使用spark3操作hudi数据湖初探 |
您所在的位置:网站首页 › converttostringlist › 使用spark3操作hudi数据湖初探 |
使用spark3操作hudi数据湖初探
|
环境:
hadoop 3.2.0 spark 3.0.3-bin-hadoop3.2 hudi 0.8.0 本文基于上述组件版本使用spark插入数据到hudi数据湖中。为了确保以下各步骤能够成功完成,请确保hadoop集群正常启动。 确保已经配置环境变量HADOOP_CLASSPATH 对于开源版本hadoop,HADOOP_CLASSPATH配置为: export HADOOP_CLASSPATH=$HADOOP_CLASSPATH:$HADOOP_HOME/share/hadoop/client/*:$HADOOP_HOME/share/hadoop/common/*:$HADOOP_HOME/share/hadoop/hdfs/*:$HADOOP_HOME/share/hadoop/mapreduce/*:$HADOOP_HOME/share/hadoop/tools/*:$HADOOP_HOME/share/hadoop/yarn/*:$HADOOP_HOME/etc/hadoop/*本文使用的hdfs地址为:hdfs://hadoop2:9000 本地安装spark集群1 spark下载 wget https://dlcdn.apache.org/spark/spark-3.0.3/spark-3.0.3-bin-hadoop3.2.tgz tar zxvf spark-3.0.3-bin-hadoop3.2.tgz2 下载hudi相关jar包到spark-3.0.3-bin-hadoop3.2/jars目录下。需要下载spark_avro_2.12-3.0.3.jar以及hudi-spark3-bundle_2.12-0.8.0.jar cd spark-3.0.3-bin-hadoop3.2/jars wget https://repo1.maven.org/maven2/org/apache/spark/spark-avro_2.12/3.0.3/spark-avro_2.12-3.0.3.jar wget