GitHub |
您所在的位置:网站首页 › 官方源码 › GitHub |
GitHub
|
English | 简体中文 

YOLOv3 🚀 is the world's most loved vision AI, representing Ultralytics open-source research into future vision AI methods, incorporating lessons learned and best practices evolved over thousands of hours of research and development. We hope that the resources here will help you get the most out of YOLOv3. Please browse the YOLOv3 Docs for details, raise an issue on GitHub for support, and join our Discord community for questions and discussions! To request an Enterprise License please complete the form at Ultralytics Licensing. We are thrilled to announce the launch of Ultralytics YOLOv8 🚀, our NEW cutting-edge, state-of-the-art (SOTA) model released at https://github.com/ultralytics/ultralytics. YOLOv8 is designed to be fast, accurate, and easy to use, making it an excellent choice for a wide range of object detection, image segmentation and image classification tasks. See the YOLOv8 Docs for details and get started with:
 Documentation
Documentation
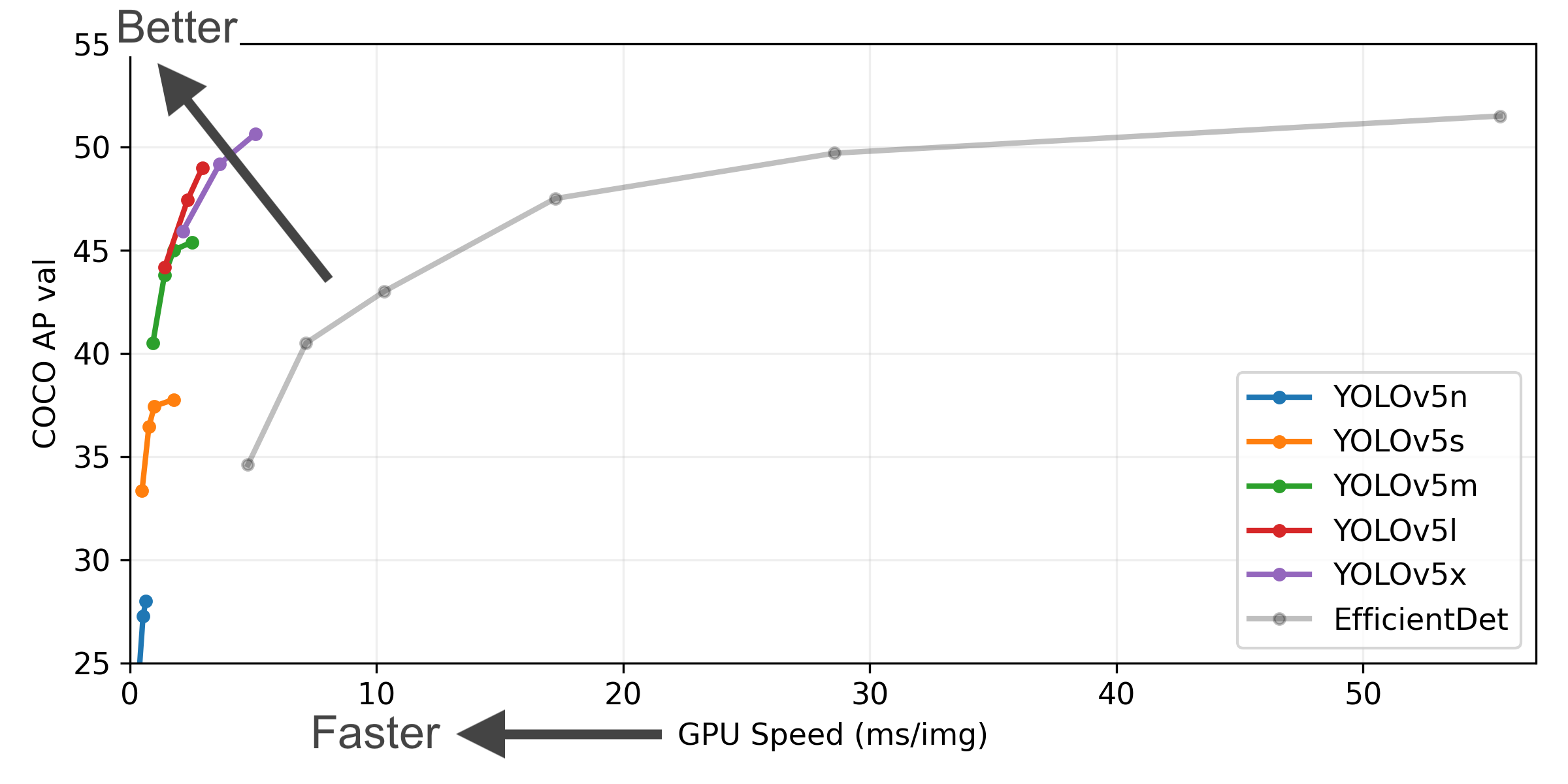
See the YOLOv3 Docs for full documentation on training, testing and deployment. See below for quickstart examples. InstallClone repo and install requirements.txt in a Python>=3.7.0 environment, including PyTorch>=1.7. git clone https://github.com/ultralytics/yolov3 # clone cd yolov3 pip install -r requirements.txt # install InferenceYOLOv3 PyTorch Hub inference. Models download automatically from the latest YOLOv3 release. import torch # Model model = torch.hub.load("ultralytics/yolov3", "yolov3") # or yolov5n - yolov5x6, custom # Images img = "https://ultralytics.com/images/zidane.jpg" # or file, Path, PIL, OpenCV, numpy, list # Inference results = model(img) # Results results.print() # or .show(), .save(), .crop(), .pandas(), etc. Inference with detect.pydetect.py runs inference on a variety of sources, downloading models automatically from the latest YOLOv3 release and saving results to runs/detect. python detect.py --weights yolov5s.pt --source 0 # webcam img.jpg # image vid.mp4 # video screen # screenshot path/ # directory list.txt # list of images list.streams # list of streams 'path/*.jpg' # glob 'https://youtu.be/Zgi9g1ksQHc' # YouTube 'rtsp://example.com/media.mp4' # RTSP, RTMP, HTTP stream TrainingThe commands below reproduce YOLOv3 COCO results. Models and datasets download automatically from the latest YOLOv3 release. Training times for YOLOv5n/s/m/l/x are 1/2/4/6/8 days on a V100 GPU (Multi-GPU times faster). Use the largest --batch-size possible, or pass --batch-size -1 for YOLOv3 AutoBatch. Batch sizes shown for V100-16GB. python train.py --data coco.yaml --epochs 300 --weights '' --cfg yolov5n.yaml --batch-size 128 yolov5s 64 yolov5m 40 yolov5l 24 yolov5x 16 Tutorials
Train Custom Data 🚀 RECOMMENDED
Tips for Best Training Results ☘️
Multi-GPU Training
PyTorch Hub 🌟 NEW
TFLite, ONNX, CoreML, TensorRT Export 🚀
NVIDIA Jetson platform Deployment 🌟 NEW
Test-Time Augmentation (TTA)
Model Ensembling
Model Pruning/Sparsity
Hyperparameter Evolution
Transfer Learning with Frozen Layers
Architecture Summary 🌟 NEW
Roboflow for Datasets, Labeling, and Active Learning
ClearML Logging 🌟 NEW
YOLOv5 with Neural Magic's Deepsparse 🌟 NEW
Comet Logging 🌟 NEW
Integrations
Tutorials
Train Custom Data 🚀 RECOMMENDED
Tips for Best Training Results ☘️
Multi-GPU Training
PyTorch Hub 🌟 NEW
TFLite, ONNX, CoreML, TensorRT Export 🚀
NVIDIA Jetson platform Deployment 🌟 NEW
Test-Time Augmentation (TTA)
Model Ensembling
Model Pruning/Sparsity
Hyperparameter Evolution
Transfer Learning with Frozen Layers
Architecture Summary 🌟 NEW
Roboflow for Datasets, Labeling, and Active Learning
ClearML Logging 🌟 NEW
YOLOv5 with Neural Magic's Deepsparse 🌟 NEW
Comet Logging 🌟 NEW
Integrations

Experience seamless AI with Ultralytics HUB ⭐, the all-in-one solution for data visualization, YOLO 🚀 model training and deployment, without any coding. Transform images into actionable insights and bring your AI visions to life with ease using our cutting-edge platform and user-friendly Ultralytics App. Start your journey for Free now!  Why YOLOv3
Why YOLOv3
YOLOv3 has been designed to be super easy to get started and simple to learn. We prioritize real-world results.
