| 拯救pandas计划(18) | 您所在的位置:网站首页 › 统计字段出现次数 › 拯救pandas计划(18) |
拯救pandas计划(18)
|
拯救pandas计划(18)——统计列中元素包含某字符的次数
最近发现周围的很多小伙伴们都不太乐意使用pandas,转而投向其他的数据操作库,身为一个数据工作者,基本上是张口pandas,闭口pandas了,故而写下此系列以让更多的小伙伴们爱上pandas。 系列文章说明: 系列名(系列文章序号)——此次系列文章具体解决的需求 平台: windows 10 python 3.8 pandas >=1.2.4 数据需求构造测试数据如下,想要统计指定字符的数量。 import pandas as pd s = pd.Series(['Brown', 'Golden', 'Oracle', 'Mysql', 'Python', 'White', 'Apple']) 需求处理
需求处理
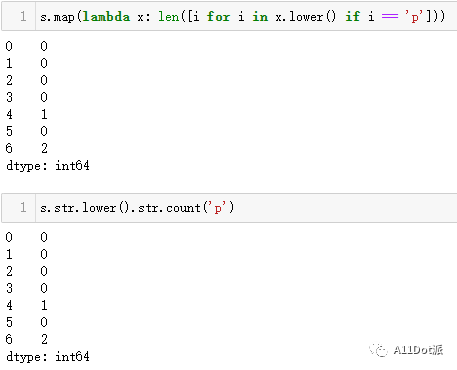
统计字符串汇总包含字符'p'的数量,不区分大小写。 方法一:使用列表推导式 s.map(lambda x: len([i for i in x.lower() if i == 'p']))为了不区分大小写,将字符串全部小写再判断'p'在里面出现的次数。 方法二:count统计计数 pandas.str下包含count方法可以对字符串内的字符进行统计,在此之前使用lower小写字符串。 s.str.lower().str.count('p')两种方法均可实现需求,结果如下:
方法三:str.findall 统计两个字符只需要在上一单字符示例中增加一个字符就行,例如推导式的条件中添加or i == 'a',然而当指定字符或字符对增多时代码会显得厚重,不易维护。 s.str.findall(r'[ap]', flags=re.I).str.len()这种通过正则表达式的方式对字符内容进行匹配,返回对象为列表,再调用len方法统计列表的长度。 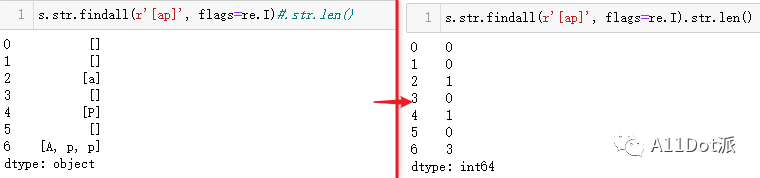
方法四:str.extractall 除findall外,extractall同样可以对字符串数据进行匹配。 s.str.extractall(r'([ap])', flags=re.I).groupby(level=0).size()与findall不同的是生成的对象为DataFrame,并且增加了一组match索引,统计数量需要对原索引聚合再返回各组数量大小,如了解groupby.filter方法可将此extractall的执行顺序置后。 上两种方法仅对字符串中包含指定字符其一即可,如'Oracle'只包含'a','Python'只包含'p','Apple'两个都包含。 在上一示例中,增加仅统计指定字符全部在字符串内的条件 方法五:extractall分组返回 尝试使用findall方法对于统计这种需求可能不好着手弄,而使用extractall却刚刚好。 匹配要求:分组1:'ap',分组2:'oe',字符串中至少含有'ap'中的一个,且至少含有'oe'中的一个。 findall结果: 
extractall结果: s.str.extractall(r'([ap])?([oe])?', flags=re.I).groupby(level=0).count().replace({0: pd.NA}).sum(axis=1, skipna=False)
count统计每个字符串包含每个分组的数量,为了能够正常统计满足要求的字符串数量,需要对0替换成pd.NA,在sum中不计算空缺值,统计的结果就只对满足要求的字符串进行了统计,如'Oracle'即含有'a'又含有'e'。 总结本文从匹配单字符到多分组字符,循序渐进地实现各个需求,也仅仅为最近的使用心得,对于当前需求实现的方式仍有很多,选取几种针对于本文的方式来探索某些函数方法的使用,如对此有其他见解可与作者交流。 学习是经常性的行为。 于二零二二年六月十三日作 |
 2. 统计字符串包含指定两个字符('a'和'p')的数量和,不区分大小写
2. 统计字符串包含指定两个字符('a'和'p')的数量和,不区分大小写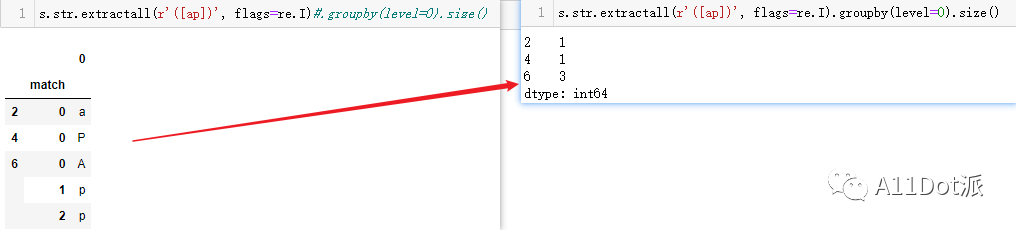
【本文地址】