https://repo1.maven.org/maven2/org/apache/hudi/hudi-spark3-bundle_2.12/0.8.0/hudi-spark3-bundle_2.12-0.8.0.jar3 修改配置文件 cp conf/spark-env.sh.template conf/spark-env.sh cp conf/slaves.template conf/slaves cp conf/spark-defaults.conf.template conf/spark-defaults.confvi conf/spark-env.sh 新增如下内容,指明JAVA_HOME目录,否则worker无法启动 JAVA_HOME=/data/jdk8slaves为spark worker的地址,本地执行可只填localhost,无需修改 spark-defaults.conf为spark相关配置,可根据需要修改,本文都是用默认配置,未做修改。 4 启动spark集群 sbin/start-all.sh 启动spark-shell并attach本地spark集群执行以下命令启动(需要指定spark.serializer): ./bin/spark-shell --master spark://hadoop1:7077 --conf 'spark.serializer=org.apache.spark.serializer.KryoSerializer' 使用spark-shell操作hudi数据湖1 导入依赖包以及指定表名、hdfs路径、数据生成器 import org.apache.hudi.QuickstartUtils._ import scala.collection.JavaConversions._ import org.apache.spark.sql.SaveMode._ import org.apache.hudi.DataSourceReadOptions._ import org.apache.hudi.DataSourceWriteOptions._ import org.apache.hudi.config.HoodieWriteConfig._ val tableName = "hudi_trips_cow" val basePath = "hdfs://hadoop2:9000/tmp/spark_hudi_test" val dataGen = new DataGenerator其中,DataGenerator可以用于生成测试数据,用来完成后续操作。