|
操作系统实验三:内存管理(动态分区分配方式的模拟)
资源下载:https://download.csdn.net/download/fufuyfu/85511547?spm=1001.2014.3001.5503
一、实验内容:
了解动态分区分配方式中的数据结构和分配算法,并进一步加深对动态分区存储管理方式及其实现过程的理解
二、实验要求:
用C语言分别实现采用首次适应算法和最佳适应算法的动态分区分配过程和回收过程。其中,空闲分区通过空闲分区链(表)来管理;在进行内存分配时,系统优先使用空闲区低端的空间。 假设初始状态下,可用的内存空间为640KB,并有下列的请求序列:
请求顺序操作请求内存大小(KB)作业1申请130作业2申请60作业3申请100作业4释放60作业5申请200作业6释放100作业7释放130作业8申请140作业8申请60作业8申请50作业8申请60
要求每次分配和回收后显示出作业分配情况及空闲内存分区链的情况。
三、算法流程:
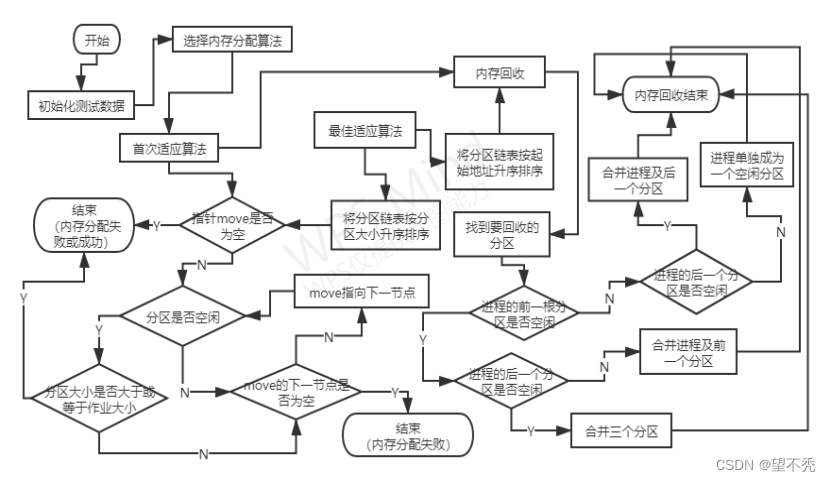
3.1 头文件和数据结构
#include
#include
typedef struct nodespace{
int num; // 分区号
int begin; // 起始地址
int size; // 分区大小
int status; // 状态:0代表空闲,1代表占用
int teskid; // 作业id
struct nodespace *next; // 后向指针
}Node;
3.2 函数声明
// 方法声明
// 初始化分区
void initNode(Node *p);
// 首次适应算法
void first_fit(int teskid,int size,Node *node);
// 最佳适应算法
Node *best_fit(int teskid,int size,Node *node);
// 按起始地址大小对链表进行排序
Node *sort_begin(Node *node);
// 按分区大小对链表进行排序
Node *sort_size(Node *node);
// 回收内存
void recycle(int teskid,Node *node);
// 确定分区号
void set_num(Node *node);
// 查看作业分配情况及空闲内存分区链
void printNode(Node *node);
3.3 主函数
// 主函数
int main(){
// node为整个空间
Node *init = (Node*)malloc(sizeof(Node));
Node *node = NULL;
// 初始化主链
initNode(init);
// 指向链表头
node = init;
printf("\n-------------------初始状态下,可用的内存空间为640KB-------------------\n");
// 选择分配算法或退出操作
printf("\n请选择算法或退出操作:");
printf("\n\t1.首次适应算法");
printf("\n\t2.最佳适应算法");
printf("\n\t3.退出");
printf("\n\t请输入有效编号:");
int option;
scanf("%d",&option);
getchar();
printf("\n");
//首次适应算法
if(option == 1){
printf("作业1 申请130KB\n");
first_fit(1,130,node); //作业1 申请130 KB
printf("作业2 申请60KB\n");
first_fit(2,60,node); //作业2 申请60 KB
printf("作业3 申请100KB\n");
first_fit(3,100,node); //作业3 申请100 KB
printf("作业2 释放60KB\n");
recycle(2,node); //作业2 释放60 KB
printf("作业4 申请200KB\n");
first_fit(4,200,node); //作业4 申请200 KB
printf("作业3 释放100KB\n");
recycle(3,node); //作业3 释放100 KB
printf("作业1 释放130KB\n");
recycle(1,node); //作业1 释放130 KB
printf("作业5 申请140KB\n");
first_fit(5,140,node); //作业5 申请140 KB
printf("作业6 申请60KB\n");
first_fit(6,60,node); //作业6 申请60 KB
printf("作业7 申请50KB\n");
first_fit(7,50,node); //作业7 申请50 KB
printf("作业8 申请60KB\n");
first_fit(8,60,node); //作业8 申请60 KB
}else if(option == 2){
// 最佳适应算法在申请前要对空闲分区链表根据分区大小重新进行排序
// 在释放前要对空闲分区链表根据起始地址重新进行排序
printf("作业1 申请130KB\n");
node = best_fit(1,130,node); //作业1 申请130KB
printf("作业2 申请60KB\n");
node = best_fit(2,60,node); //作业2 申请60KB
printf("作业3 申请100KB\n");
node = best_fit(3,100,node); //作业3 申请100KB
printf("作业2 释放60KB\n");
node = sort_begin(node);
recycle(2,node); //作业2 释放60KB
printf("作业4 申请200KB\n");
node = best_fit(4,200,node); //作业4 申请200KB
printf("作业3 释放100KB\n");
node = sort_begin(node);
recycle(3,node); //作业3 释放100KB
printf("作业1 释放130KB\n");
recycle(1,node); //作业1 释放130KB
printf("作业5 申请140KB\n");
