| 大数据总结【第九章:Spark】 | 您所在的位置:网站首页 › spark基于什么语言 › 大数据总结【第九章:Spark】 |
大数据总结【第九章:Spark】
|
Spark的主要特点
运行速度快:使用DAG执行引擎以支持循环数据流与内存计算容易使用。:支持使用Scala、 Java、 Python和R语言进行编程,可以通过Spark Shell进行交互式编程通用性: Spark 提供了完整而强大的技术栈,包括SQL查询、流式计算、机器学习和图算法组件运行模式多样:可运行于独立的集群模式中,可运行于Hadoop中,也可运行于Amazon EC2等云环境中,并且可以访问HDFS、Cassandra、HBase、Hive 等多种数据源
SCALA的简单语句
Spark与hadoop的对比
Scala是一门现代的多范式编程语言,运行于Java平台(JVM,Java虚拟机),并兼容现有的Java程序 Scala的特性: Scala具备强大的并发性,支持函数式编程,可以更好地支持分布式系统Scala语法简洁,能提供优雅的API,Scala兼容Java,运行速度快,且能融合到Hadoop生态圈中,Scala是Spark的主要编程语言,但Spark还支持Java、Python,R作为编程语言Scala的优势是提供了REPL ( Read-Eval-Print Loop,交互式解释器), 提高程序开发效率 Hadoop存在如下一些缺点:表达能力有限磁盘I0开销大.延迟高 – 任务之间的衔接涉及I0开销 – 在前一个任务执行完成之前,其他任务就无法开始,难以胜任复杂、多阶段的计算任务Spark在借鉴Hadoop MapReduce优点的同时,很好地解决了MapReduce所面临的问题 相比于Hadoop MapReduce,Spark 主要具有如下优点: ●Spark的计算模式也属于MapReduce,但不局限于Map和Reduce操作,还提供了多种数据集操作类型,编程模型比Hadoop,MapReduce更灵活 ●Spark提供了内存计算,可将中间结果放到内存中,对于迭代运算效率更高 ●Spark基于DAG的任务调度执行机制,要优于Hadoop MapReduce的迭代执行机制. ●使用Hadoop进行迭代计算非常耗资源. ●Spark将数据载入内存后,之后的迭代计算都可以直接使用内存中的中间结果作运算,避免了从磁盘中频繁读取数据 ●复杂的批量数据处理:通常时间跨度在数十分钟到数小时之间 ●基于历史数据的交互式查询:通常时间跨度在数十秒到数分钟之间 ●基于实时数据流的数据处理:通常时间跨度在数百毫秒到数秒之间 各组件的功能Spark生态系统已经成为伯克利数据分析软件栈BDAS ( Berkeley Data Analytics Stack )的重要组成部分
总体而言,Spark 运行架构具有以下特点: (1)每个Application都有自己专属的Executor进程并且该进程在Application运行期间一直驻留。Executor进程以多线程的方式运行Task (2)Spark运行过程与资源管理器无关,只要能够获取Executor进程并保持通信即可 (3)Task采用了数据本地性和推测执行等优化机制 RDD的编程,执行过程示意图 最少10分
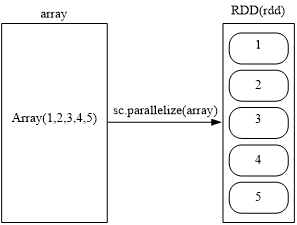
(1)从本地文件系统中加载数据创建 三条语句是完全等价的,可以使用其中任意一种方式 2. 通过并行集合(数组)创建RDD可以调用SparkContext的parallelize方法,在Driver中 -一个已经存在的集合(数组).上 创建。 ●对于RDD而言,每一次转换操作都会产生不同的RDD,供给下一个“转换”使用 ●转换得到的RDD是惰性求值的,也就是说,整个转换过程只是记录了转换的轨迹,并不会发生真正的计算,只有遇到.行动操作时,才会发生真正的计算,开始从血缘关系源头开始,进行物理的转换操作
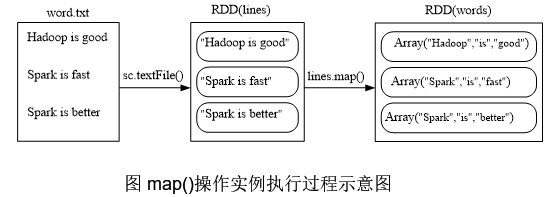
map(func)操作将每个元素传递到函数func中,并将结果返回为-一个新的数据集
groupByKey()应用(K.V)键值对的数据集时,返回一个新的(K Iterable)形式数据集