Our new YOLOv5 release v7.0 instance segmentation models are the fastest and most accurate in the world, beating all current SOTA benchmarks. We've made them super simple to train, validate and deploy. See full details in our Release Notes and visit our YOLOv5 Segmentation Colab Notebook for quickstart tutorials. Segmentation Checkpoints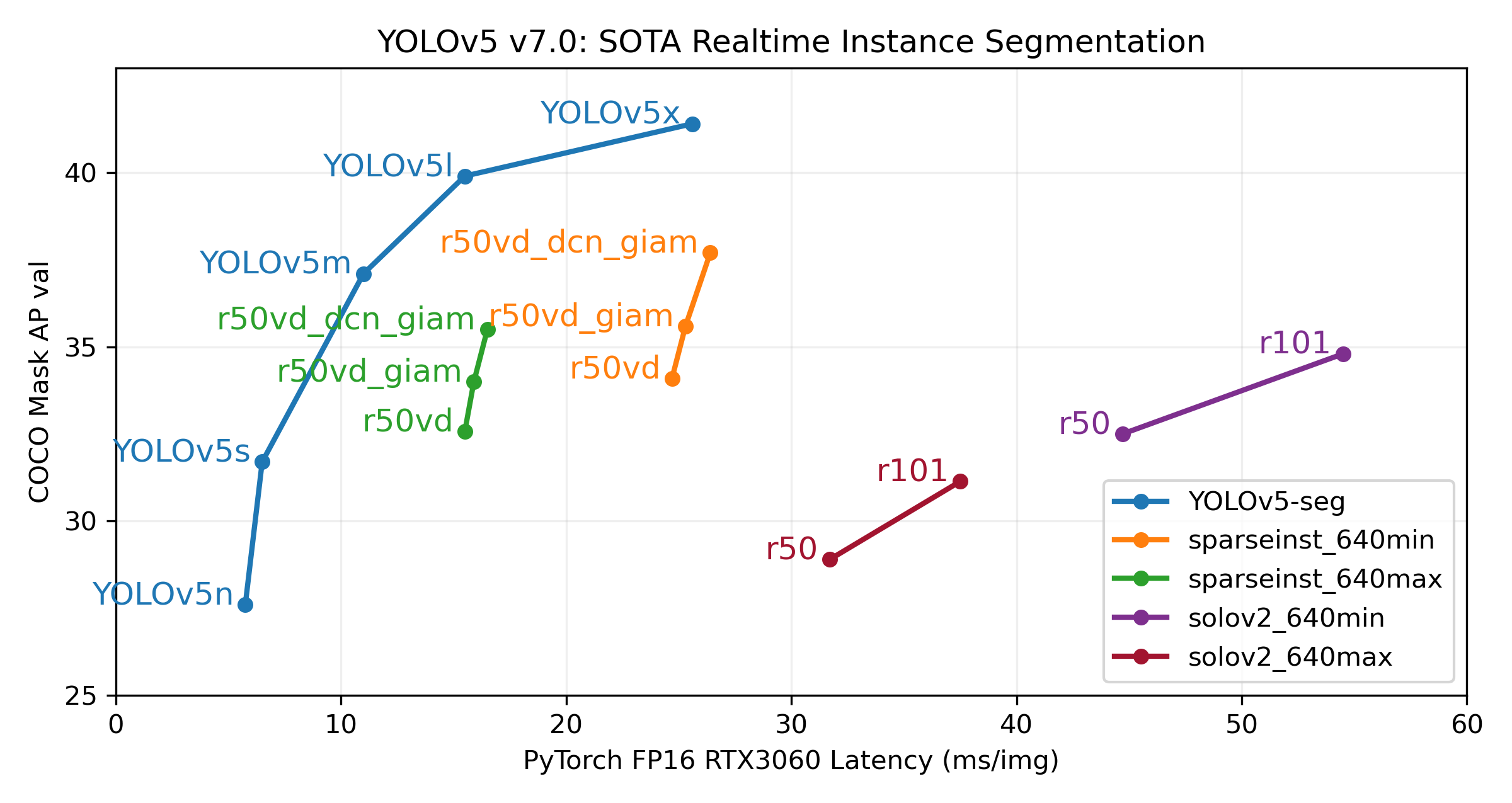
We trained YOLOv5 segmentations models on COCO for 300 epochs at image size 640 using A100 GPUs. We exported all models to ONNX FP32 for CPU speed tests and to TensorRT FP16 for GPU speed tests. We ran all speed tests on Google Colab Pro notebooks for easy reproducibility. Model size(pixels) mAPbox50-95 mAPmask50-95 Train time300 epochsA100 (hours) SpeedONNX CPU(ms) SpeedTRT A100(ms) params(M) FLOPs@640 (B) YOLOv5n-seg 640 27.6 23.4 80:17 62.7 1.2 2.0 7.1 YOLOv5s-seg 640 37.6 31.7 88:16 173.3 1.4 7.6 26.4 YOLOv5m-seg 640 45.0 37.1 108:36 427.0 2.2 22.0 70.8 YOLOv5l-seg 640 49.0 39.9 66:43 (2x) 857.4 2.9 47.9 147.7 YOLOv5x-seg 640 50.7 41.4 62:56 (3x) 1579.2 4.5 88.8 265.7 All checkpoints are trained to 300 epochs with SGD optimizer with lr0=0.01 and weight_decay=5e-5 at image size 640 and all default settings.Runs logged to https://wandb.ai/glenn-jocher/YOLOv5_v70_official Accuracy values are for single-model single-scale on COCO dataset.Reproduce by python segment/val.py --data coco.yaml --weights yolov5s-seg.pt Speed averaged over 100 inference images using a Colab Pro A100 High-RAM