| GoogLeNet在cifar10上也能达到95%准确率? | 您所在的位置:网站首页 › cifar10准确率自己训练99 › GoogLeNet在cifar10上也能达到95%准确率? |
GoogLeNet在cifar10上也能达到95%准确率?
|
Introduction
前几天看到这篇博客【深度学习】Pytorch实现CIFAR10图像分类任务测试集准确率达95%(下文统称博客1),看到博主的测试结果写了GoogLeNet竟然在测试集上能达到95.02%准确率,看了看pre-activation版本的ResNet–Identity Mappings in Deep Residual Networks中的结果: 所以对上面GoogLeNet的精度感到有点惊讶,我先自己按照原论文Going Deeper with Convolutions的结构复现了试一下结果。网络结构看这两张图就够了: 首先是Inception模块结构: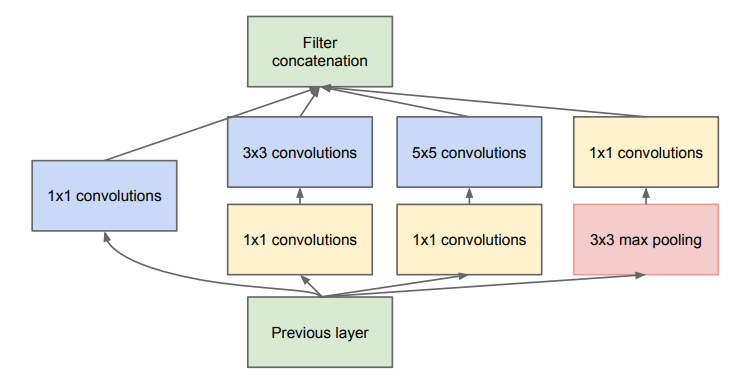 代码:
# 先写个conv-relu组合
class BasicConv2d(nn.Module):
def __init__(self, in_channels, out_channels, **kwargs):
super().__init__()
self.conv = nn.Conv2d(in_channels, out_channels, **kwargs)
self.relu = nn.ReLU(inplace=True)
def forward(self, X):
return self.relu(self.conv(X))
# Inception模块,一共四条路线branch1、2、3、4,再在通道维度cat
class Inception(nn.Module):
def __init__(self, in_channels, ch1x1, ch3x3red, ch3x3, ch5x5red, ch5x5, pool_proj):
super().__init__()
self.branch1 = BasicConv2d(in_channels, ch1x1, kernel_size=1)
self.branch2 = nn.Sequential(
BasicConv2d(in_channels, ch3x3red, kernel_size=1),
BasicConv2d(ch3x3red, ch3x3, kernel_size=3, padding=1)
)
self.branch3 = nn.Sequential(
BasicConv2d(in_channels, ch5x5red, kernel_size=1),
BasicConv2d(ch5x5red, ch5x5, kernel_size=5, padding=2)
)
self.branch4 = nn.Sequential(
nn.MaxPool2d(kernel_size=3, stride=1, padding=1),
BasicConv2d(in_channels, pool_proj, kernel_size=1)
)
def forward(self, X):
branch1 = self.branch1(X)
branch2 = self.branch2(X)
branch3 = self.branch3(X)
branch4 = self.branch4(X)
outputs = [branch1, branch2, branch3, branch4]
return torch.cat(outputs, dim=1)
然后就是网络结构参数图: 代码:
# 先写个conv-relu组合
class BasicConv2d(nn.Module):
def __init__(self, in_channels, out_channels, **kwargs):
super().__init__()
self.conv = nn.Conv2d(in_channels, out_channels, **kwargs)
self.relu = nn.ReLU(inplace=True)
def forward(self, X):
return self.relu(self.conv(X))
# Inception模块,一共四条路线branch1、2、3、4,再在通道维度cat
class Inception(nn.Module):
def __init__(self, in_channels, ch1x1, ch3x3red, ch3x3, ch5x5red, ch5x5, pool_proj):
super().__init__()
self.branch1 = BasicConv2d(in_channels, ch1x1, kernel_size=1)
self.branch2 = nn.Sequential(
BasicConv2d(in_channels, ch3x3red, kernel_size=1),
BasicConv2d(ch3x3red, ch3x3, kernel_size=3, padding=1)
)
self.branch3 = nn.Sequential(
BasicConv2d(in_channels, ch5x5red, kernel_size=1),
BasicConv2d(ch5x5red, ch5x5, kernel_size=5, padding=2)
)
self.branch4 = nn.Sequential(
nn.MaxPool2d(kernel_size=3, stride=1, padding=1),
BasicConv2d(in_channels, pool_proj, kernel_size=1)
