| Key Issues Associated with Classification Accuracy | 您所在的位置:网站首页 › acccuracy › Key Issues Associated with Classification Accuracy |
Key Issues Associated with Classification Accuracy
|
Key Issues Associated with Classification Accuracy
In this blog, we will unfold the key problems associated with classification accuracies, such as imbalanced classes, overfitting, and data bias, and proven ways to address those issues successfully. By Ayesha Saleem, Digital Content Writer at Data Science Dojo on March 6, 2023 in Machine Learning
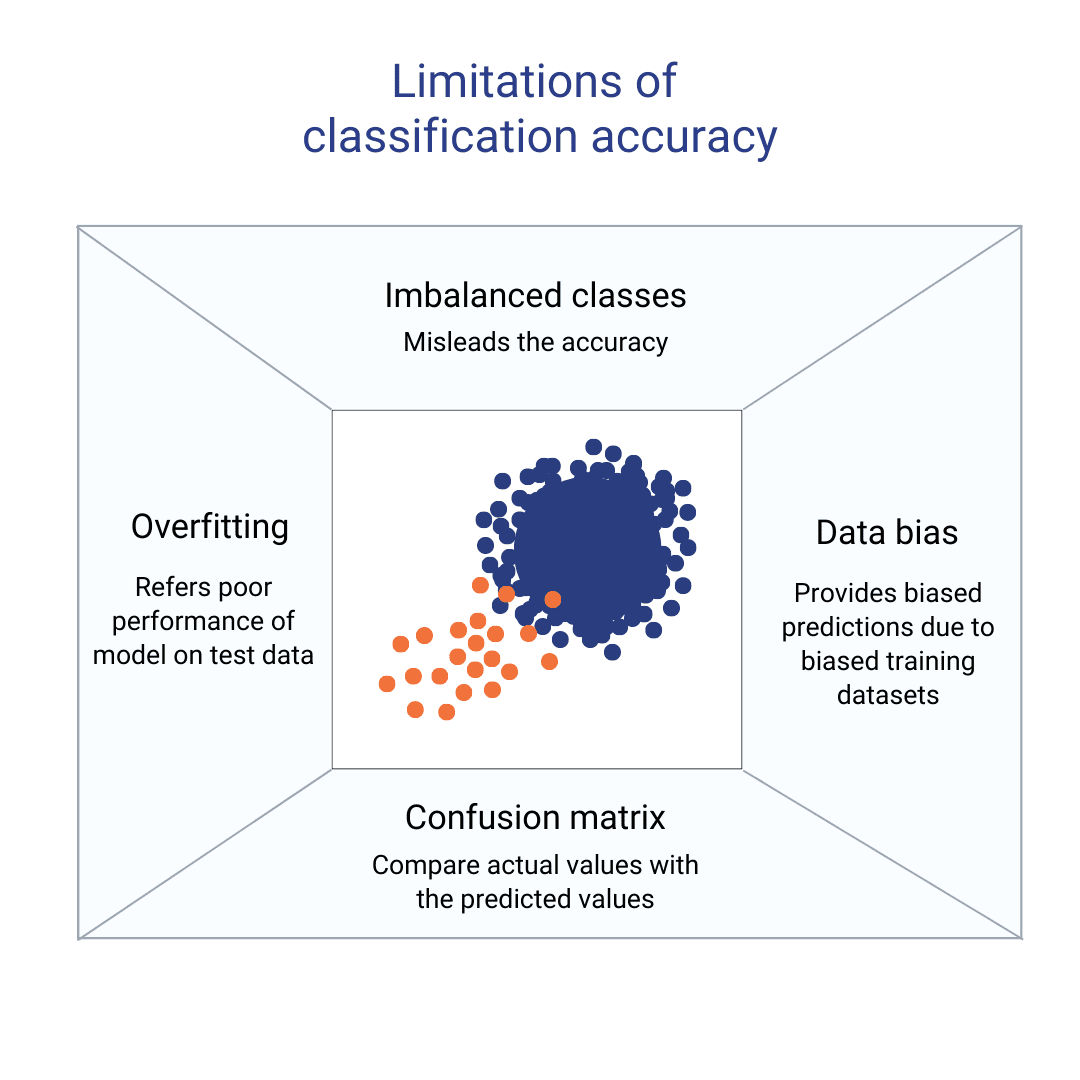 Image by Author
Imbalanced Classes
Image by Author
Imbalanced Classes
The accuracy may be deceptive if the dataset contains classifications that are uneven. For instance, a model that merely predicts the majority class will be 99% accurate if the dominant class comprises 99% of the data. Unfortunately, it will not be able to appropriately classify the minority class. Other metrics including precision, recall, and F1-score should be used to address this issue. The 5 most common techniques that can be used to address the problem of imbalanced class in classification accuracy are:
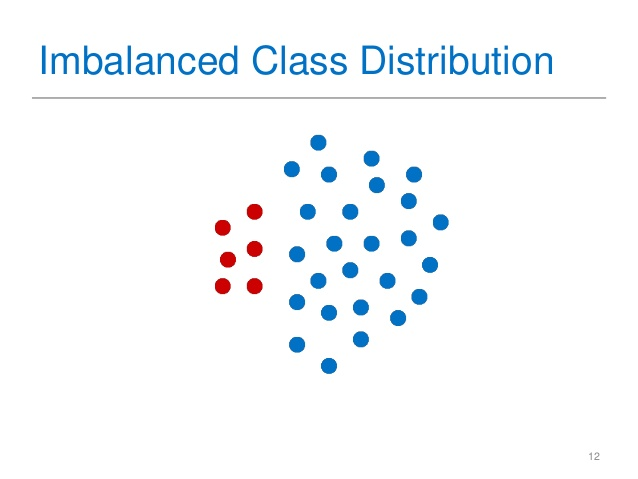 Imbalanced class | Knowledge Engineering
Upsampling the minority class: In this technique, we duplicate the examples in the minority class to balance the class distribution.
Downsampling the majority class: In this technique we remove examples from the majority class to balance the class distribution.
Synthetic data generation: A technique used to generate new samples of the minority class. When random noise is introduced to the existing examples or by generating new examples through interpolation or extrapolation then synthetic data generation takes place.
Anomaly detection: The minority class is treated as an anomaly in this technique whereas the majority class is treated as the normal data.
Changing the decision threshold: This technique adjusts the decision threshold of the classifier to increase the sensitivity to the minority class.
Imbalanced class | Knowledge Engineering
Upsampling the minority class: In this technique, we duplicate the examples in the minority class to balance the class distribution.
Downsampling the majority class: In this technique we remove examples from the majority class to balance the class distribution.