具体可参考相关源码:DataGenerator 2 生成数据并写入hudi中 val inserts = convertToStringList(dataGen.generateInserts(10)) val df = spark.read.json(spark.sparkContext.parallelize(inserts, 2)) df.write.format("hudi"). options(getQuickstartWriteConfigs). option(PRECOMBINE_FIELD_OPT_KEY, "ts"). option(RECORDKEY_FIELD_OPT_KEY, "uuid"). option(PARTITIONPATH_FIELD_OPT_KEY, "partitionpath"). option(TABLE_NAME, tableName). mode(Overwrite). save(basePath)其中生成数据如下所示:
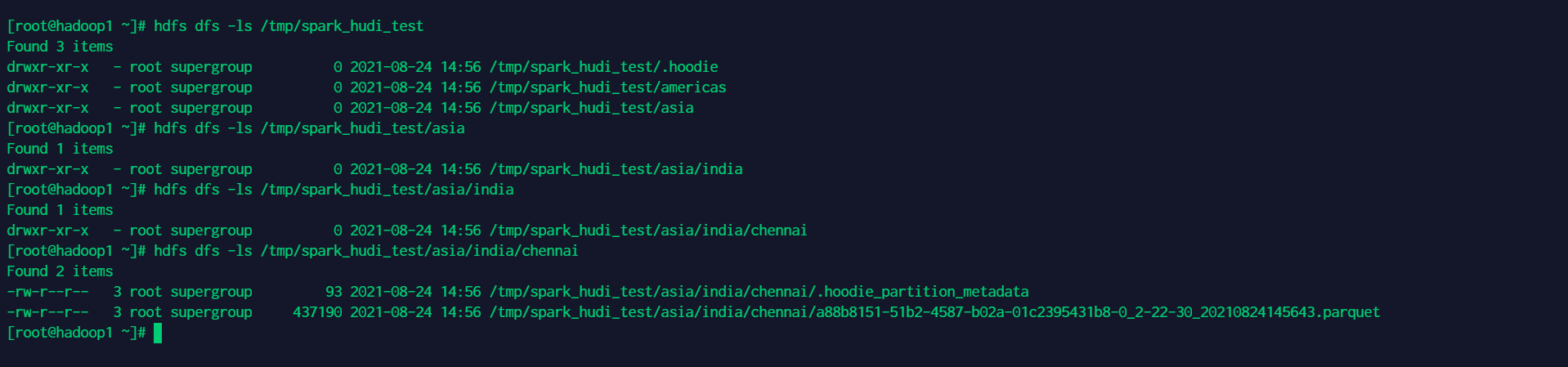
查看hdfs相关路径
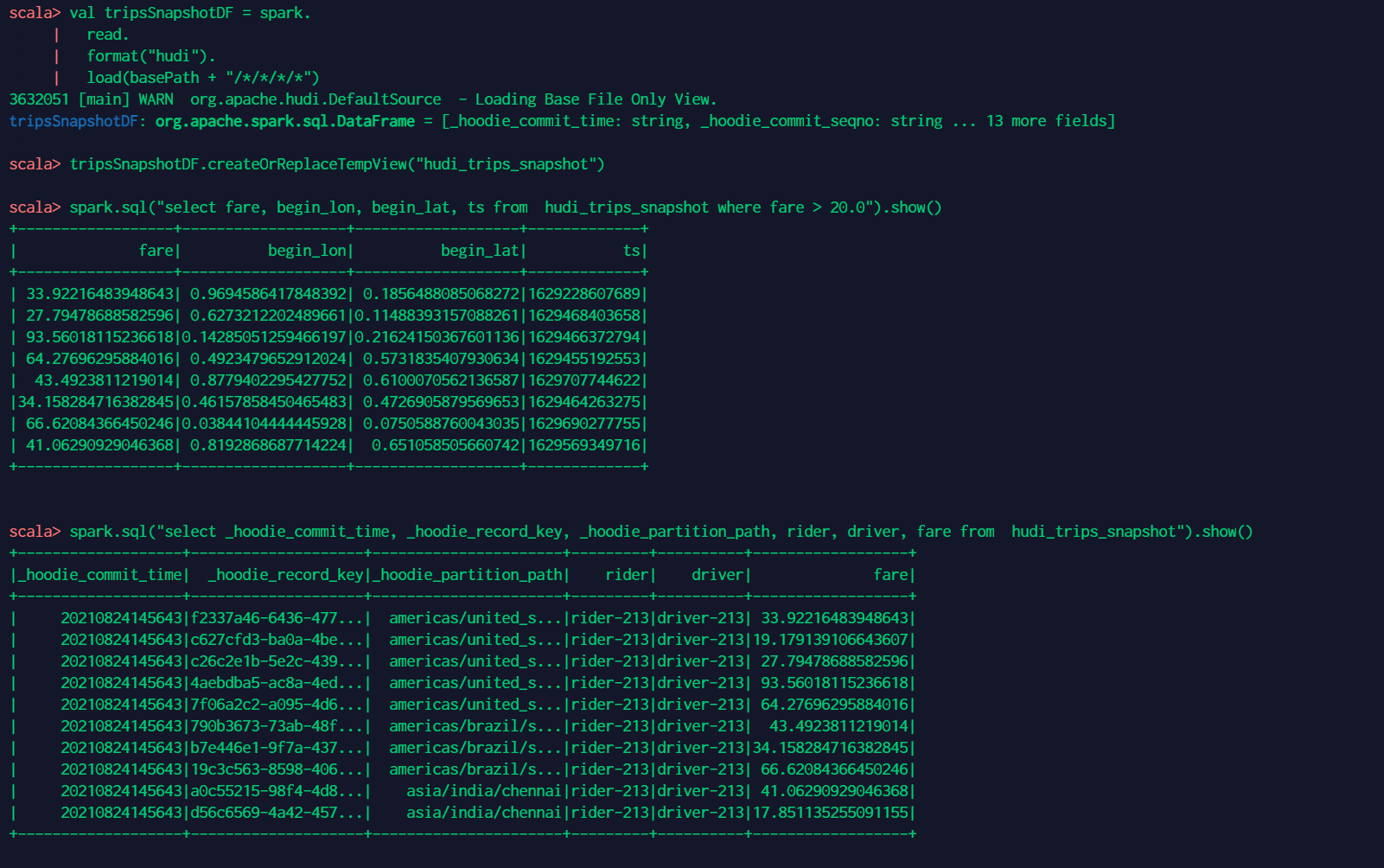
3 查询数据 // spark-shell val tripsSnapshotDF = spark. read. format("hudi"). load(basePath + "/*/*/*/*") //load(basePath) use "/partitionKey=partitionValue" folder structure for Spark auto partition discovery tripsSnapshotDF.createOrReplaceTempView("hudi_trips_snapshot") spark.sql("select fare, begin_lon, begin_lat, ts from hudi_trips_snapshot where fare > 20.0").show() spark.sql("select _hoodie_commit_time, _hoodie_record_key, _hoodie_partition_path, rider, driver, fare from hudi_trips_snapshot").show()相关结果