)
def forward(self, X):
branch1 = self.branch1(X)
branch2 = self.branch2(X)
branch3 = self.branch3(X)
branch4 = self.branch4(X)
outputs = [branch1, branch2, branch3, branch4]
return torch.cat(outputs, dim=1)
然后就是网络结构参数图: 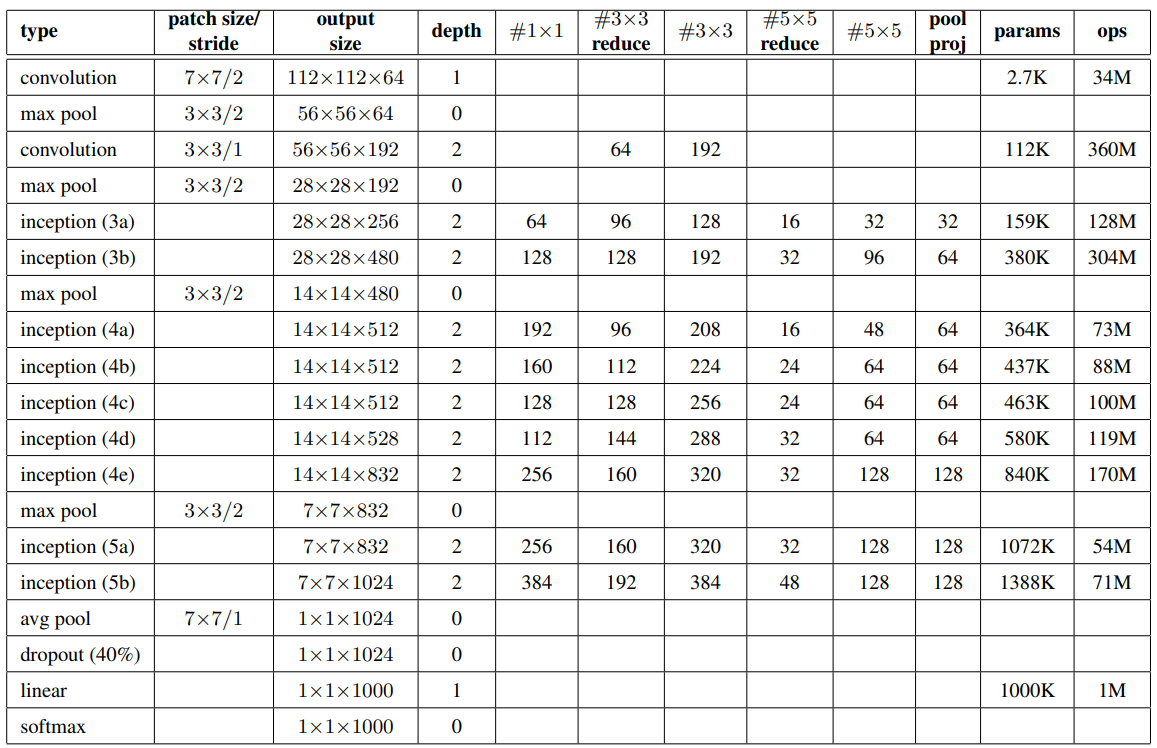 注意原文中提到GoogLeNet在训练时在inception(4a) 和 inception(4d) 后面都加了一个辅助分类器(其损失的权重都为0.3)。 辅助分类器的结构为:平均池化(5×5/3) + conv(1×1, 128) + 全连接(1024) + dropout(0.7) + 全连接(1000–imagenet有1000类),我们也加上: 注意原文中提到GoogLeNet在训练时在inception(4a) 和 inception(4d) 后面都加了一个辅助分类器(其损失的权重都为0.3)。 辅助分类器的结构为:平均池化(5×5/3) + conv(1×1, 128) + 全连接(1024) + dropout(0.7) + 全连接(1000–imagenet有1000类),我们也加上:
代码: class AuxClassifier(nn.Module): def __init__(self, in_channels, num_classes): super().__init__() self.averagePool = nn.AvgPool2d(kernel_size=5, stride=3) self.conv = BasicConv2d(in_channels, 128, kernel_size=1) self.fc1 = nn.Linear(2048, 1024) self.fc2 = nn.Linear(1024, num_classes) def forward(self, X): X = self.averagePool(X) X = self.conv(X) X = torch.flatten(X, start_dim=1) X = F.relu(self.fc1(X), inplace=True) X = F.dropout(X, 0.7, training=self.training) X = self.fc2(X) return X最后就是整个GoogLeNet: class GoogLeNet(nn.Module): def __init__(self, num_classes=10, aux_logits=False): super().__init__() self.aux_logits = aux_logits self.conv1 = BasicConv2d(3, 64, kernel_size=7, stride=2, padding=3) self.maxpool1 = nn.MaxPool2d(kernel_size=3, stride=2, ceil_mode=True) self.conv2 = BasicConv2d(64, 192, kernel_size=3, padding=1) self.maxpool2 = nn.MaxPool2d(kernel_size=3, stride=2, ceil_mode=True) self.inception3a = Inception(192, 64, 96, 128, 16, 32, 32) self.inception3b = Inception(256, 128, 128, 192, 32, 96, 64) self.maxpool3 = nn.MaxPool2d(kernel_size=3, stride=2, ceil_mode=True) self.inception4a = Inception(480, 192, 96, 208, 16, 48, 64) self.inception4b = Inception(512, 160, 112, 224, 24, 64, 64) self.inception4c = Inception(512, 128, 128, 256, 24, 64, 64) self.inception4d = Inception(512, 112, 144, 288, 32, 64, 64) self.inception4e = Inception(528, 256, 160, 320, 32, 128, 128) self.maxpool4 = nn.MaxPool2d(kernel_size=3, stride=2, ceil_mode=True) self.inception5a = Inception(832, 256, 160, 320, 32, 128, 128) self.inception5b = Inception(832, 384, 192, 384, 48, 128, 128) if self.aux_logits: # 如果加入辅助分类器 self.aux1 = AuxClassifier(512, num_classes) self.aux2 = AuxClassifier(528, num_classes) self.avgpool = nn.AdaptiveAvgPool2d((1, 1)) self.dropout = nn.Dropout(0.4) self.fc = nn.Linear(1024, num_classes) for m in self.modules(): # 