instance. Values indicate inference speed only (NMS adds about 1ms per image). Reproduce by python segment/val.py --data coco.yaml --weights yolov5s-seg.pt --batch 1 Export to ONNX at FP32 and TensorRT at FP16 done with export.py. Reproduce by python export.py --weights yolov5s-seg.pt --include engine --device 0 --half Segmentation Usage ExamplesYOLOv5 segmentation training supports auto-download COCO128-seg segmentation dataset with --data coco128-seg.yaml argument and manual download of COCO-segments dataset with bash data/scripts/get_coco.sh --train --val --segments and then python train.py --data coco.yaml. # Single-GPU python segment/train.py --data coco128-seg.yaml --weights yolov5s-seg.pt --img 640 # Multi-GPU DDP python -m torch.distributed.run --nproc_per_node 4 --master_port 1 segment/train.py --data coco128-seg.yaml --weights yolov5s-seg.pt --img 640 --device 0,1,2,3 ValValidate YOLOv5s-seg mask mAP on COCO dataset: bash data/scripts/get_coco.sh --val --segments # download COCO val segments split (780MB, 5000 images) python segment/val.py --weights yolov5s-seg.pt --data coco.yaml --img 640 # validate PredictUse pretrained YOLOv5m-seg.pt to predict bus.jpg: python segment/predict.py --weights yolov5m-seg.pt --data data/images/bus.jpg model = torch.hub.load( "ultralytics/yolov5", "custom", "yolov5m-seg.pt" ) # load from PyTorch Hub (WARNING: inference not yet supported)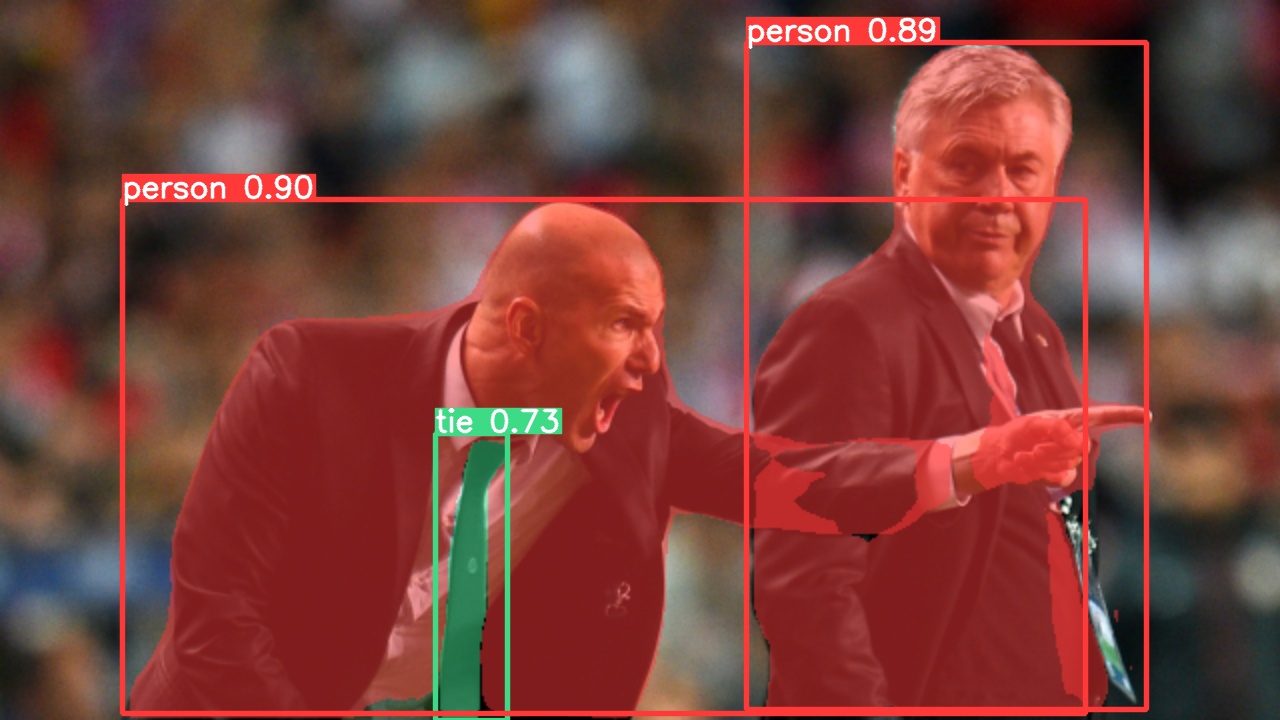
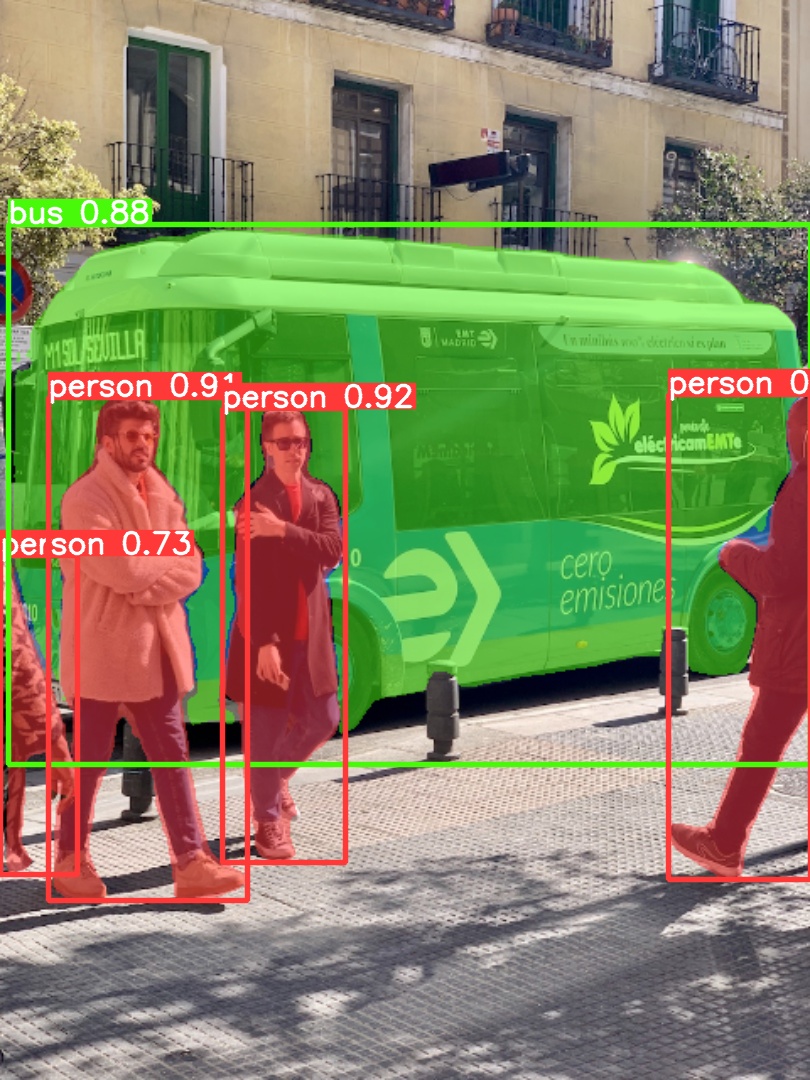 Export