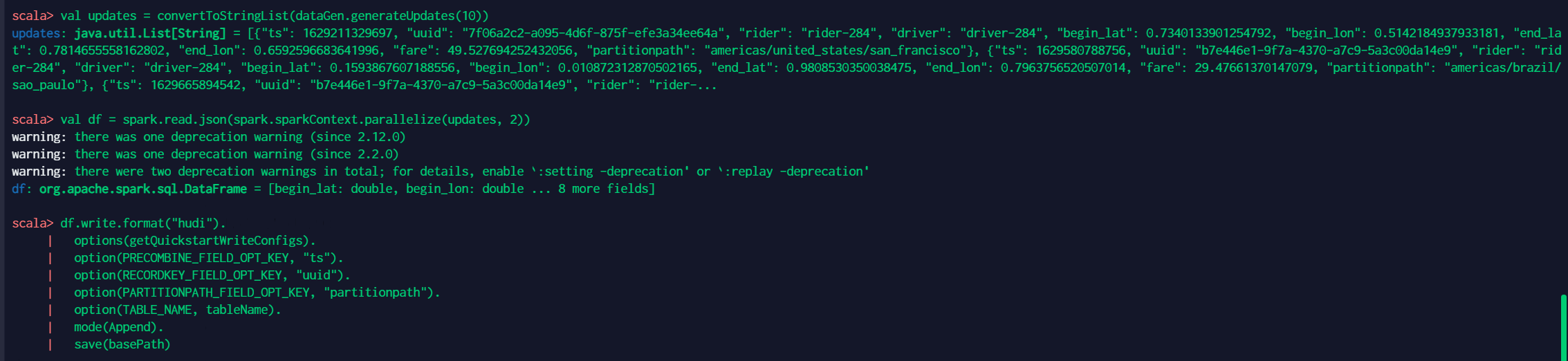
4 更新数据 // spark-shell val updates = convertToStringList(dataGen.generateUpdates(10)) val df = spark.read.json(spark.sparkContext.parallelize(updates, 2)) df.write.format("hudi"). options(getQuickstartWriteConfigs). option(PRECOMBINE_FIELD_OPT_KEY, "ts"). option(RECORDKEY_FIELD_OPT_KEY, "uuid"). option(PARTITIONPATH_FIELD_OPT_KEY, "partitionpath"). option(TABLE_NAME, tableName). mode(Append). save(basePath)其中第一行为生成更新数据,详细操作如下:
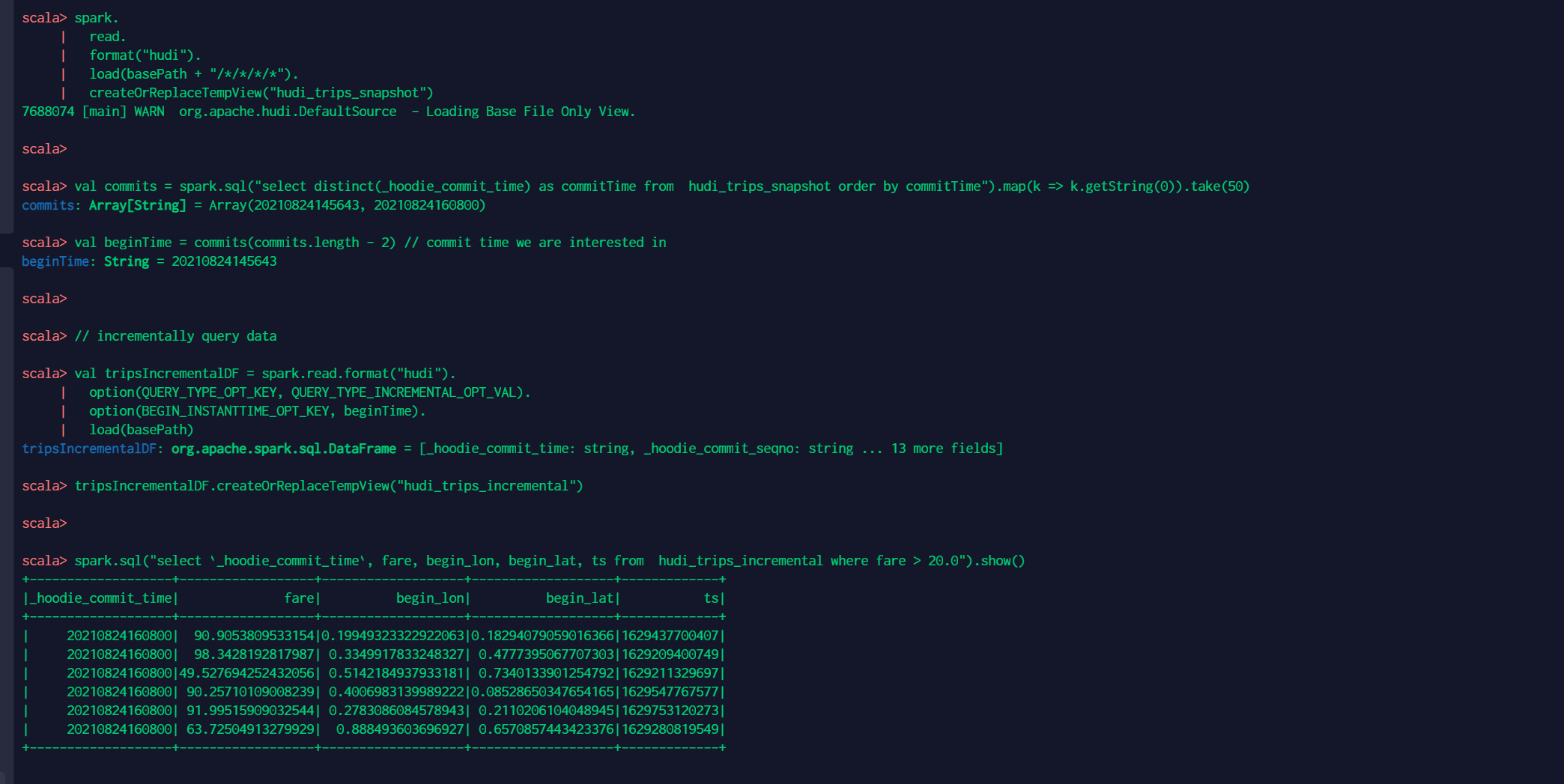
5 增量查询 // spark-shell // reload data spark. read. format("hudi"). load(basePath + "/*/*/*/*"). createOrReplaceTempView("hudi_trips_snapshot") val commits = spark.sql("select distinct(_hoodie_commit_time) as commitTime from hudi_trips_snapshot order by commitTime").map(k => k.getString(0)).take(50) val beginTime = commits(commits.length - 2) // commit time we are interested in // incrementally query