这里不显式初始化的话,pytorch也是会默认kaiming初始化,但稍有一点不同 if isinstance(m, nn.Conv2d) or isinstance(m, nn.Linear): nn.init.kaiming_uniform_(m.weight, mode='fan_out', nonlinearity='relu') def forward(self, X): X = self.conv1(X) X = self.maxpool1(X) X = self.conv2(X) X = self.maxpool2(X) X = self.inception3a(X) X = self.inception3b(X) X = self.maxpool3(X) X = self.inception4a(X) if self.training and self.aux_logits: aux1 = self.aux1(X) X = self.inception4b(X) X = self.inception4c(X) X = self.inception4d(X) if self.training and self.aux_logits: aux2 = self.aux2(X) X = self.inception4e(X) X = self.maxpool4(X) X = self.inception5a(X) X = self.inception5b(X) X = self.avgpool(X) X = torch.flatten(X, start_dim=1) X = self.dropout(X) X = self.fc(X) if self.training and self.aux_logits: return X, aux2, aux1 return X上面就是论文对应的结构 cifar10数据集一共包含10个类别的RGB彩色图像,每个类别分别有6000张,共60000张大小为32×32的图片。其中50000张作为训练集,10000张作为测试集。一般会在训练集上选5000张做验证集来调参,我这里偷懒就直接用50000张训练,然后在测试集上看看结果。 我们看看如果直接将32×32×3大小的图片输入网络,在每一层的特征图大小是多少(通过torchstat这个库) # !pip install torchstat from torchstat import stat net = GoogLeNet() stat(net, (3, 32, 32))
注:epochs均为100,使用了水平翻转,图像四周会padding 4个像素,再随机crop 32×32子图 一、使用Adam(lr=0.001,最后的epoch会看情况除以10),下面batchsize=256 去除了前三个max pooling操作,保留conv1与maxpool4: - 加上辅助分类器:测试集准确率为:88.45% train_loss: 0.092 train_accuracy: 0.994 - 不加辅助分类器:测试集准确率为:88.42% train_loss: 0.019 train_accuracy: 0.993观察到辅助分类器用处不大,后面就不加辅助分类器了 可以看到与95%差距明显,于是参考博客1,将conv1的下采样取消,即,将7×7/2换成3×3/1,并恢复maxpool3 conv1换成3×3/1,恢复maxpool3: - 测试集准确率为:91.18% train_loss: 0.023 train_accuracy: 0.992很有效果,后面实验都保持这个设置 改用SGD训练: 学习率为0.0001时仍梯度爆炸,使用0.00001为初始学习率,效果不好,就没进行下去了上述最好的结果是91.18%,仍有差距,由于博客1加上了BatchNormalization,那我也加上 二、加上BN 仍用Adam 测试集准确率为:92.76% train_loss: 0.006 train_accuracy: 0.998 SGD(初始学习率为0.01,最后的epoch会看情况除以10): 测试集准确率为:88.81% train_loss: 0.040 train_accuracy: 0.987可以看到BN确实work,梯度也不爆炸了,但效果还是不够好啊,考虑博客1使用的是余弦退火,就是整个训练周期将学习率从初始学习率按照余弦曲线降低到0 SGD + 余弦退火(初始学习率为0.01): 测试集准确率为:89.56% train_loss: 0.004 train_accuracy: 0.999 test_accuracy: 0.896还是比较差,这次将学习率设为和博客1相同的0.1,以及减少batchsize到128(上面实验均为256) SGD + 余弦退火(初始学习率为0.1)+ batchsize减小到128: 测试集准确率为:95.16% train_loss: 0.0032 train_accuracy: 0.9998 test_accuracy: 0.9516wow很神奇,GoogLeNet竟然真能到 95% 以上,而且除了加上BN以及修改conv1、去除maxpool1和maxpool2之外,就没有改原始GoogLeNet任何的网络参数了(对于辅助分类器,由于有BN存在,就没必要加了) 由于用租的云跑的比较费钱,训练时可能会调一些东西,训练曲线啥的就没保存了,仅分享~ 回到最开始,就是不太明白为啥22层的GoogLeNet竟然能超过pre-activation版本的ResNet164在cifar10上的精度?