reduceByKey(func)应用于(K,V)键值对的数据集时,返回- -个新的(K, V)形式的数据集,其中的每个值是将每个key传递到函数func中进行聚合后得到的结果 行动操作是真正触发计算的地方。Spark程序执行到行动操作时,才会执行真正的计算,从文件中加载数据,完成一次又一- 次转换操作,最终,完成行动操作得到结果。 表常用的RDD行动操作API 操作含义count()返回数据集中的元素个数collect()以数组的形式返回数据集中的所有元素first()返回数据集中的第一一个元素_take(n)以数组的形式返回数据集中的前n个元素reduce(func)通过函数func (输入两个参数并返回一个值)聚合数据集中的元素foreach(func)将数据集中的每个元素传递到函数func中运行
所谓(的“惰性机制”是指,整个转换过程只是记录了转换的轨迹,并不会发生真正的计算,只有遇到行动操作时,才会触发“从头到尾”的真正的计算。这里给出-段简单的语句来解释Spark的惰性机制。 scala> val lines = sc.textFile("data.txt) scala> val linel engths = lines.map(s => s.length) scala> val totall ength = lineL engths.reduce((a, b)=> a + b) 持久化在Spark中,RDD采用惰性求值的机制,每次遇到行动操作,都会从头开始执行计算。每次调用行动操作,都会触发一次从头开始的计算。这对于迭代计算而言,代价是很大的,迭代计算经常需要多次重复使用同一组数据 下面就是多次计算同一个RDD的例子: scala> val list = List("Hadoop","Spark" "Hive") list: List[String]三List(Hadoop, Spark, Hive) scala> val rdd = sc.parallelize(list) rdd: org.apache.spark.rdd.RDD[String] = ParallelCollectionRDD[22] at parallize at :29 scala> printn(rdd.count())//行动操作,触发次真 正从头到尾的计算 3 scala> println(rd.collect().mkString(",")) //行动操作,触发次真正从头 到尾的计算 Hadoop,Spark,Hive 可以通过持久化(缓存)机制避免这种重复计算的开销可以使用persist()方法对一个RDD标记为持久化之所以说“标记为持久化”,是因为出现persist()语句的地方,并不会马上计算生成RDD并把它持久化,而是要等到遇到第一个行动操作触发真正计算以后,才会把计算结果进行持久化持久化后的RDD将会被保留在计算节点的内存中被后面的行动操作重复使用persist()的圆括号中包含的是持久化级别参数: opersist(MEMORY_ _ONLY): 表示将RDD作为反序列化的对象存储于JVM中,如果内存不足,就要按照LRU原则替换缓存中的内容persist(MEMORY_ AND_ _DISK)表 示将RDD作为反序列化的对象存储在JVM中,如果内存不足,超出的分区将会被存放在硬盘上一般而言,使用cache()方法时,会调用persist(MEMORY_ ONLY)可以使用unpersist()方法手动地把持久化的RDD从缓存中移除针对上面的实例,增加持久化语句以后的执行过程如下: scala> val list a List("Hadoop","Spark ,"Hive") list: List[String] a List(Hadoop, Spark, Hive) scala> val rdd a sc.parallelize(list) rdd: org.apache.spark.rdd.RDD[String] = ParallelCollectionRDD[22] at parallelize at kconsole>:29 scala> rdd.cache() //会调用persist(MEMORY_ ONLY), 但是,语句执行到这里,并不会缓存rdd,因为这时rdd还没有被计算生成 scala> printn(rdd.count() //第一次行动操作,触发次真正从头到尾的计算,这时上面的rdd.cache()才会被执行,把这个rdd放到缓存中 scala> printnd(dd.olct().mkString(",)) //第二次行动操作,不需要触发从头到尾的计算,只需要重复使用上面缓存中的rdd Hadoop,Spark,Hive 分区RDD是弹性分布式数据集,通常RDD很大,会被分成很多个分区,分别保存在不同的节点上 1.分区的作用 (1)增加并行度