Export
Export YOLOv5s-seg model to ONNX and TensorRT: python export.py --weights yolov5s-seg.pt --include onnx engine --img 640 --device 0 ClassificationYOLOv5 release v6.2 brings support for classification model training, validation and deployment! See full details in our Release Notes and visit our YOLOv5 Classification Colab Notebook for quickstart tutorials. Classification CheckpointsWe trained YOLOv5-cls classification models on ImageNet for 90 epochs using a 4xA100 instance, and we trained ResNet and EfficientNet models alongside with the same default training settings to compare. We exported all models to ONNX FP32 for CPU speed tests and to TensorRT FP16 for GPU speed tests. We ran all speed tests on Google Colab Pro for easy reproducibility. Model size(pixels) acctop1 acctop5 Training90 epochs4xA100 (hours) SpeedONNX CPU(ms) SpeedTensorRT V100(ms) params(M) FLOPs@224 (B) YOLOv5n-cls 224 64.6 85.4 7:59 3.3 0.5 2.5 0.5 YOLOv5s-cls 224 71.5 90.2 8:09 6.6 0.6 5.4 1.4 YOLOv5m-cls 224 75.9 92.9 10:06 15.5 0.9 12.9 3.9 YOLOv5l-cls 224 78.0 94.0 11:56 26.9 1.4 26.5 8.5 YOLOv5x-cls 224 79.0 94.4 15:04 54.3 1.8 48.1 15.9 ResNet18 224 70.3 89.5 6:47 11.2 0.5 11.7 3.7 ResNet34 224 73.9 91.8 8:33 20.6 0.9 21.8 7.4 ResNet50 224 76.8 93.4 11:10 23.4 1.0 25.6 8.5 ResNet101 224 78.5 94.3 17:10 42.1 1.9 44.5 15.9 EfficientNet_b0 224 75.1 92.4 13:03 12.5 1.3 5.3 1.0 EfficientNet_b1 224 76.4 93.2 17:04 14.9 1.6 7.8 1.5 EfficientNet_b2 224 76.6 93.4 17:10 15.9 