Synthetic data generation: A technique used to generate new samples of the minority class. When random noise is introduced to the existing examples or by generating new examples through interpolation or extrapolation then synthetic data generation takes place.
Anomaly detection: The minority class is treated as an anomaly in this technique whereas the majority class is treated as the normal data.
Changing the decision threshold: This technique adjusts the decision threshold of the classifier to increase the sensitivity to the minority class.
Overfitting
When a model is overtrained on the training data and underperforms on the test data, it is said to be overfit. As a result, the accuracy may be high on the training set but poor on the test set. Techniques like cross-validation and regularisation should be applied to solve this issue.
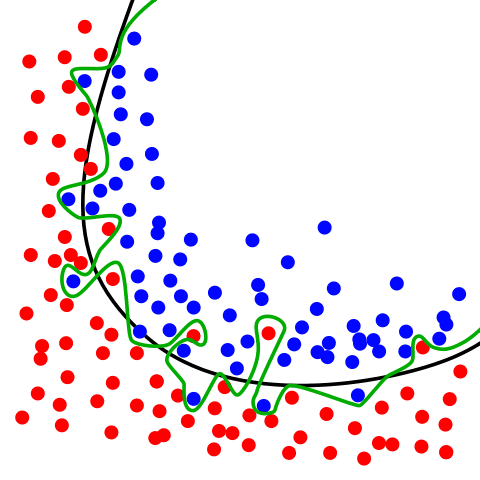 Overfitting | Freepik
Overfitting | Freepik
There are several techniques that can be used to address overfitting. Train the model with more data: This allows the algorithm to detect the signal better and minimize errors. Regularization: This involves adding a penalty term to the cost function during training, which helps to constrain the model's complexity and reduce overfitting. Cross-validation: This technique helps evaluate the model's performance by dividing the data into training and validation sets, and then training and evaluating the model on each set. Ensemble methods. This is a technique that involves training multiple models and then combining their predictions, which helps to reduce the variance and bias of the model.Data Bias
The model will produce biased predictions if the training dataset is biassed. High accuracy on the training data may result from this, but performance on untrained data may be subpar. Techniques like data augmentation and resampling should be utilised to address this issue. Some other ways to address this problem are listed below:
 Data Bias | Explorium
One technique is to ensure that the data used is representative of the population it is intended to model. This can be done by randomly sampling data from the population, or by using techniques such as oversampling or under sampling to balance the data.
Test and evaluate the models carefully by measuring accuracy levels for different demographic categories and sensitive groups. This can help identify any biases in the data and the model and address them.
