|
python 下载道客巴巴文档
环境准备
首先,我们会使用到selenium这个库,直接用pip安装即可,有关于selenium的使用还需要安装浏览器驱动和配置环境变量,在这里就不过多阐述,很多博客中都有教程。
#直接使用pip安装
pip install selenium
其次,我们还需要一个库img2pdf,它可以帮助我们将多张图片合成为pdf,也是直接使用pip安装即可
#直接使用pip安装
pip install img2pdf
案例分析
今天我们的目标是下载道客巴巴中的文档,但是通过网站我们会发现,道客巴巴是通过html5的canvas元素进行各个文档内容的显示,所以,我们没有办法通过获取页面的源代码来进行解析获取图片。
 然后我就想到了使用抓包工具抓取后台返回的图片,很可惜,它返回的是加密文件 然后我就想到了使用抓包工具抓取后台返回的图片,很可惜,它返回的是加密文件
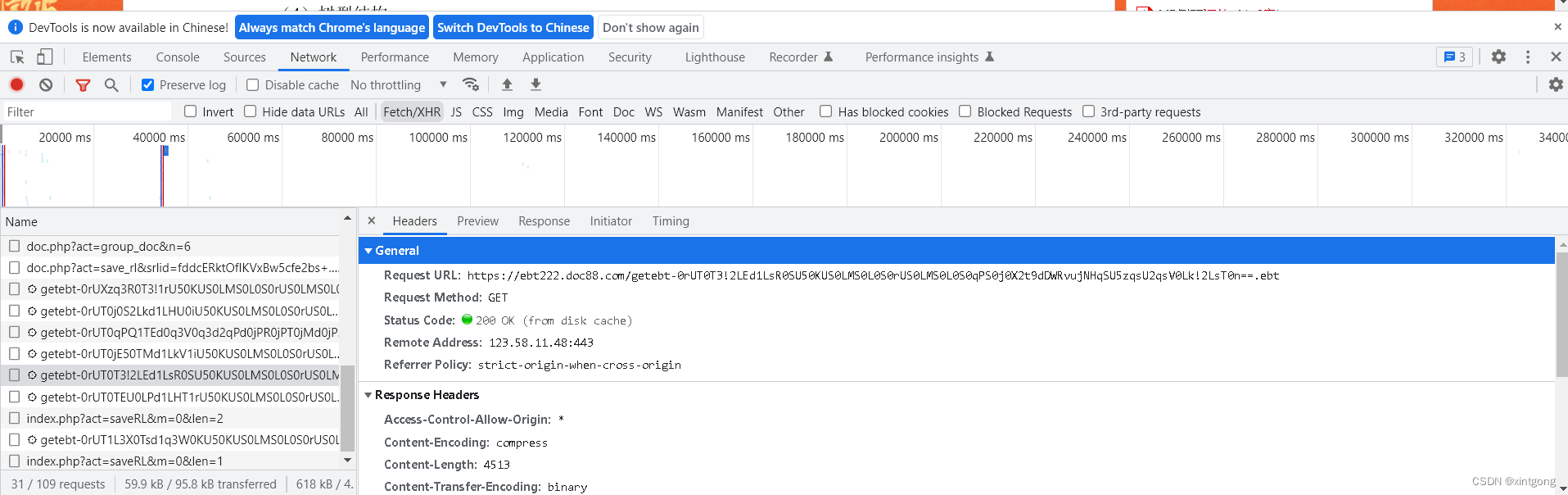 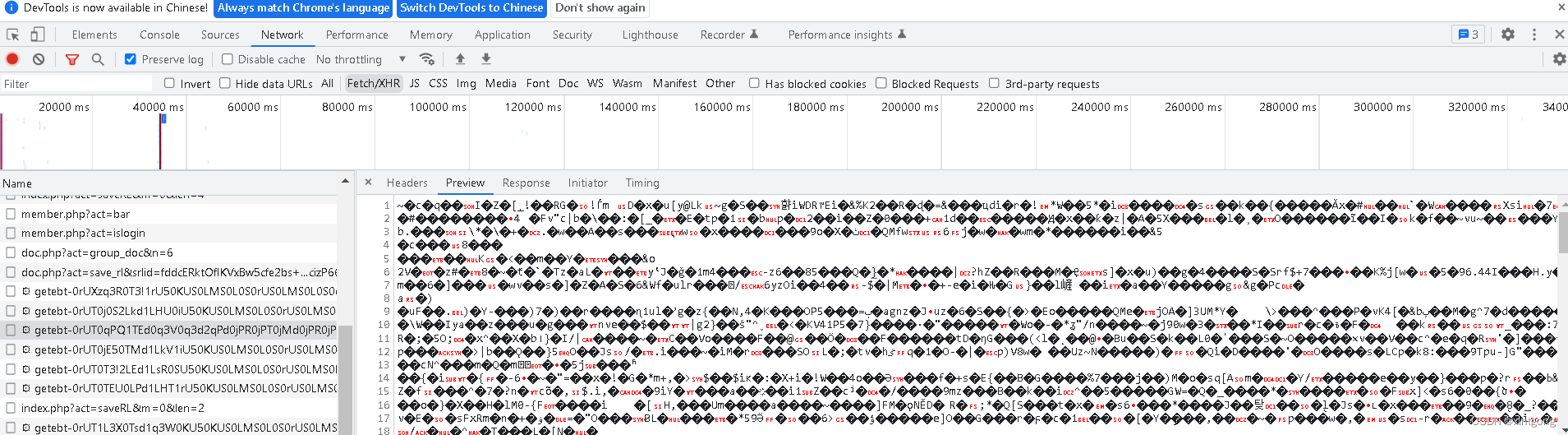 到这里,我就想放弃了,但是我突然灵机一动,js好像可以将canvas转为图片并下载到本地,再利用python调用js实现自动化,最后将下载到本地的图片合成转为pdf,这样子不就可以把文档保存到本地了嘛,说干就干。 