1.6 9.1 1.7 EfficientNet_b3 224 77.7 94.0 19:19 18.9 1.9 12.2 2.4 Table Notes (click to expand) All checkpoints are trained to 90 epochs with SGD optimizer with lr0=0.001 and weight_decay=5e-5 at image size 224 and all default settings.Runs logged to https://wandb.ai/glenn-jocher/YOLOv5-Classifier-v6-2 Accuracy values are for single-model single-scale on ImageNet-1k dataset.Reproduce by python classify/val.py --data ../datasets/imagenet --img 224 Speed averaged over 100 inference images using a Google Colab Pro V100 High-RAM instance.Reproduce by python classify/val.py --data ../datasets/imagenet --img 224 --batch 1 Export to ONNX at FP32 and TensorRT at FP16 done with export.py. Reproduce by python export.py --weights yolov5s-cls.pt --include engine onnx --imgsz 224 Classification Usage ExamplesYOLOv5 classification training supports auto-download of MNIST, Fashion-MNIST, CIFAR10, CIFAR100, Imagenette, Imagewoof, and ImageNet datasets with the --data argument. To start training on MNIST for example use --data mnist. # Single-GPU python classify/train.py --model yolov5s-cls.pt --data cifar100 --epochs 5 --img 224 --batch 128 # Multi-GPU DDP python -m torch.distributed.run --nproc_per_node 4 --master_port 1 classify/train.py --model yolov5s-cls.pt --data imagenet --epochs 5 --img 224 --device 0,1,2,3 ValValidate YOLOv5m-cls accuracy on ImageNet-1k dataset: bash data/scripts/get_imagenet.sh --val # download ImageNet val split (6.3G, 50000 images) python