| jieba库中自定义词典的词频含义,便于分出想要的词(自留笔记) | 您所在的位置:网站首页 › 帽子的词性是什么词 › jieba库中自定义词典的词频含义,便于分出想要的词(自留笔记) |
jieba库中自定义词典的词频含义,便于分出想要的词(自留笔记)
|
写论文的时候,数据处理用jieba分词,建立了自定义词典但怎么也分不出想要的词,搜了半天发现国内基本上没人写这个,所以写下来自用,也分享给做数据处理的小伙伴们。因为是自留,所以会写的比较细一点,看起来会有点啰嗦,如果想节约时间可以只看解决方法部分 参考帖子 https://github.com/fxsjy/jieba/issues/967 问题: 1.这是要处理的文本(举例) :【我在人民路上人民路小学】
想要的语句分段应该是:【我 \在 \人民路 \上 \人民路小学 】 但如果不加自定义词典,只用官方自带的词典会得到:
2.此时为了分出想要的词,采用自定义词典,在自定义词典中增加 【人民路、人民路小学】两个词 保存文档后,分词结果如下(其中【在】字因为我用了停用词,所以这里并没有显示):
可见,我们想要的【人民路小学】这个词分出来了,但 【人民路\上】 却被分成了【人民\路上】 3.为什么会出现这样的情况呢?其实是因为jieba这个库里面原本就有一个内置分词词典,而你增加的自定义词典,只是相当于扩充了这个内置分词词典词库中的词语量,分词的时候并不会优先考虑自定义词典中的词(个人理解,可能有点点偏差) 通过:print(jieba.__file__) 我们可以找到jieba库所在的路径,里面有个dict.txt 这就是jieba的内置词典库
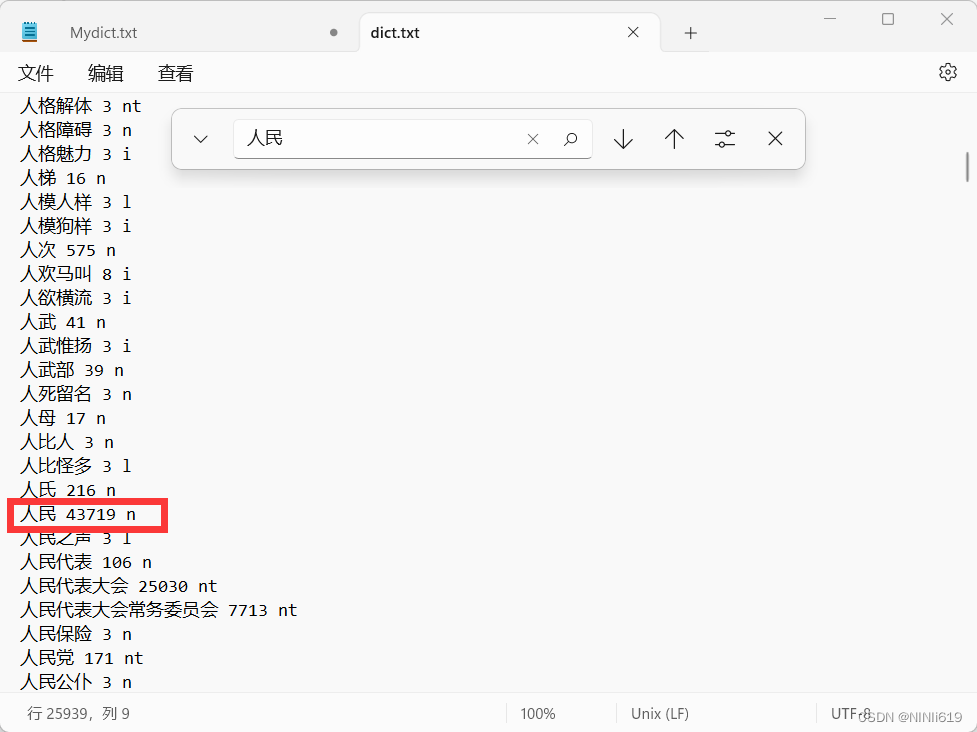
继续回到上述【我在人民路上人民路小学】这个例子,通过ctrl+F查找dict.txt中的文本内容,会发现dict.txt中自带有【人民、路上】这两个词(此处只显示人民)
网上最简单的解决办法就是删除dict.txt中的【人民、路上】这两个词,这样就可以分出【我 \在 \人民路 \上 \人民路小学 】但是我不建议这样!!!因为这样改来改去会让jieba内置词典分词效果变得不好,如果你后面的文本想分出【路上】这个词怎么办呢? 所以这里提供一个本人以为较好的解决办法 解决方法: 根据本人最开始放在开头的链接中所述 jieba中的内置词典的词语格式其实要有三种属性(如下红黄蓝)
其中: 【人民】就是词语嘛这很好理解 【43719】这种数字代表的是这个词语的词频 【n】代表的词语的词性(个人认为这个不是很重要,毕竟中文的词性,感觉不太好分) 上述问题的原因就在【43719】这个数字词频上 根据链接的帖子中所述:结巴分词中词语的词频并不完全是我们所理解的:词频越大,权重越大!!!即分词会先按照词频大的词语来分!!! 其实并不是这样的!!!非也非也!!!!切记切记!!!!! 仍然用上面那个【人民路\上】来举例jieba真正的分词原理: 现在给出一些数据: 内置词典和自定义词典中词语和的总数为:all 在dict.txt中:【人民】这个词的词频是43719 【路上】这个词的词频是2706 【上】这个词的词频是258101 在自定义词典中我们设置:【人民路】这个词的词频是 2706 jieba分词的分词方式是(字丑见谅): 人民、路上这些都指的是对应的词频!!! jieba分词时会比较上面两个公式,显然②大,就会按照②的方式来分词 所以我们可以调节自定义词典中词语的词频数,使得词频数更大,分出想要的词语。 但具体词频的大小,可按照上述那个公式,稍稍计算一下就行。 同时如果你观察dict.txt词典,你就会发现通常:单个字的词频会更大,词语字数长的词频会更小,这是因为结巴分词,更倾向于分长词!!! 简单举个例子就是【人民路小学】 词典中:【人民路、人民路小学、小学】都有,但是为什么却恰恰可以把词语分成【人民路小学】,而不是【人民路】和【小学】呢? 仍然用上面的公式:
显然,就算【人民路小学】的词频设为1,但由于②中分母是总词语数的平方,如果不把【人民路】和【小学】的词频设的比词语总数还大,都会按照【人民路小学】来分词 所以设定词语的词频时,如果想要得到的词语本就是长词,词频不用设置的特别大1-50基本上就行了,如果是短词得提高一下词语的频次 写的比较啰嗦,见谅! 祝万事胜意:) |


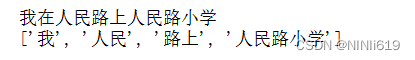



【本文地址】