node = best_fit(5,140,node); //作业5 申请140KB
printf("作业6 申请60KB\n");
node = best_fit(6,60,node); //作业6 申请60KB
printf("作业7 申请50KB\n");
node = best_fit(7,50,node); //作业7 申请50KB
printf("作业8 申请60KB\n");
node = best_fit(8,60,node); //作业8 申请60KB
}else if(option == 3){ //退出
printf("退出操作成功!");
}else{
printf("您的输入有误,请重新输入!\n");
}
return 0;
}
3.4 初始化分区
// 初始化分区
void initNode(Node *p){
if(p == NULL){
//如果为空则新创建一个
p = (Node*)malloc(sizeof(Node));
}
// 分区号
p->num = 1;
// 起始地址
p->begin = 0;
// 分区大小
p->size = 640;
// 状态:0代表空闲,1代表占用
p->status = 0;
// 作业id
p->teskid = -1;
// 后向指针
p->next = NULL;
}
3.5 首次适应算法
// 首次适应算法
void first_fit(int teskid,int size,Node *node){
Node *move = node;
// 空闲内存分区链不为空
while(move != NULL){
// 空闲的空间
if(move->status == 0){
// 剩余空间大于作业需要的内存空间,可分配
if(move->size > size){
// 分配后剩余的空间
Node *p = (Node*)malloc(sizeof(Node));
p->begin = move->begin + size;
p->size = move->size - size;
p->status = 0;
p->teskid = -1;
// 分配的空间
move->teskid = teskid;
move->size = size;
move->status = 1;
// 改变节点的连接
p->next = move->next;
move->next = p;
break;
}else if(move->size == size){
// 空闲空间和作业需要的内存空间大小相等时,可分配
move->teskid = teskid;
move->size = size;
move->status = 1;
break;
}
}
// 已到空闲内存分区链末尾
if(move->next == NULL){
printf("内存分配失败,没有足够大的内存分配给该作业!\n");
break;
}
move = move->next;
}
set_num(node);
printNode(node);
}
3.6 最佳适应算法
// 最佳适应算法
Node *best_fit(int teskid,int size,Node *node){
node = sort_size(node);
printNode(node);
first_fit(teskid,size,node);
return node;
}
3.7 按起始地址对链表进行排序
// 按起始地址对链表进行排序
Node *sort_begin(Node *node){
// 定位原链表起始地址最小的结点
Node *firstest = node;
// 移动指针
Node *p = node;
// 从原链表拆下来的起始地址最小的结点
Node *newlastnode = NULL;
// 新链表
Node *newnode = NULL;
// 定位新链表的最后一个结点
Node *lastnode = NULL;
// 直到原链表为空结束
while(node != NULL){
// 找出原链表起始地址最小的结点
int first = p->begin;
while(p != NULL){
if(p->begin
newlastnode = firstest;
// 修改原链表
node = node->next;
}else{
newlastnode = firstest;
// 修改原链表
Node *move = node;
// 定位分区最小的结点前一个节点
while(move->next != firstest){
move = move->next;
}
move->next = firstest->next;
}
// 将从原链表拆下来的分区最小的结点接入新链表末尾
if(newnode == NULL){
// 新链表第一个节点
newnode = newlastnode;
lastnode = newlastnode;
}else{
lastnode->next = newlastnode;
lastnode = newlastnode;
}
// 更新shortest和p指向node的第一个节点
firstest = node;
p = node;
}
return newnode;
}
3.8 按分区大小对链表进行排序
// 按分区大小对链表进行排序
Node *sort_size(Node *node){
// 定位原链表分区最小的结点
Node *shortest = node;
// 移动指针
Node *p = node;
// 从原链表拆下来的分区最小的结点
Node *newlastnode = NULL;
// 新链表
Node *newnode = NULL;
// 定位新链表的最后一个结点
Node *lastnode = NULL;
// 直到原链表为空结束
while(node != NULL){
// 找出原链表分区最小的结点
int small_size = p->size;
while(p != NULL){
if(p->size
newlastnode = shortest;
// 修改原链表
node = node->next;
}else{
newlastnode = shortest;
// 修改原链表
Node *move = node;
// 定位分区最小的结点前一个节点
while(move->next != shortest){