假设有一个本地文件word.txt,里面包含了很多行文本,每行文本由多个单词构成,单词之间用空格分隔。可以使用如下语句进行词频统计(即统计每个单词出现的次数): scala> val lines = sc.textlil(le//sr/local/spark/mycode/wordcount/word.txt") scala> val wordCount三lines.ilatMap(line => line.split(" ")). map(word => (word, 1).reduceByKeyl(a, b)=>a+ b) scala> wordCount.collect() scala> wordCount.foreach(println)
1.Spark的出现是为了解决Hadoop MapReduce的不足,试列举Hadoop MapReduce的几个缺陷,并说明Spark具备哪些优点。 Hadoop存在如下一些缺点: 表达能力有限磁盘I0开销大.延迟高 – 任务之间的衔接涉及I0开销 – 在前一个任务执行完成之前,其他任务就无法开始,难以胜任复杂、多阶段的计算任务 相比于Hadoop MapReduce,Spark 主要具有如下优点:Spark的计算模式也属于MapReduce,但不局限于Map和Reduce操作,还提供了多种数据集操作类型,编程模型比Hadoop,MapReduce更灵活Spark提供了内存计算,可将中间结果放到内存中,对于迭代运算效率更高Spark基于DAG的任务调度执行机制,要优于Hadoop MapReduce的迭代执行机制.2.简述Spark生态系统的主要组件。 Spark的生态系统主要包含了Spark Core、Spark SQL、Spark Streaming、MLLib和GraphX等组件 Spark Core:复杂的批量数据处理 Spark SQL:基于历史数据的交互式查询 Spark Streaming:基于实时数据流的数据处理 Mllib:基于历更数据的数据挖掘 GraphX:图结构数据的处理 3.试述如下Spark的几个主要概念:RDD、DAG、阶段、分区、窄依赖、宽依赖 RDD:是Resillient Distributed Dataset (弹性分 布式数据集)的简称,是分布式内存的一个抽象概念,提供了一种高度受限的共享内存模型DAG :是Directed Acyclic Graph (有 向无环图)的简称,反映RDD之间的依赖关系阶段 :是Job的基本调度单位,- 一个Job会分为多组Task,每组Task被称为Stage,或者也被称为TaskSet,代表了- -组关联的、相互之间没有Shuffle依赖关系的任务组成的“任务集”分区 :RDD是弹性分布式数据集,通常RDD很大,会被分成很多个分区,分别保存在不同的节点上窄依赖表现为一个父RDD的分区对应于一个子RDD的分区,或多个父RDD的分区对应于一个RDD分区宽依赖表现为存在一个父RDD的分区对应一个子RDD的多个分区4.简述Spark运行基本流程。 ( 1 )首先为应用构建起基本的运行环境,即由Driver创建一个SparkContext,进行资源的申请、任务的分配和监控 (2)资源管理器为Executor分配资源,并启动Executor进程 ( 3 ) SparkContext根据RDD的依赖关系构建DAG图,DAG 图提交给DAGScheduler解析成Stage,然后把一个个TaskSet提交给底层调度器TaskScheduler处理;Executor向SparkContext申请Task,Task Scheduler将Task发放给Executor运行,并提供;应用程序代码 ( 4) Task在Executor 上运行把执行结果反馈给TaskScheduler,然后反馈给DAGScheduler,运行完毕后写入数据并释放所有资源 5.Spark为什么比mapreduce快? Spark在借鉴Hadoop MapReduce优点的同时,很好地解决了MapReduce所面临的问题 相比于Hadoop MapReduce,Spark 主要具有如下优点: ●Spark的计算模式也属于MapReduce,但不局限于Map和Reduce操作,还提供了多种数据集操作类型,编程模型比Hadoop,MapReduce更灵活 ●Spark提供了内存计算,可将中间结果放到内存中,对于迭代运算效率更高 ●Spark基于DAG的任务调度执行机制,要优于Hadoop MapReduce的迭代执行机制. ●使用Hadoop进行迭代计算非常耗资源. ●Spark将数据载入内存后,之后的迭代计算都可以直接使用内存中的中间结果作运算,避免了从磁盘中频繁读取数据 应用题给出题目要求和代码,要求能画出这个程序执行过程的示意图。 