(注意二者的超参数设置差不多) 代码train.py : import os import sys import torch from torch import nn from torch.utils.data import DataLoader from torchvision import datasets, transforms import torch.optim as optim from tqdm import tqdm from model import GoogLeNet def main(resume=False): device = torch.device('cuda' if torch.cuda.is_available() else 'cpu') data_transform = { 'train': transforms.Compose( [transforms.RandomCrop(32, padding=4, padding_mode='reflect'), transforms.RandomHorizontalFlip(), transforms.ToTensor(), transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010))] ), 'test': transforms.Compose( [ transforms.ToTensor(), transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010))] ) } train_dataset = datasets.CIFAR10('./', train=True, transform=data_transform['train'], download=True) test_dataset = datasets.CIFAR10('./', train=False, transform=data_transform['test'], download=True) batch_size = 128 num_workers = min([os.cpu_count(), 8]) train_loader = DataLoader(train_dataset, batch_size, shuffle=True, num_workers=num_workers) test_loader = DataLoader(test_dataset, batch_size, num_workers=num_workers) train_num, test_num = len(train_dataset), len(test_dataset) net = GoogLeNet(num_classes=10, aux_logits=False) net.to(device) epochs = 100 criterion = nn.CrossEntropyLoss() optimizer = optim.SGD(net.parameters(), lr=0.1, momentum=0.9, weight_decay=5e-4) scheduler = optim.lr_scheduler.CosineAnnealingLR(optimizer, epochs) best_acc = 0.0 save_path = './googleNet.pth' train_steps = len(train_loader) if resume: checkpoint = torch.load(save_path, map_location=device) net.load_state_dict(checkpoint['net']) best_acc = checkpoint['acc'] print(f'-----恢复上次训练, 上次准确率为{best_acc}-----') for epoch in range(epochs): net.train() running_loss = 0.0 acc = 0 train_bar = tqdm(train_loader, file=sys.stdout) for i, (X, y) in enumerate(train_bar): X, y = X.to(device), y.to(device) optimizer.zero_grad() if net.aux_logits: logits, aux_logits2, aux_logits1 = net(X) loss0 = criterion(logits, y) loss1 = criterion(aux_logits1, y) loss2 = criterion(aux_logits2, y) loss = loss0 + 0.3 * loss1 + 0.3 * loss2 else: logits = net(X) loss = criterion(logits, y) y_hat = torch.argmax(logits, dim=1) acc += (y_hat==y).sum().item() loss.backward() optimizer.step() running_loss += loss.item() tmp_lr = optimizer.param_groups[0]['lr'] train_bar.desc = f'train epoch[{epoch+1}/{epochs}] loss:{loss:.3f} lr:{tmp_lr}' train_acc = acc / train_num scheduler.step() net.eval() acc = 0 with torch.no_grad(): test_bar = tqdm(test_loader, file=sys.stdout) for X, y in test_bar: X, y = X.to(device), y.to(device) outputs = net(X) y_hat = torch.argmax(outputs, dim=1) acc += (y_hat==y).sum().item() test_acc = acc / test_num print(f'[epoch{epoch+1}/{epochs}] train_loss: {running_loss / train_steps: .4f} train_accuracy: {train_acc: .4f} test_accuracy: {test_acc: .4f}') if test_acc > best_acc: best_acc = test_acc state = { 'net': net.state_dict(), 'acc': best_acc, 'epoch': epoch } torch.save(state, save_path) if __name__ == '__main__': main()model.py: import torch from torch import nn from torch.nn import functional as F class GoogLeNet(nn.Module): def __init__(self, num_classes=10, aux_logits=False): super().__init__() self.aux_logits = aux_logits # self.conv1 = BasicConv2d(3, 64, kernel_size=7, stride=2, padding=3) self.conv1 = BasicConv2d(3, 64, kernel_size=3, padding=1) self.maxpool1 = nn.MaxPool2d(kernel_size=3, stride=2, ceil_mode=True) self.conv2 = BasicConv2d(64, 192, kernel_size=3, padding=1) self.maxpool2 = nn.MaxPool2d(kernel_size=3, stride=2, ceil_mode=True) self.inception3a = Inception(192, 64, 96, 128, 16, 32, 32) self.inception3b = Inception(256, 128, 128, 192, 32, 96, 64) self.maxpool3 = nn.MaxPool2d(kernel_size=3, stride=2, ceil_mode=True) self.inception4a = Inception(480, 192, 96, 208, 16, 48, 64) self.inception4b = Inception(512, 160, 112, 224, 24, 64, 64) self.inception4c = Inception(512, 128, 128, 256, 24, 64, 64) self.inception4d = Inception(512, 112, 144, 288, 32, 64, 64) self.inception4e = Inception(528, 256, 160, 320, 32, 128, 128) self.maxpool4 = nn.MaxPool2d(kernel_size=3, stride=2, ceil_mode=True) self.inception5a = Inception(832, 256, 160, 320, 32, 128, 128) self.inception5b = Inception(832, 384, 192, 384, 48, 128, 128) if self.aux_logits: self.aux1 = AuxClassifier(512, num_classes) self.aux2 = AuxClassifier(528, num_classes) self.avgpool = nn.AdaptiveAvgPool2d((1, 1)) self.dropout = nn.Dropout(0.4) self.fc = nn.Linear(1024, num_classes) for m in self.modules(): if isinstance(m, nn.Conv2d) or isinstance(m, nn.Linear): nn.init.kaiming_uniform_(m.weight, mode='fan_out', nonlinearity='relu') def forward(self, X): X = self.conv1(X) # X = self.maxpool1(X) X = self.conv2(X) # X = self.maxpool2(X) X = self.inception3a(X) X = self.inception3b(X) X = self.maxpool3(X) X = self.inception4a(X) if self.training and self.aux_logits: aux1 = self.aux1(X) X = self.inception4b(X) X = self.inception4c(X) X = self.inception4d(X) if self.training and self.aux_logits: aux2 = self.aux2(X) X = self.inception4e(X) X = self.maxpool4(X) X = self.inception5a(X) X = self.inception5b(X) X = self.avgpool(X) X = torch.flatten(X, start_dim=1) X = self.dropout(X) X = self.fc(X) if self.training and self.aux_logits: return X, aux2, aux1 return X class Inception(nn.Module): def __init__(self, in_channels, ch1x1, ch3x3red, ch3x3, ch5x5red, ch5x5, pool_proj): super().