| 聚类算法:K | 您所在的位置:网站首页 › spss英语单词 › 聚类算法:K |
聚类算法:K
|
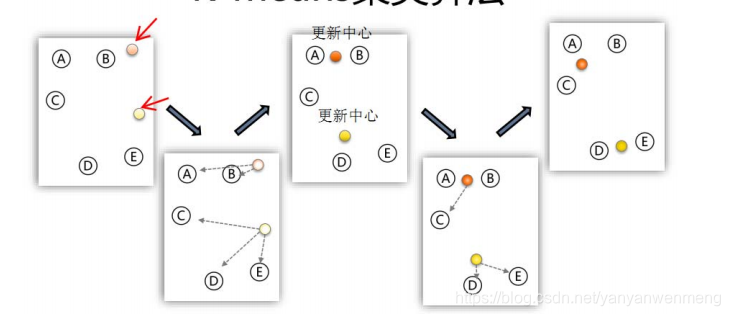
笔记整理来自清风老师的数学建模课程: https://www.bilibili.com/video/BV1gJ411k7X4?from=search&seid=15370102798756305377 目录 1. 聚类模型的概念 2. K-means聚类算法(K均值) 2.1 步骤 2.2 评价 3. K-means++ 算法 3.1 算法步骤 4. 例题讲解——K-means算法 4.1 K-mean算法步骤 4.1.1 导入数据 4.1.2 SPSS操作 4.2 结果分析 4.3 K-means算法的讨论 4.3.1 聚类个数确定与量纲不一致问题 4.3.2 Z标准化(无量纲化)SPSS操作步骤 5. 系统聚类(层次聚类) 5.1 系统聚类原理 5.1.1 例题1:根据成绩,对学生进行分类 5.1.1 例题2:根据成绩,对课程进行分类 5.1.3 例题3 :根据月人均消费对省进行分类 5.1.4 类与类之间的距离 5.2 最短距离系统聚类法 5.3 最长距离系统聚类法 5.4 聚类分析需要注意的问题 6. SPSS操作步骤——系统聚类 6.1 系统聚类算法流程 6.2 SPSS操作步骤 6.3 结果分析 6.4 系统聚类算法的优缺点 1. 聚类模型的概念 “物以类聚,人以群分”,所谓的聚类,就是将样本划分为由类似的对象组成的多个类的过程。 聚类后,我们可以更加准确的在每个类中单独使用统计模型进行估计、分析或预测; 也可以探究不同类之间的相关性和主要差异。 聚类和上一讲分类的区别:分类是已知类别的,聚类未知 2. K-means聚类算法(K均值) 2.1 步骤 指定需要划分的簇[cù]的个数K值(类的个数); 一个类也叫一个簇。随机地选择K个数据对象作为初始的聚类中心 (不一定要是我们的样本点); K个数据对象不一定是样本,可以为随机的数据计算其余的各个数据对象到这K个初始聚类中心 的距离,把数据对象划归到距离它最近的那个中心所处在的簇类中; 调整新类并且重新计算出新类的中心; 类的中心有点像样本的重心循环步骤三和四,看中心是否收敛(不变),如 果收敛或达到迭代次数则停止循环; 结束。
https://www.naftaliharris.com/blog/visualizing%E2%80%90k%E2%80%90means%E2%80%90clustering/ 算法流程图:
K-means++算法选择初始聚类中心的基本原则是:初始聚类中心之间的相互距离要尽可能的远。 3.1 算法步骤算法描述如下:(只对K-mean算法“初始化K个聚类中心”这一步进行了优化) 步骤一: 随机选取一个样本作为第一个聚类中心; 步骤二: 计算每个样本与当前已有聚类中心的最短距离(即与最 近一个聚类中心的距离),这个值越大,表示被选取作为聚类中 心的概率较大;最后,用轮盘法(依据概率大小来进行抽选)选 出下一个聚类中心; 步骤三: 重复步骤二,直到选出K个聚类中心。选出初始点后,就继续使用标准的K-means算法了。 4. 例题讲解——K-means算法比如现在需要对省份进行聚类,看看哪些省份的消费习惯比较接近。数据如下: 数据来源:嵩天Python机器学习算法课程案例省份食品衣着家庭设备医疗交通娱乐居住杂项北京2959.19730.79749.41513.34467.871141.82478.42457.64天津2459.77495.47697.33302.87284.19735.97570.84305.08河北1495.63515.9362.37285.32272.95540.58364.91188.63山西1406.33477.77290.15208.57201.5414.72281.84212.1内蒙古1303.97524.29254.83192.17249.81463.09287.87192.