收敛,求得的点也可能不是全局的最大值,而可能只是一个局部的最大值或者甚至是一个局部最小值(此情况可考虑采用多个起始点)。 在上述问题模型“WGN中的指数信号”中应用Newton-Rapson方法(具体计算步骤如下): 先计算处对数似然函数及其关于参数r的一阶、二阶导数,
代入上述通过Newton-Rapson法求得MLE的公式中,求得带估计参数r的MLE,
二、得分法 事实上,对于独立同分布(IID)样本,根据大数定理(此处指的是辛钦大数定理),对数似然函数对参数的二阶求导可近似约等于负的Fisher信息矩阵。具体如下。 首先,我们说明辛钦大数定理: 设随机变量 套用辛钦大数定理, 于是我们有如下替换,
利用它的期望值代替其二阶导数,大概率会增加迭代的稳定性。
在上述问题模型“WGN中的指数信号”中应用得分法(上述MLE式子)(具体计算步骤如下):
3、两种算法扩展至矢量情况 以上关于Newton-Rapson法和得分法都是在参数为标量情况下进行讨论的。下面将这两种算法扩展至矢量情况。 (1)Newton-Rapson迭代法
其中对数似然函数的Hessian矩阵中各元素为,
为了避免求逆矩阵,可重写上式为
通过同时求解p个联立线性方程组,新的迭代能通过前一个迭代求出。 (2)得分法 利用负的Fisher信息矩阵代替Hessian矩阵,
同样,在矢量参数情况下,这两种方法也会遇到收敛问题。 参考文献 [1]StevenM.Kay. 统计信号处理基础:估计与检测理论[M]. 电子工业出版社, 2011. |
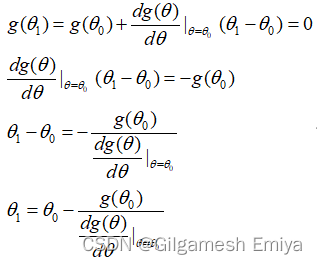



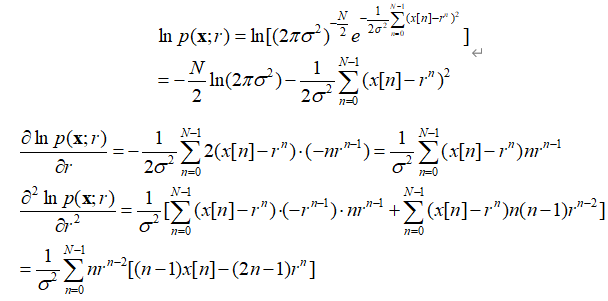
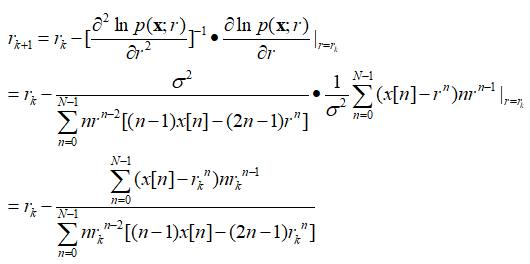
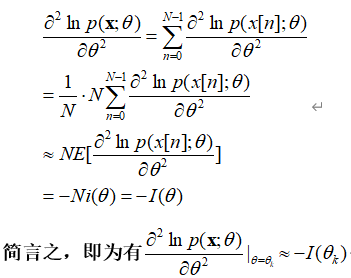
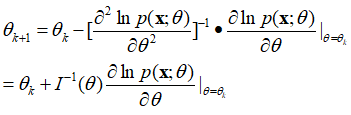
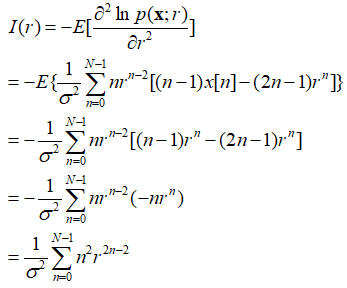
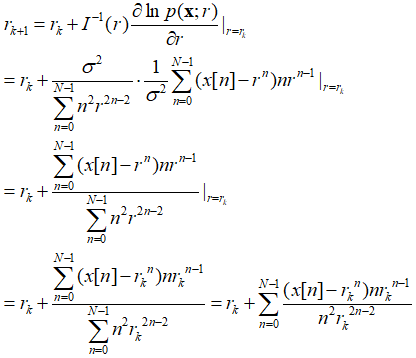

【本文地址】