Be aware of observer bias, which happens when you impose your opinions or desires on data, whether consciously or accidentally. This can be done by being aware of the potential for bias, and by taking steps to minimize it.
Use preprocessing techniques to remove or correct data bias. For example, using techniques such as data cleaning, data normalization, and data scaling.
Data Bias | Explorium
One technique is to ensure that the data used is representative of the population it is intended to model. This can be done by randomly sampling data from the population, or by using techniques such as oversampling or under sampling to balance the data.
Test and evaluate the models carefully by measuring accuracy levels for different demographic categories and sensitive groups. This can help identify any biases in the data and the model and address them.
Be aware of observer bias, which happens when you impose your opinions or desires on data, whether consciously or accidentally. This can be done by being aware of the potential for bias, and by taking steps to minimize it.
Use preprocessing techniques to remove or correct data bias. For example, using techniques such as data cleaning, data normalization, and data scaling.
Confusion Matrix
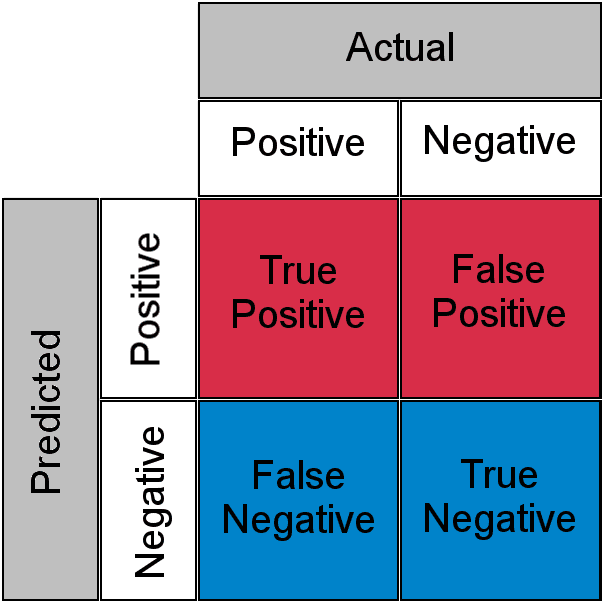 Image by Author
Image by Author
A classification algorithm's performance is described using a confusion matrix. It is a table layout where real values are contrasted with anticipated values in the matrix to define the performance of a classification algorithm. Some ways to address this problem are: Analyze the values in the matrix and identify any patterns or trends in the errors. For example, if there are many false negatives, it might indicate that the model is not sensitive enough to certain classes. Use metrics like precision, recall, and F1-score to evaluate the model's performance. These metrics provide a more detailed understanding of how the model is performing and can help to identify any specific areas where the model is struggling. Adjust the threshold of the model, if the threshold is too high or too low, this can cause the model to make more false positives or false negatives. Use ensemble methods, such as bagging and boosting, which can help improve the model's performance by combining the predictions of multiple models.Learn more about confusion matrix in this video Contribution of Classification Accuracy in Machine Learning
In conclusion, classification accuracy is a helpful metric for assessing a machine learning model's performance, but it can be deceptive. To acquire a more thorough perspective of the model's performance, additional metrics including precision, recall, F1-score, and confusion matrix should also be used. To overcome issues like imbalanced classes, overfitting, and data bias, techniques including cross-validation, normalisation, data augmentation, and re-sampling should be applied. Ayesha Saleem Possess a passion for revamping the brands with meaningful Content Writing, Copywriting, Email Marketing, SEO writing, Social Media Marketing, and Creative Writing. More On This TopicClassification Metrics Walkthrough: Logistic Regression with Accuracy,…10 Most Common Data Quality Issues and How to Fix ThemOvercome Your Data Quality Issues with Great ExpectationsWhich Metric Should I Use? Accuracy vs. AUCFree From Stanford: Ethical and Social Issues in Natural Language…A Deep Learning Dream: Accuracy and Interpretability in a Single Model Next post =>Top Posts Past 30 Days SQL and Python Interview Questions for Data Analysts ChatGPT for Data Science Cheat Sheet The ChatGPT Cheat Sheet 4 Ways to Rename Pandas Columns 5 Free Tools For Detecting ChatGPT, GPT3, and GPT2 Learn Machine Learning From These GitHub Repositories How to Select Rows and Columns in Pandas Using [ ], .loc, iloc, .at and .iat ChatGPT as a Python Programming Assistant 5 SQL Visualization Tools for Data Engineers Top Free Resources To Learn ChatGPT |
【本文地址】