data val tripsIncrementalDF = spark.read.format("hudi"). option(QUERY_TYPE_OPT_KEY, QUERY_TYPE_INCREMENTAL_OPT_VAL). option(BEGIN_INSTANTTIME_OPT_KEY, beginTime). load(basePath) tripsIncrementalDF.createOrReplaceTempView("hudi_trips_incremental") spark.sql("select `_hoodie_commit_time`, fare, begin_lon, begin_lat, ts from hudi_trips_incremental where fare > 20.0").show()查询结果如下:
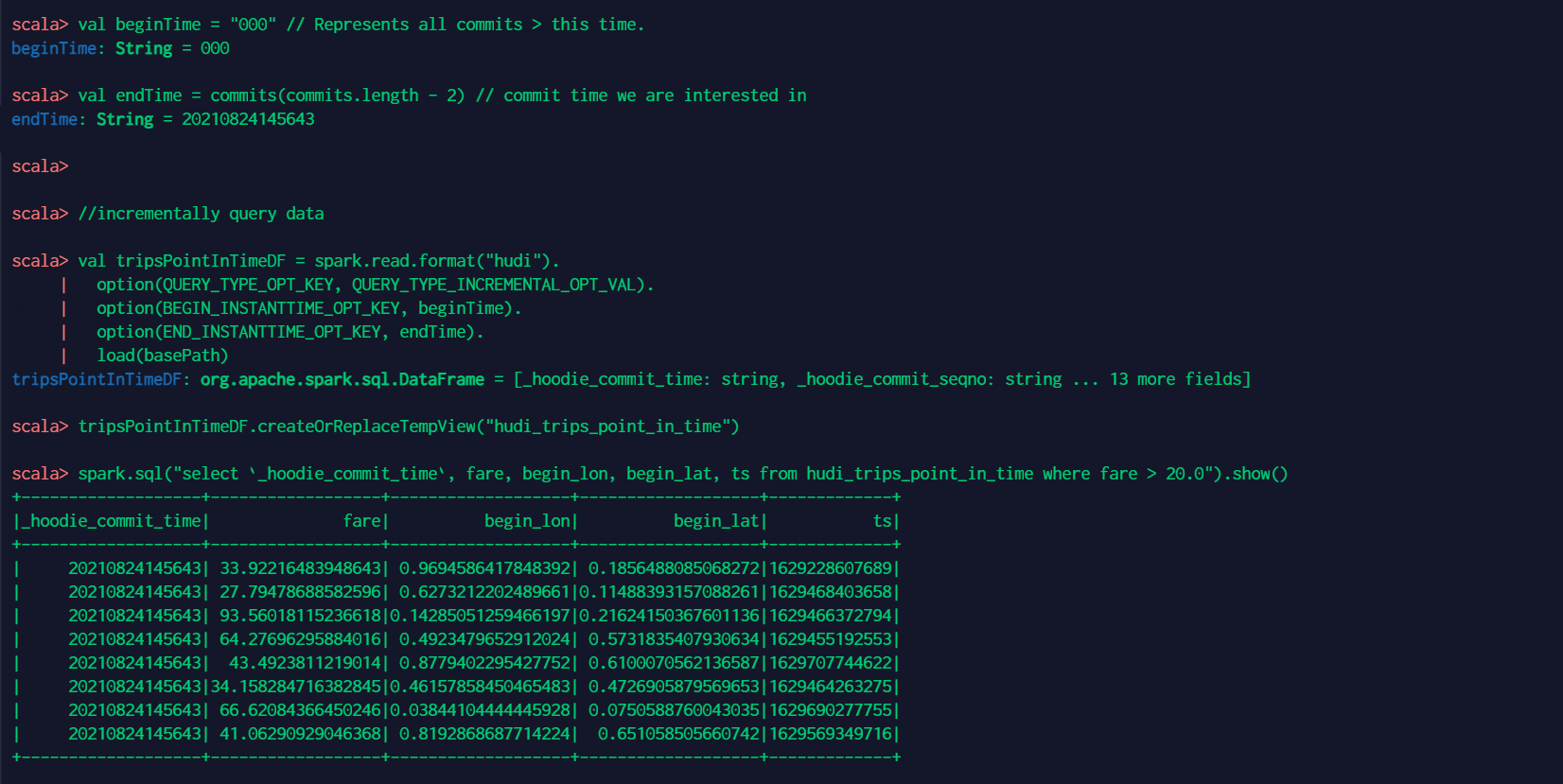
6 查询指定时间。具体的时间可以通过将endTime指向特定的提交时间,将beginTime指向“000”(表示可能最早的提交时间)来表示。 // spark-shell val beginTime = "000" // Represents all commits > this time. val endTime = commits(commits.length - 2) // commit time we are interested in //incrementally query data val tripsPointInTimeDF = spark.read.format("hudi"). option(QUERY_TYPE_OPT_KEY, QUERY_TYPE_INCREMENTAL_OPT_VAL). option(BEGIN_INSTANTTIME_OPT_KEY, beginTime). option(END_INSTANTTIME_OPT_KEY, endTime). load(basePath) tripsPointInTimeDF.createOrReplaceTempView("hudi_trips_point_in_time") spark.sql("select `_hoodie_commit_time`, fare, begin_lon, begin_lat, ts from hudi_trips_point_in_time where fare > 20.0").show()查询结果如下:
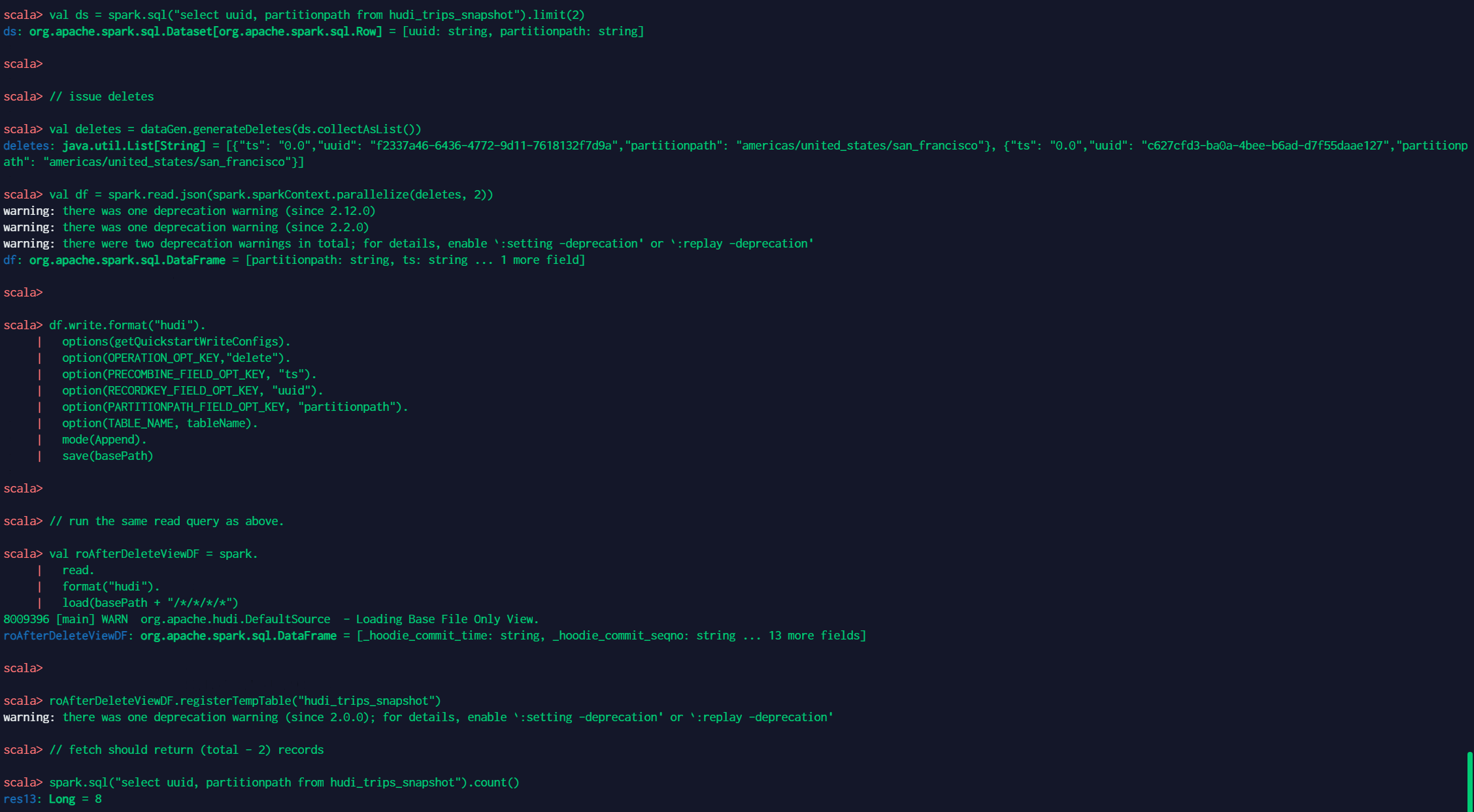
7 根据HoodieKeys删除数据 // spark-shell // fetch total records count spark.sql("select uuid, partitionpath from hudi_trips_snapshot").count() // fetch two records to be deleted val ds = spark.sql("select uuid, partitionpath from hudi_trips_snapshot").limit(2) // issue deletes val deletes = dataGen.generateDeletes(ds.collectAsList()) val df = spark.read.json(spark.sparkContext.parallelize(deletes, 2)) df.write.format("hudi"). options(getQuickstartWriteConfigs). option(OPERATION_OPT_KEY,"delete"). option(PRECOMBINE_FIELD_OPT_KEY, "ts"). option(RECORDKEY_FIELD_OPT_KEY, "uuid"). option(PARTITIONPATH_FIELD_OPT_KEY, "partitionpath"). option(TABLE_NAME, tableName). mode(Append). save(basePath) // run the same read query as above. val roAfterDeleteViewDF = spark. read. format("hudi"). load(basePath + "/*/*/*/*") roAfterDeleteViewDF.registerTempTable("hudi_trips_snapshot") // fetch should return (total - 2) records spark.sql("select uuid, partitionpath from hudi_trips_snapshot").count()相关结果如下:
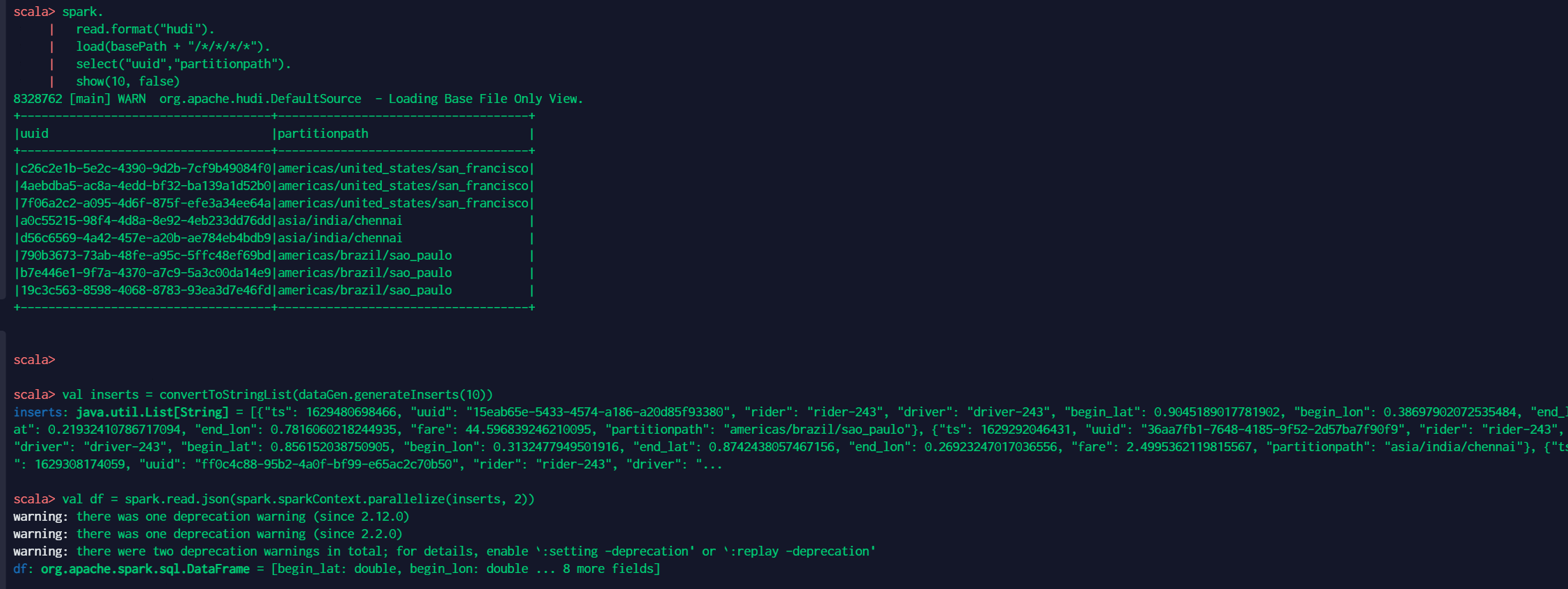
8 插入并覆盖表数据 生成一些新的数据,在Hudi元数据级别逻辑上覆盖表。 Hudi清理器最终会清理上一个表快照的文件组。 这比删除旧表并在覆盖模式下重新创建要快。 spark. read.format("hudi"). load(basePath + "/*/*/*/*"). select("uuid","partitionpath"). show(10, false) val inserts = convertToStringList(dataGen.generateInserts(10)) val df = spark.read.json(spark.sparkContext.parallelize(inserts, 2)) df.write.format("hudi"). options(getQuickstartWriteConfigs). option(OPERATION_OPT_KEY,"insert_overwrite_table"). option(PRECOMBINE_FIELD_OPT_KEY, "ts"). option(RECORDKEY_FIELD_OPT_KEY, "uuid"). option(PARTITIONPATH_FIELD_OPT_KEY, "partitionpath"). option(TABLE_NAME, tableName). mode(Append). save(basePath) // Should have different keys now, from query before. spark. read.format("hudi"). load(basePath + "/*/*/*/*"). select("uuid","partitionpath"). show(10, false)相关结果如下
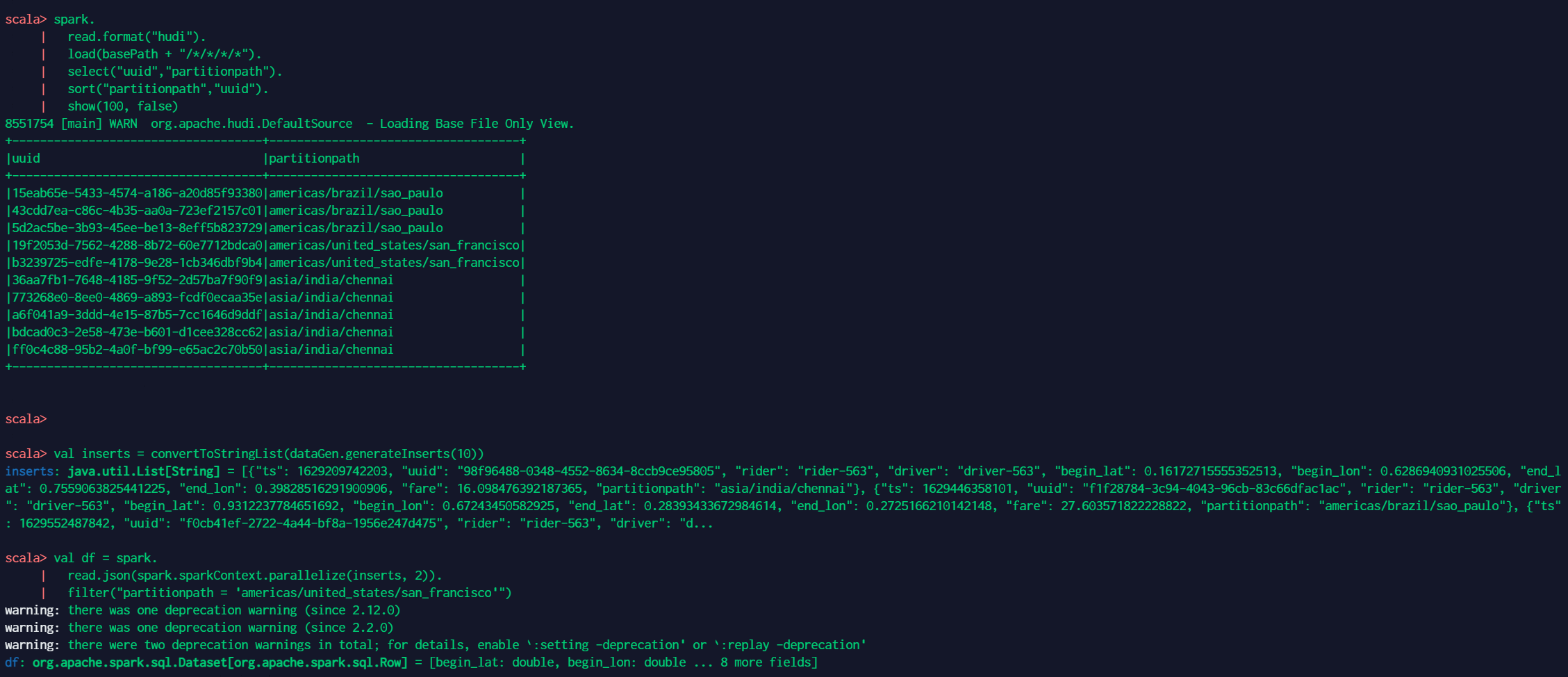
