Python网络爬虫之模拟登陆 |
您所在的位置:网站首页 › 重新登陆网络怎么操作的视频 › Python网络爬虫之模拟登陆 |
Python网络爬虫之模拟登陆
|
为什么要模拟登陆
Python网络爬虫应用十分广泛,但是有些网页需要用户登陆后才能获取到信息,所以我们的爬虫需要模拟用户的登陆行为,在登陆以后保存登陆信息,以便浏览该页面下的其他页面。 保存用户信息 模拟登陆后有两种方法可以保存用户信息,通过Session来保存登陆信息或者通过Cookie来保存登陆信息 一、Session的用法 # 导入requests模块 import requests # 通过requests的Session来请求网页 s = requests.Session() r = s.post(url, headers=headers)
二、Cookie的用法 import urllib.request, http.cookiejar # 初始化Cookie cookie = http.cookiejar.CookieJar() opener = urllib.request.build_opener(urllib.request.HTTPCookieProcessor(cookie)) # 把opener配置为全局 当然也可以不配置全局通过opener来请求网页 urllib.request.install_opener(opener) 模拟登陆实践
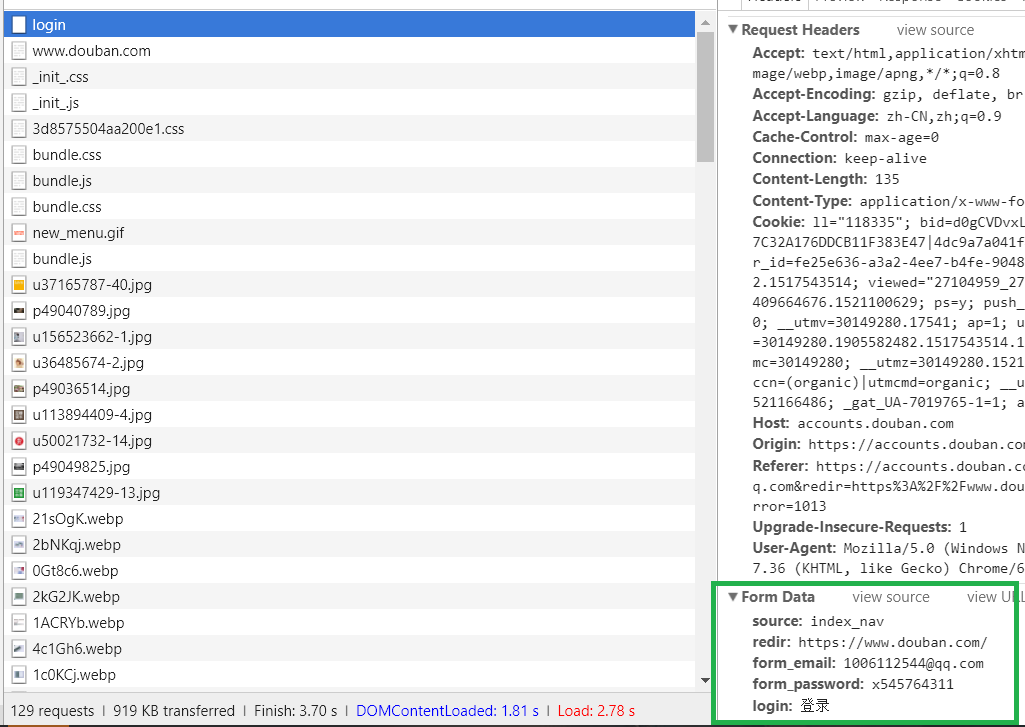
我们以豆瓣网为例模拟用户登陆,然后爬取登陆后的用户界面 (1)找到请求表单 登陆一般是通过Post请求来实现的,其传递参数为一个表单,如果要成功登陆,我们需要查看该表单传递了哪些内容,然后构造表单做Post请求。怎么获取表单了,我们只需要打开浏览器右键查看,然后输入账号密码,点击登陆查看其NetWork中的请求,找到表单信息即可(推荐使用谷歌浏览器),该信息中还能找到请求的url。 表单信息 URL
(2)构建表单 表单的key值我们可以通过右键页面检查页面源代码,在页面源码中获得静态的值(还有些动态信息需要手动获取) formdata = { 'redir': 'https://www.douban.com', 'form_email': '账号', 'form_password': '密码', 'login': u'登陆' }
(3)伪装成浏览器进行登录 我们只需要给请求添加上Headers即可 headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) ' 'Chrome/55.0.2883.87 Safari/537.36'}
(4)获取验证码 第二步的表单其实还不完整,还差两条跟验证码有关的信息,这两条信息是动态变化的,所以我们要手动获取 r = s.post(url_login, headers=headers) content = r.text soup = BeautifulSoup(content, 'html.parser') captcha = soup.find('img', id='captcha_image')#当登陆需要验证码的时候 if captcha: captcha_url = captcha['src'] re_captcha_id = r' |
【本文地址】
公司简介
联系我们
今日新闻 |
点击排行 |
|
推荐新闻 |
图片新闻 |
|
专题文章 |