move = move->next;
}
move->next = shortest->next;
}
// 将从原链表拆下来的分区最小的结点接入新链表末尾
if(newnode == NULL){
// 新链表第一个节点
newnode = newlastnode;
lastnode = newlastnode;
}else{
lastnode->next = newlastnode;
lastnode = newlastnode;
}
// 更新shortest和p指向node的第一个节点
shortest = node;
p = node;
}
return newnode;
}
3.9 回收内存
// 回收内存
void recycle(int teskid,Node *node){
Node *move = node;
if(move->next == NULL && move->teskid == -1){
printf("还没有分配任何作业!\n");
}
while(move != NULL){
// 当move指向需释放空间的前移结点
// 需释放空间的上一块空间空闲时
if(move->status == 0 && move->next->status == 1 && move->next->teskid == teskid){
// 合并需释放空间上一块空间与需释放空间
move->size = move->size + move->next->size;
Node *q = move->next;
move->next = move->next->next;
// 释放内存
free(q);
if(move->next->status == 0){
// 需释放空间的下一个空间也是空闲空间时
move->size = move->size + move->next->size;
Node *q = move->next;
move->next = move->next->next;
free(q);
}
break;
}else if(move->status == 1 && move->teskid == teskid){
// 需释放空间的上一块空间不是空闲空间时
move->status = 0;
move->teskid = -1;
if(move->next != NULL && move->next->status == 0){
// 需释放空间的下一块空间是空闲空间时
move->size = move->size + move->next->size;
Node *q = move->next;
move->next = move->next->next;
free(q);
}
break;
}else if(move->next == NULL){
// 已走到链表末尾,此时表明任务id都不匹配
printf("此任务不存在!\n");
break;
}
move = move->next;
}
set_num(node);
printNode(node);
}
3.10 确定分区号
// 确定分区号
void set_num(Node *node){
int i = 1;
while(node != NULL){
node->num = i++;
node = node->next;
}
}
3.11 查看作业分配情况及空闲内存分区链
// 查看作业分配情况及空闲内存分区链
void printNode(Node *node){
printf(" -----------------------------------------------------------------------\n");
printf(" 作业分配情况及空闲内存分区链 \n");
printf(" -----------------------------------------------------------------------\n");
printf("| 分区号\t起始地址\t结束地址\t大小\t状态\t作业id\t|\n");
while(node != NULL){
if(node->status == 0){
printf("|%4d\t\t%5d\t\t%5d\t\t%dKB\tfree\t 无\t|\n",node->num,node->begin+1,node->begin+node->size,node->size);
}else{
printf("|%4d\t\t%5d\t\t%5d\t\t%dKB\tbusy\t %d\t|\n",node->num,node->begin+1,node->begin+node->size,node->size,node->teskid);
}
node = node->next;
}
printf(" -----------------------------------------------------------------------\n");
}
四、实验结果:
代码注释非常详尽,可自行运行截图
五、分析:
首次适应算法(first fit)和最佳适应算法(next fit)都是基于顺序搜索的动态分区分配算法,这两种算法都是从空闲分区链的开头开始查找符合该算法要求的分区为作业(进程)进行内存分配。两种算法内存分配的要求有所不同,其中首次适应算法要求找到空闲分区链中符合内存大小要求的分区空间即可,此时空闲分区链仅需以地址递增的次序链接,说明该算法优先利用内存中低址部分的空闲分区,虽然这样保留了高址部分的大空闲区为以后到达的大作业分配大的内存空间创造了条件,但低址部分不断被划分,会留下许多难以利用的、很小的空闲分区,即碎片。尽管可以对它们进行“紧凑”,但这种方法太过复杂,会大大影响系统的效率。而最佳适应算法则要求找到空闲分区链中既能满足内存空间要求,又是最小的空闲分区分配给作业,此时空闲分区链需以空闲分区从小到大的次序链接。在此次实验中,我在使用最佳适应算法分区分配内存空间前,会先将本来以地址递增的链表经过以空闲分区大小为排序条件的排序算法。但在这样需要注意的是,在释放分区之前需将以空闲分区大小递增排序的链表经过以地址递增为排序条件的排序算法,因为在内存回收时,是将原本被占用的分区单独变成空闲分区或合并相邻的一个分区/两个分区,地址要求的连续的。但这个算法也会和首次适应算法一样存在产生碎片的问题。操作系统中关于内存管理的算法非常之多,深入学习需要下苦功夫。
|