假设有一个本地文件word.txt,里面包含了很多行文本,每行文本由多个单词构成,单词之间用空格分隔。可以使用如下语句进行词频统计(即统计每个单词出现的次数): scala> val lines = sc.textlil(le//sr/local/spark/mycode/wordcount/word.txt") scala> val wordCount三lines.ilatMap(line => line.split(" ")). map(word => (word, 1).reduceByKeyl(a, b)=>a+ b) scala> wordCount.collect() scala> wordCount.foreach(println)
给定一组键值对(“spark”,2),(“hadoop”,6),(“hadoop”,4),(“spark”,6),键值对的key表示图书名称,value表示某天图书销量,请计算每个键对应的平均值,也就是计算每种图书的每天平均销量。 代码: scala> val rdd = sc.parallelize(Array(("spark",2),("hadoop",6),("hadoop",4),("spark",6))) rdd: org.apache.spark.rdd.RDD[(String, Int)] = ParallelCollectionRDD[38] at parallelize at :27 scala> rdd.mapValues(x => (x,1)).reduceByKey((x,y) => (x._1+y._1,x._2 + y._2)).mapValues(x => (x._1 / x._2)).collect() res22: Array[(String, Int)] = Array((spark,4), (hadoop,5))要求: 画出计算图书平均销量过程的示意图。 1.Scala属于哪种编程语言(D)? A.函数式编程语言 B.汇编语言 C.机器语言 D.多范式编程语言 2.以下哪种不属于Scala特性(A)? A.命令式编程 B.函数式编程 C.静态类型 D.不可扩展性 3.以下哪种可以正确计算数组a的长度(D)? A.count() B.take(1) C.tail() D.length 4.以下Scala变量的定义不正确的是哪项(C)? A.val words:String=”Hello World” B.val number=12 C.var number:String=None D.var apple:Double=2 5.以下关于List的定义不正确的一项是(C)。 A.val list=List(12,2,3) B.val list=List(“Hello”,”World”) C.val list:String=List(“a”,”c”) D.val list=ListInt 6.对集(Set)进行操作“Set(3,0,1)+2+2-2”之后的结果为()。 A.Set(3,0,1,2) B.Set(3,0,1) C.Set(3,0) D.以上均不正确 8.下面哪一组全部都是转换操作(C)? A.map、take、reduceByKey B.map、filter、collect C.map、zip、reduceByKey D.join、map、take 9.使用saveAsTextFile存储数据到HDFS,要求数据类型为(D)。 A.List B.Array C.Seq D.RDD 10.Spark 的四大组件下面哪个不是 (D ) A.Spark Streaming B. Mlib C Graphx D.Spark R 11.下面哪个不是 RDD 的特点 (C ) A. 可分区 B 可序列化 C 可修改 D 可持久化 12.Stage 的 Task 的数量由什么决定 (A ) A Partition B Job C Stage D TaskScheduler 13.下面哪个操作是窄依赖 (B ) A join B filter C group D sort 14.