Word2Vec之Skip |
您所在的位置:网站首页 › skip-gram › Word2Vec之Skip |
Word2Vec之Skip
|
在NLP领域,词向量是一个非常基础的知识点,计算机是不能识别文字,所以要让计算机记住文字只能通过数字的形式,在最初所采用的是one-hot(独热)编码,简单回顾一下这种编码方式 例如:我很讨厌下雨 分词之后:我 很 讨厌 下雨 可知词表大小为4,采用one-hot编码方式则为 我:[1,0,0,0] 很:[0,1,0,0] 讨厌:[0,0,1,0] 下雨:[0,0,0,1] 这种方式可以很明显的看出one-hot编码的缺点,主要是体现在两方面:词表过大的时候,会生成非常大的系数矩阵;无法记录词与词之间的关系 因而在这个基础上,word2vec应运而生!本文将结合模型的实现代码详细解读Word2Vec之一的Skip-Gram模型。本文主要由以下几个部分: 一、网络模型图 二、代码实现 数据准备 数据与处理 模型搭建 训练&测试
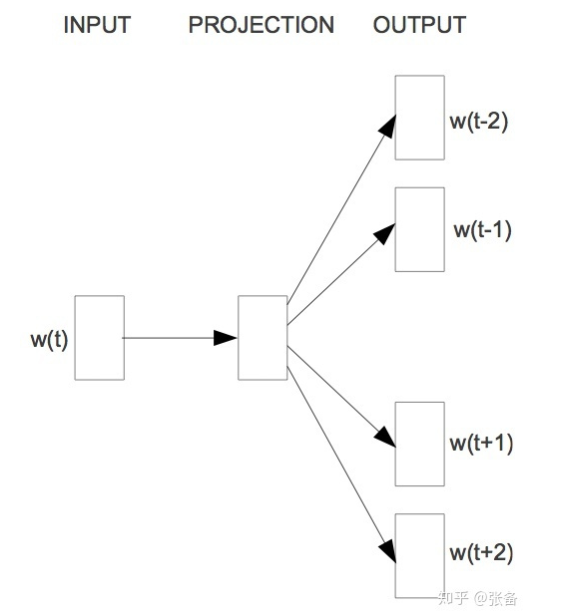
网络模型图
Skip-Gram的网络模型如上,其原理就是根据一个词去生成周围的词。以“我 很 讨厌 下雨”为例,(若生成范围为1:即前后的一个词)则是:‘’讨厌‘’ 生成 “很” 和 “下雨”。上述图片所展示的模型的生成范围为2:即前后的两个词 在这里,可能大家还是不好理解,为什么要这样做?其实很简单,当我们在学习这个知识点的时候,之前一定学习过了逻辑回归模型(经典的手写体识别),这个模型的本质上也是一个回归模型。以“我 很 讨厌 下雨”为例,根据“讨厌” 生成 “很”和“下雨” 实际可以理解为: 样本 “讨厌” 对应着标签“很”和“下雨” 这样,对于这个模型而言,当我们输入样本“讨厌”的时候,对应模型的输出则应该是“很”和“下雨” 但是,我们在如下代码的实现过程当中,并不是一次就输出其所对应的标签,而是多次。以“我 很 讨厌 下雨”为例,不是通过一次输入“讨厌”的时候,直接就输出了“很”和“下雨”而是两次,第一次输入“讨厌”,输出“很”,第二次输入“讨厌”,输出“下雨”。因而代码实现的具体网络模型如下:
代码实现 数据准备 1 #1.导入所依赖的库 2 import time 3 import collections 4 import math 5 import os 6 import random 7 import zipfile 8 import numpy as np 9 import urllib 10 import pprint 11 import tensorflow as tf 12 import matplotlib.pyplot as plt 13 os.environ["TF_CPP_MIN_LOG_LEVEL"] = "2" 14 15 #2.准备数据集 16 17 url = "http://mattmahoney.net/dc/" 18 19 def maybe_download(filename,expected_bytes): 20 """ 21 判断文件是否已经下载,如果没有,则下载数据集 22 """ 23 if not os.path.exists(filename): 24 #数据集不存在,开始下载 25 filename,_ = urllib.request.urlretrieve(url + filename,filename) 26 #有关函数urllib.request.urlretrieve的详解博客https://blog.csdn.net/pursuit_zhangyu/article/details/80556275 27 #核对文件尺寸 28 stateinfo = os.stat(filename) 29 #有关系统stat调用的详细解释链接https://www.cnblogs.com/fmgao-technology/p/9056425.html 30 if stateinfo.st_size == expected_bytes: 31 print("数据集已存在,且文件尺寸合格!",filename) 32 else : 33 print(stateinfo.st_size) 34 raise Exception( 35 "文件尺寸不对 !请重新下载,下载地址为:"+url 36 ) 37 return filename 38 """ 39 测试文件是否存在 40 """ 41 filename = maybe_download("text8.zip",31344016) 42 43 #3.解压文件 44 def read_data(filename): 45 #有关zipfile模块的详细使用介绍博客https://www.cnblogs.com/ManyQian/p/9193199.html 46 with zipfile.ZipFile(filename) as f: 47 #有关python中split()函数的详细解释博客https://www.runoob.com/python/att-string-split.html 48 data = tf.compat.as_str(f.read(f.namelist()[0])).split() 49 ''' 50 使用 zipfile.ZipFile()来提取压缩文件,然后我们可以使用 51 zipfile 模块中的读取器功能。首先,namelist()函数检索该 52 档案中的所有成员——在本例中只有一个成员,所以我们可以使 53 用 0 索引对其进行访问。然后,我们使用 read()函数读取文 54 件中的所有文本,并传递给 TensorFlow 的 as_str 函数,以确 55 保文本保存为字符串数据类型。最后,我们使用 split()函数 56 创建一个列表,该列表包含文本文件中所有的单词,并用空格字 57 符分隔''' 58 return data 59 words = read_data(filename) 60 print("总的单词个数:",len(words))数据预处理 1 #4.