96辽宁1730.84553.9246.91279.81239.18445.2330.24163.86吉林1561.86492.42200.49218.36220.69459.62360.48147.76黑龙江1410.11510.71211.88277.11224.65376.82317.61152.85上海3712.31550.74893.37346.935271034.98720.33462.03江苏2207.58449.37572.4211.92302.09585.23429.77252.54浙江2629.16557.32689.73435.69514.66795.87575.76323.36安徽1844.78430.29271.28126.33250.56513.18314151.39福建2709.46428.11334.12160.77405.14461.67535.13232.29江西1563.78303.65233.81107.9209.7393.99509.39160.12山东1675.75613.32550.71219.79272.59599.43371.62211.84河南1427.65431.79288.55208.14217337.76421.31165.32湖南1942.23512.27401.39206.06321.29697.22492.6226.45湖北1783.43511.88282.84201.01237.6617.74523.52182.52广东3055.17353.23564.56356.27811.88873.061082.82420.81广西2033.87300.82338.65157.78329.06621.74587.02218.27海南2057.86186.44202.72171.79329.65477.17312.93279.19重庆2303.29589.99516.21236.55403.92730.05438.41225.8四川1974.28507.76344.79203.21240.24575.1430.36223.46贵州1673.82437.75461.61153.32254.66445.59346.11191.48云南2194.25537.01369.07249.54290.84561.91407.7330.95西藏2646.61839.7204.44209.11379.3371.04269.59389.33陕西1472.95390.89447.95259.51230.61490.9469.1191.34甘肃1525.57472.98328.9219.86206.65449.69249.66228.19青海1654.69437.77258.78303244.93479.53288.56236.51宁夏1375.46480.89273.84317.32251.08424.75228.73195.93新疆1608.82536.05432.46235.82250.28541.3344.85214.4 4.1 K-mean算法步骤 4.1.1 导入数据
第一步:选择【分析】【分类】【K-means聚类】
第二步:【变量】相当于指标,【个案标注依据】相当于分类依据。聚类数我们需要分为聚类就填几类。
第三步:【迭代次数】可以调大一些,默认为10次。K均值聚类是不断进行迭代的,如果到达了最大迭代次数还未收敛,就结束了,所以需要调大一些,保证尽量收敛。
第四步:【聚类成员】可以生成一个变量,表明这个城市是属于哪一类的。
第五步:勾选上【每个个案的聚类信息】
说明初始的聚类中心为上海和内蒙古。
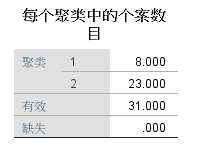
1、2代表聚类的类别。比如北京、天津、上海分为了第一类,河北、山西等地方分为了第二类。
代表分为第一类的有8个城市,分为第2类的有23个城市。