下面哪个操作肯定是宽依赖 (C ) A map B flatMap C reduceByKey D sample 15.Task 运行在下来哪里个选项中 Executor 上的工作单元 (C ) A Driver program B. spark master C.worker node D Cluster manager 16. Spark SQL目前暂时不支持下列哪种语言A • A. Java • B.Matlab • C.Scala • D.Python 17 RDD操作分为转换(Transformation)和动作(Action)两种类型,下列属于动作(Action)类型的操作的是(B) • A.filter • B.count • C.map • D.groupBy 18 下列说法错误的是(B) • A.在选择Spark Streaming和Storm时,对实时性要求高(比如要求毫秒级响应)的企业更倾向于选择流计算框架Storm • B.RDD提供的转换接口既适用filter等粗粒度的转换,也适合某一数据项的细粒度转换 • C.Spark支持三种类型的部署方式:Standalone,Spark on Mesos,Spark on YARN • D.RDD采用惰性调用,遇到“转换(Transformation)”类型的操作时,只会记录RDD生成的轨迹,只有遇到“动作(Action)”类型的操作时才会触发真正的计算 19下列关于常见的动作(Action)和转换(Transformation)操作的API解释错误的是(B) • A.filter(func):筛选出满足函数func的元素,并返回一个新的数据集 • B.take(n):返回数据集中的第n个元素 • C.count():返回数据集中的元素个数 • D.map(func):将每个元素传递到函数func中,并将结果返回为一个新的数据集 20下列大数据类型与其对应的软件框架不适应的是(D) • A.复杂的批量数据处理:MapReduce • B.基于实时数据流的数据处理:Storm • C.图结构数据的计算:Hive • D.基于历史数据的交互式查询:Impala 填空1.为了使程序运行更快,Spark提供了(RDD),减少了迭代计算时的IO开销。 2.在实际应用中,大数据处理主要包括以下三个类型 ●复杂的批量数据处理 ●基于历史数据的交互式查询 ●基于实时数据流的数据处理 3.RDD的操作类型有(转换操作)和(行动操作)。 |

 Spark的生态系统主要包含了Spark Core、Spark SQL、Spark Streaming、MLLib和GraphX等组件 表1 Spark生态系统组件的应用场景
Spark的生态系统主要包含了Spark Core、Spark SQL、Spark Streaming、MLLib和GraphX等组件 表1 Spark生态系统组件的应用场景 ( 1 )首先为应用构建起基本的运行环境,即由Driver创建一个SparkContext,进行资源的申请、任务的分配和监控 (2)资源管理器为Executor分配资源,并启动Executor进程 ( 3 ) SparkContext根据RDD的依赖关系构建DAG图,DAG 图提交给DAGScheduler解析成Stage,然后把一个个TaskSet提交给底层调度器TaskScheduler处理;Executor向SparkContext申请Task,Task Scheduler将Task发放给Executor运行,并提供;应用程序代码 ( 4) Task在Executor 上运行把执行结果反馈给TaskScheduler,然后反馈给DAGScheduler,运行完毕后写入数据并释放所有资源
( 1 )首先为应用构建起基本的运行环境,即由Driver创建一个SparkContext,进行资源的申请、任务的分配和监控 (2)资源管理器为Executor分配资源,并启动Executor进程 ( 3 ) SparkContext根据RDD的依赖关系构建DAG图,DAG 图提交给DAGScheduler解析成Stage,然后把一个个TaskSet提交给底层调度器TaskScheduler处理;Executor向SparkContext申请Task,Task Scheduler将Task发放给Executor运行,并提供;应用程序代码 ( 4) Task在Executor 上运行把执行结果反馈给TaskScheduler,然后反馈给DAGScheduler,运行完毕后写入数据并释放所有资源
 (2)从分布式文件系统HDFS中加载数据
(2)从分布式文件系统HDFS中加载数据











 (2)减少通信开销
(2)减少通信开销


【本文地址】