构建词汇表,并统计每个单词出现的频数,同时用字典的形式进行存储,取频数排名前50000的单词 2 vocabulary_size = 50000 3 def build_dataset(words): 4 count = [["unkown",-1]] 5 #collections.Counter()返回的是形如[["unkown",-1],("the",4),("physics",2)] 6 count.extend(collections.Counter(words).most_common(vocabulary_size - 1)) 7 #有关collection模块中counter类的详细解释链接http://www.pythoner.com/205.html 8 #most_common()函数用来实现Top n 功能 即截取counter结果的前多少个子项 9 #对于列表的一些常见基本操作详细链接https://blog.csdn.net/ywx1832990/article/details/78928238 10 dictionary = {} 11 #将全部单词转为编号(以频数排序的编号),我们只关注top50000的单词,以外的认为是unknown的,编号为0,同时统计一下这类词汇的数量 12 for word,_ in count: 13 dictionary[word] = len(dictionary) 14 #形如:{"the":1,"UNK":0,"a":12} 15 data = [] 16 unk_count = 0 #准备统计top50000以外的单词的个数 17 for word in words: 18 #对于其中每一个单词,首先判断是否出现在字典当中 19 if word in dictionary: 20 #如果已经出现在字典中,则转为其编号 21 index = dictionary[word] 22 else: 23 #如果不在字典,则转为编号0 24 index = 0 25 unk_count += 1 26 data.append(index)#此时单词已经转变成对应的编号 27 """ 28 print(data[:10]) 29 [5234, 3081, 12, 6, 195, 2, 3134, 46, 59, 156] 30 """ 31 count[0][1] = unk_count #将统计好的unknown的单词数,填入count中 32 #将字典进行翻转,形如:{3:"the,4:"an"} 33 reverse_dictionary = dict(zip(dictionary.values(),dictionary.keys())) 34 return data,count,dictionary,reverse_dictionary 35 #为了节省内存,将原始单词列表进行删除 36 data,count,dictionary,reverse_dictionary = build_dataset(words) 37 del words 38 #将部分结果展示出来 39 #print("出现频率最高的单词(包括未知类别的):",count[:10]) 40 #将已经转换为编号的数据进行输出,从data中输出频数,从翻转字典中输出编号对应的单词 41 #print("样本数据(排名):",data[:10],"\n对应的单词",[reverse_dictionary[i] for i in data[:10]]) 42 43 #5.生成Word2Vec的训练样本,使用skip-gram模式 44 data_index = 0 45 46 def generate_batch(batch_size,num_skips,skip_window): 47 """ 48 49 :param batch_size: 每个训练批次的数据量 50 :param num_skips: 每个单词生成的样本数量,不能超过skip_window的两倍,并且必须是batch_size的整数倍 51 :param skip_window: 单词最远可以联系的距离,设置为1则表示当前单词只考虑前后两个单词之间的关系,也称为滑窗的大小 52 :return:返回每个批次的样本以及对应的标签 53 """ 54 global data_index #声明为全局变量,方便后期多次使用 55 #使用Python中的断言函数,提前对输入的参数进行判别,防止后期出bug而难以寻找原因 56 assert batch_size % num_skips == 0 57 assert num_skips 0: 21 average_loss /= 2000 22 print('第%d轮迭代用时:%s'% (step, time.time()- t0)) 23 t0 = time.time() 24 print("第{}轮迭代后的损失为:{}".format(step,average_loss)) 25 average_loss = 0 26 27 #每10000次迭代,计算一次验证单词与全部单词的相似度,并将于验证单词最相似的前8个单词呈现出来 28 if step % 10000 == 0: 29 sim = similarity.eval() #计算向量 30 for i in range(valid_size): 31 valid_word = reverse_dictionary[valid_examples[i]] #得到对应的验证单词 32 top_k = 8 33 nearest = (-sim[i,:]).argsort()[1:top_k+1] #计算每一个验证单词相似度最接近的前8个单词 34 log_str = "与单词 {} 最相似的: ".format(str(valid_word)) 35 36 for k in range(top_k): 37 close_word = reverse_dictionary[nearest[k]] #相似度高的单词 38 log_str = "%s %s, " %(log_str,close_word) 39 print(log_str) 40 final_embeddings = normalized_embeddings.eval() 41 42 #10.可视化Word2Vec效果 43 def plot_with_labels(low_dim_embs,labels,filename = "tsne.png"): 44 assert low_dim_embs.shape[0] >= len(labels),"标签数超过了嵌入向量的个数!!" 