【看哪个好解释就取哪个k】 ( 2 )数据的量纲不一致怎么办? 答:如果数据的量纲不一样,那么算距离时就没有意义。例如:如果 X1 单位是米,X2 单位是吨,用距离公式计算就会出现“米的平方”加上“吨的平方” 再开平方,最后算出的东西没有数学意义,这就有问题了。 【比如上面的例题单位都是元,所以量纲是一致的。如果单位不一致,需要进行无量纲化】
标准差 4.3.2 Z标准化(无量纲化)SPSS操作步骤第一步:选中需要进行Z标准化的数据,选中【分析】【描述统计】【描述】
第二步:将需要标准化的变量放入【变量】中,勾选【将标准化值另存为变量】。
在【数据视图】中就可以得到Z标准化后的结果了。后面变量选择的时候就可以选择Z标准化后的值了。
系统聚类不需要事先给定K值。 5.1 系统聚类原理 系统聚类的合并算法通过计算两类数据点间的距离,对 最为接近的两类数据点进行组合,并反复迭代这一过程,直 到将所有数据点合成一类,并生成聚类谱系图。
对样本进行分类
步骤: 第一步:只考虑数学成绩。
第二步:只考虑数学和物理成绩
【分类准则】距离近的样本聚为一类
样本与样本之间的常用距离。
绝对值距离:一般用于网状道路。
欧式距离(除了网格中用的绝对值距离,基本大多数情况用的都是欧式距离) 实例计算:65(X),61(Y)
5.1.1 例题2:根据成绩,对课程进行分类 对指标进行分类
指标与指标间的距离(对指标进行分类时才需要计算之间间的距离):
5.1.3 例题3 :根据月人均消费对省进行分类
一般默认使用的位重心法 。
样本1和2之间的距离 sqrt((65-77)^2+(61-77)^2+(72-76)^2+(84-64)^2+(81-70)^2+(79-55)^2)
样本1和3之间的距离(G31=G13=39.7):第一行和第3行对应的数相减,求欧式距离即可。
样本5和3之间的距离(第5行第3列):G53=43.6
根据欧式距离,发现G1和G5间的距离最短: 首先将G1和G5聚为一类,命名为G6 计算各类(G6、G2、G3、G4)与新类G6之间的距离,发现G2和G4的距离最短: 然后是G2和G4聚为一类,命名为G7 计算各类(G6、G7、G3)与新类G7之间的距离,发现G6和G7的距离最短: 然后将G7和G6聚为一类,命名为G8 计算各类(G8和G3)与新类G8之间的距离,发现G3和G8的距离最短: 最后将G3和G8聚为一类,命名为G9 都聚为1类了,聚类结束。
如何进行分类:
比如我们需要划分为3类,我们画一根绿色的线条,就将学生(样本)划分为了3类。学生1和5为一类,学生2和4为1类,学生3自成一类。 5.3 最长距离系统聚类法
6. SPSS操作步骤——系统聚类 6.1 系统聚类算法流程 系统(层次)聚类的算法流程: 将每个对象看作一类,计算两两之间的最小距离; 将距离最小的两个类合并成一个新类; 重新计算新类与所有类之间的距离; 重复二三两步,直到所有类最后合并成一类; 结束。 6.2 SPSS操作步骤 第一步:选择【分析】【分类】【系统聚类】
第三步:在【图】中将【谱系图】勾选上。
第四步:【方法】中,计算距离时,【区间】可以使用软件默认的【平方欧式距离】,也可以使用欧式距离。如果指标单位不统一,需要对指标进行标准化。一把选择Z标准化【Z得分】。如果单位是统一的就可以不用进行标准化。
红色的线可以将样本分为2类,绿色的线可以将样本分为3类。
如何选择最佳的K值? 肘部法则:用图形估计聚类的数量。
第一步:将聚合系数(即绿框中的系数)放入到excel表格中。
第二步:对聚合系数进行降序排序。
第三步:在插入的图表中选择散点图。
第四步:对图表进行美化。双击X轴的数据,对其最小值设置为1(最小样本数),最大值设置为30(最大样本数).因为有1-30个样本。
第五步:美化后的图表,加上横坐标和纵坐标的描述。
|

















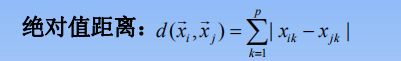
















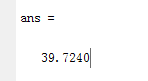





















【本文地址】