9 插入覆盖 生成一些新数据,覆盖输入中的所有分区。对于批处理ETL作业来说,这个操作比upsert更快,批处理ETL作业一次重新计算整个目标分区(而不是增量地更新目标表)。这是因为,我们可以在upsert写路径中完全绕过索引、预组合和其他重分区步骤。 // spark-shell spark. read.format("hudi"). load(basePath + "/*/*/*/*"). select("uuid","partitionpath"). sort("partitionpath","uuid"). show(100, false) val inserts = convertToStringList(dataGen.generateInserts(10)) val df = spark. read.json(spark.sparkContext.parallelize(inserts, 2)). filter("partitionpath = 'americas/united_states/san_francisco'") df.write.format("hudi"). options(getQuickstartWriteConfigs). option(OPERATION_OPT_KEY,"insert_overwrite"). option(PRECOMBINE_FIELD_OPT_KEY, "ts"). option(RECORDKEY_FIELD_OPT_KEY, "uuid"). option(PARTITIONPATH_FIELD_OPT_KEY, "partitionpath"). option(TABLE_NAME, tableName). mode(Append). save(basePath) // Should have different keys now for San Francisco alone, from query before. spark. read.format("hudi"). load(basePath + "/*/*/*/*"). select("uuid","partitionpath"). sort("partitionpath","uuid"). show(100, false)相关结果如下:
|



【本文地址】
今日新闻 |
点击排行 |
|
推荐新闻 |
图片新闻 |
|
专题文章 |