45 46 plt.figure(figsize=(20,20)) 47 for i,label in enumerate(labels): 48 x,y = low_dim_embs[i,:] 49 plt.scatter(x,y) 50 plt.annotate( 51 label, 52 xy = (x,y), 53 xytext=(5,2), 54 textcoords="offset points", 55 ha="right", 56 va="bottom" 57 ) 58 plt.savefig(filename) 59 from sklearn.manifold import TSNE 60 tsne = TSNE(perplexity=30,n_components=2,init="pca",n_iter=5000) 61 plot_only = 100 62 low_dim_embs = tsne.fit_transform(final_embeddings[:plot_only,:]) 63 Labels = [reverse_dictionary[i] for i in range(plot_only)] 64 plot_with_labels(low_dim_embs,Labels) 65 """ 66 第142000轮迭代后的损失为:4.46674475479126 67 第144000轮迭代后的损失为:4.460033647537231 68 第146000轮迭代后的损失为:4.479593712329865 69 第148000轮迭代后的损失为:4.463101862192154 70 第150000轮迭代后的损失为:4.3655951328277585 71 与单词 can 最相似的: may, will, would, could, should, must, might, cannot, 72 与单词 were 最相似的: are, was, have, had, been, be, those, including, 73 与单词 is 最相似的: was, has, are, callithrix, landesverband, cegep, contains, became, 74 与单词 been 最相似的: be, become, were, was, acuity, already, banded, had, 75 与单词 new 最相似的: repertory, rium, real, ursus, proclaiming, cegep, mesoplodon, bolster, 76 与单词 their 最相似的: its, his, her, the, our, some, these, landesverband, 77 与单词 when 最相似的: while, if, where, before, after, although, was, during, 78 与单词 of 最相似的: vah, in, neutronic, widehat, abet, including, nine, cegep, 79 与单词 first 最相似的: second, last, biggest, cardiomyopathy, next, cegep, third, burnt, 80 与单词 other 最相似的: different, some, various, many, thames, including, several, bearings, 81 与单词 its 最相似的: their, his, her, the, simplistic, dativus, landesverband, any, 82 与单词 from 最相似的: into, through, within, in, akita, bde, during, lawless, 83 与单词 would 最相似的: will, can, could, may, should, might, must, shall, 84 与单词 people 最相似的: those, men, pisa, lep, arctocephalus, protectors, saguinus, builders, 85 与单词 had 最相似的: has, have, was, were, having, ascribed, wrote, nitrile, 86 与单词 all 最相似的: auditum, some, scratch, both, several, many, katydids, two, 87 """以上就是实现代码的全部,大家可以粘贴过去,则能运行!但是!但是!但是!会非常慢,因为我们在最后进行softmax的时候,当词表大小过大的时候,这个计算时间会非常的复杂。因此,word2vec的讲点就在于,采用了负采样的方法,大大提高了模型的训练速度。有关负采样,我会单独写一篇文档详解。对于上述代码,要改用负采样的方法进行训练,则只是需要将模型搭建中的28行到40行替换为如下代码,即可 1 #优化目标选择NCE loss 2 #使用截断正太函数初始化NCE损失的权重,偏重初始化为0 3 nce_weights = tf.Variable(tf.truncated_normal([vocabulary_size,embedding_size],stddev= 1.0 /math.sqrt(embedding_size))) 4 nce_biases = tf.Variable(tf.zeros([vocabulary_size])) 5 6 #计算学习出的embedding在训练数据集上的loss,并使用tf.reduce_mean()函数进行汇总 7 loss = tf.reduce_mean(tf.nn.nce_loss( 8 weights=nce_weights, 9 biases=nce_biases, 10 labels =train_labels, 11 inputs=embed, 12 num_sampled=num_sampled, 13 num_classes=vocabulary_size 14 )) 15 16 #定义优化器为SGD,且学习率设置为1.0.然后计算嵌入向量embeddings的L2范数norm,并计算出标准化后的normalized_embeddings 17 optimizer = tf.train.GradientDescentOptimizer(1.0).minimize(loss) 18 norm = tf.sqrt(tf.reduce_sum(tf.square(nce_weights),1,keep_dims=True)) #嵌入向量的L2范数 19 normalized_embeddings = nce_weights / norm #标准哈embeddings祝大家一切顺利!代码中的个别部分,我在注释中附上了相应的博客链接,感谢这些博主!也感谢大家!如果有神额不正确的地方,欢迎大家指正。
|
【本文地址】
今日新闻 |
点击排行 |
|
推荐新闻 |
图片新闻 |
|
专题文章 |