classify/val.py --weights yolov5m-cls.pt --data ../datasets/imagenet --img 224 # validate PredictUse pretrained YOLOv5s-cls.pt to predict bus.jpg: python classify/predict.py --weights yolov5s-cls.pt --data data/images/bus.jpg model = torch.hub.load( "ultralytics/yolov5", "custom", "yolov5s-cls.pt" ) # load from PyTorch Hub ExportExport a group of trained YOLOv5s-cls, ResNet and EfficientNet models to ONNX and TensorRT: python export.py --weights yolov5s-cls.pt resnet50.pt efficientnet_b0.pt --include onnx engine --img 224 EnvironmentsGet started in seconds with our verified environments. Click each icon below for details. We love your input! We want to make contributing to YOLOv3 as easy and transparent as possible. Please see our Contributing Guide to get started, and fill out the YOLOv3 Survey to send us feedback on your experiences. Thank you to all our contributors!  License
License
YOLOv3 is available under two different licenses: AGPL-3.0 License: See LICENSE file for details. Enterprise License: Provides greater flexibility for commercial product development without the open-source requirements of AGPL-3.0. Typical use cases are embedding Ultralytics software and AI models in commercial products and applications. Request an Enterprise License at Ultralytics Licensing. ContactFor YOLOv3 bug reports and feature requests please visit GitHub Issues, and join our Discord community for questions and discussions! |

【本文地址】
今日新闻 |
点击排行 |
|
推荐新闻 |
图片新闻 |
|
专题文章 |