__init__() self.branch1 = BasicConv2d(in_channels, ch1x1, kernel_size=1) self.branch2 = nn.Sequential( BasicConv2d(in_channels, ch3x3red, kernel_size=1), BasicConv2d(ch3x3red, ch3x3, kernel_size=3, padding=1) ) self.branch3 = nn.Sequential( BasicConv2d(in_channels, ch5x5red, kernel_size=1), BasicConv2d(ch5x5red, ch5x5, kernel_size=5, padding=2) ) self.branch4 = nn.Sequential( nn.MaxPool2d(kernel_size=3, stride=1, padding=1), BasicConv2d(in_channels, pool_proj, kernel_size=1) ) def forward(self, X): branch1 = self.branch1(X) branch2 = self.branch2(X) branch3 = self.branch3(X) branch4 = self.branch4(X) outputs = [branch1, branch2, branch3, branch4] return torch.cat(outputs, dim=1) class AuxClassifier(nn.Module): def __init__(self, in_channels, num_classes): super().__init__() self.averagePool = nn.AvgPool2d(kernel_size=5, stride=3) self.conv = BasicConv2d(in_channels, 128, kernel_size=1) self.fc1 = nn.Linear(2048, 1024) self.fc2 = nn.Linear(1024, num_classes) def forward(self, X): X = self.averagePool(X) X = self.conv(X) X = torch.flatten(X, start_dim=1) X = F.relu(self.fc1(X), inplace=True) X = F.dropout(X, 0.7, training=self.training) X = self.fc2(X) return X class BasicConv2d(nn.Module): def __init__(self, in_channels, out_channels, **kwargs): super().__init__() self.conv = nn.Conv2d(in_channels, out_channels, **kwargs) self.bn = nn.BatchNorm2d(out_channels) self.relu = nn.ReLU(inplace=True) def forward(self, X): return self.relu(self.bn(self.conv(X))) if __name__ == '__main__': from torchstat import stat net = GoogLeNet() stat(net, (3, 32, 32)) |
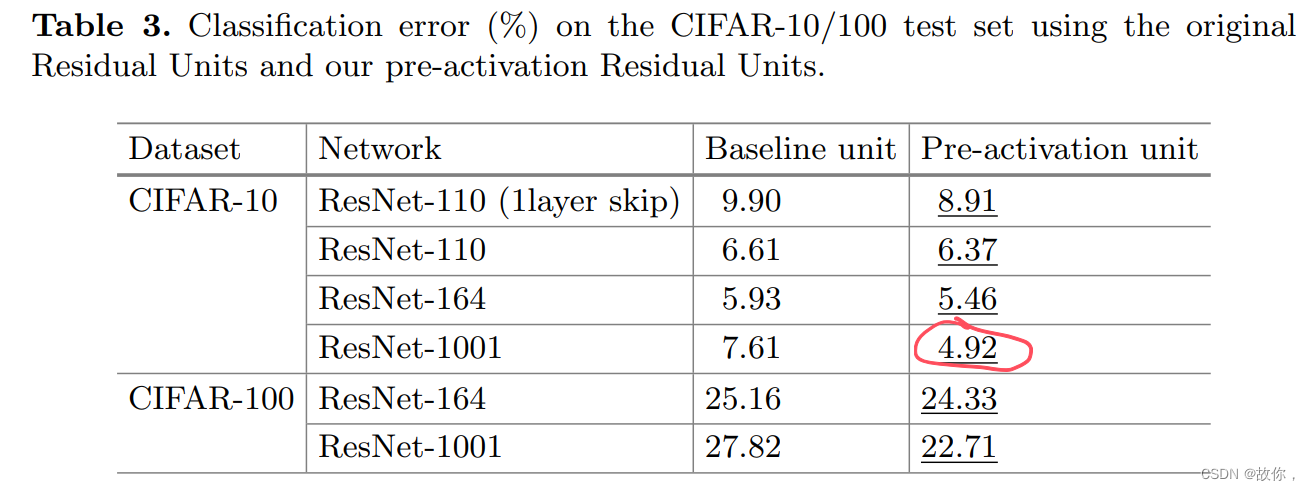 【顺便注意下这篇论文中的cifar10实验参数:训练过程中学习率为0.1到0.01到0.001 + 图像增强(水平翻转和平移)+ 初始的400个iterations用lr=0.01来warm up + batchsize为128 + weight decay为1e-4 + momentum为0.9 + 不使用dropout】
【顺便注意下这篇论文中的cifar10实验参数:训练过程中学习率为0.1到0.01到0.001 + 图像增强(水平翻转和平移)+ 初始的400个iterations用lr=0.01来warm up + batchsize为128 + weight decay为1e-4 + momentum为0.9 + 不使用dropout】 网络的下采样地方有conv1、maxpool1、maxpool2、maxpool3、maxpool4,对于32×32大小的图片,经过maxpool2就变成4×4大小了,保存的信息太少,因此我们去除其中三个下采样操作(这样在全局平均池化之前特征图大小为8×8)。
网络的下采样地方有conv1、maxpool1、maxpool2、maxpool3、maxpool4,对于32×32大小的图片,经过maxpool2就变成4×4大小了,保存的信息太少,因此我们去除其中三个下采样操作(这样在全局平均池化之前特征图大小为8×8)。【本文地址】