到这里,我就想放弃了,但是我突然灵机一动,js好像可以将canvas转为图片并下载到本地,再利用python调用js实现自动化,最后将下载到本地的图片合成转为pdf,这样子不就可以把文档保存到本地了嘛,说干就干。
下载代码实现
我们需要将我们需要的库给导入进来,以便后续调用,代码如下
from selenium import webdriver
import os
import time
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.chrome.options import Options
from lxml import etree
我们需要指定图片的下载地址,这样子才方便后续对图片进行操作,刚好,selenium可以直接实现这样的操作,代码如下
chromeOptions = webdriver.ChromeOptions()
options = Options()
#获取当前的路径,拼接创建一个我们需要指定下载图片的文件夹
path=os.getcwd()+'\data'
#判断文件夹是否存在,不存在创建文件夹
is_exists = os.path.exists(path)
if not is_exists:
os.mkdir(path)
#指定浏览器下载文件夹
prefs = {"download.default_directory": path}
options.add_experimental_option("prefs", prefs)
我们在进入页面时,需要获取当前文档共有多少页数,页码数可以在网页源代码中直接找到 如图
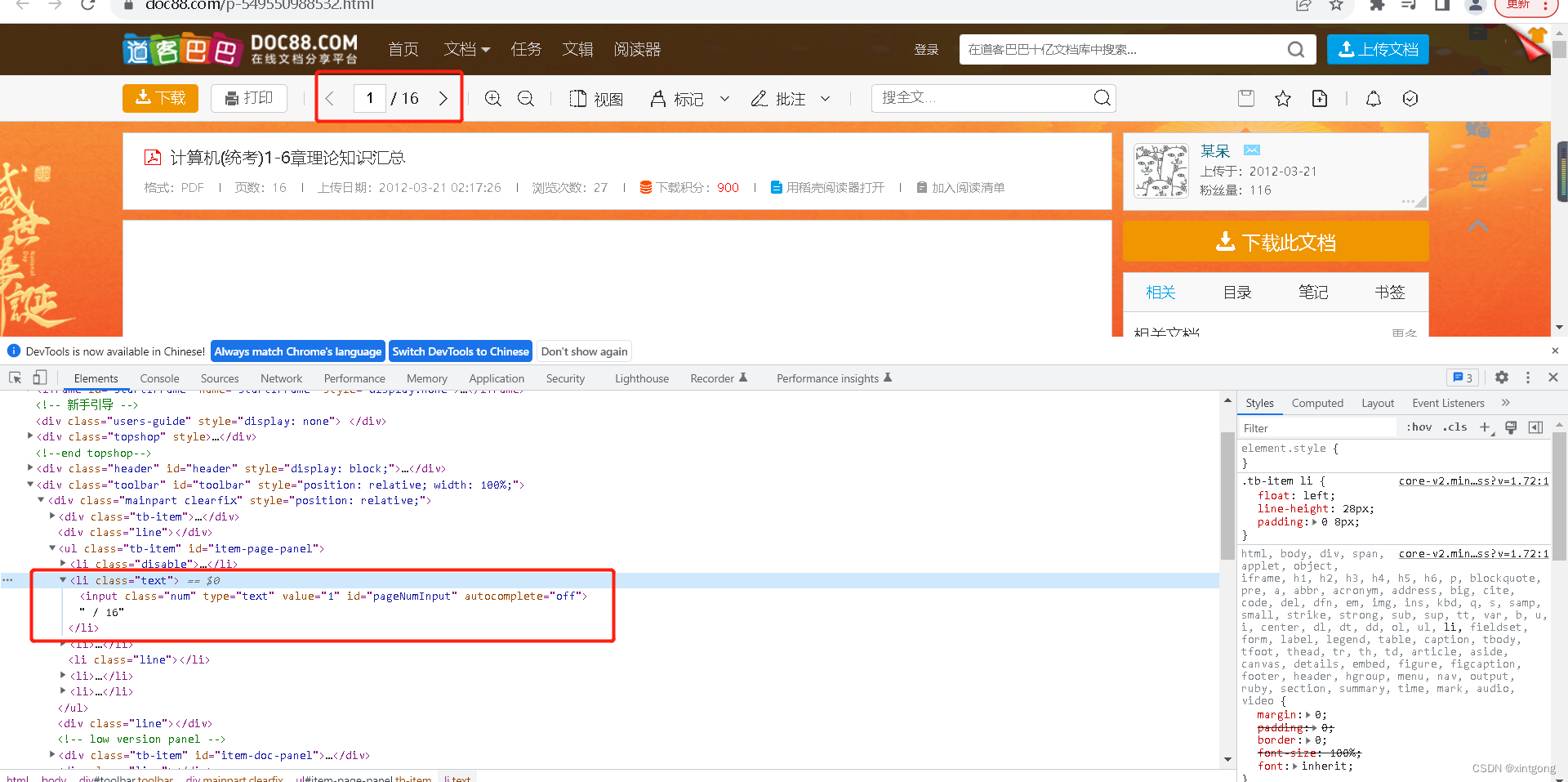 所以我们直接利用selenium获取当前的网页源代码,使用xpath解析网页源代码获取页码数 所以我们直接利用selenium获取当前的网页源代码,使用xpath解析网页源代码获取页码数
#目标网址
url="https://www.doc88.com/p-549550988532.html"
browser.get(url)
#获取网页源代码
text=browser.page_source
html=etree.HTML(text)
#xpath解析源代码,获取总页码数
page_num=html.xpath("//li[@class='text']/text()")[0]
page_num=int(page_num.replace('/ ',''))
print(f'共{page_num}页')
网站在加载的时候,并不会将所有的图片一次加载完毕,而是会加载一定的页数,然后读者需要点击继续免费阅读全文才可以将剩余的内容加载出来,如图
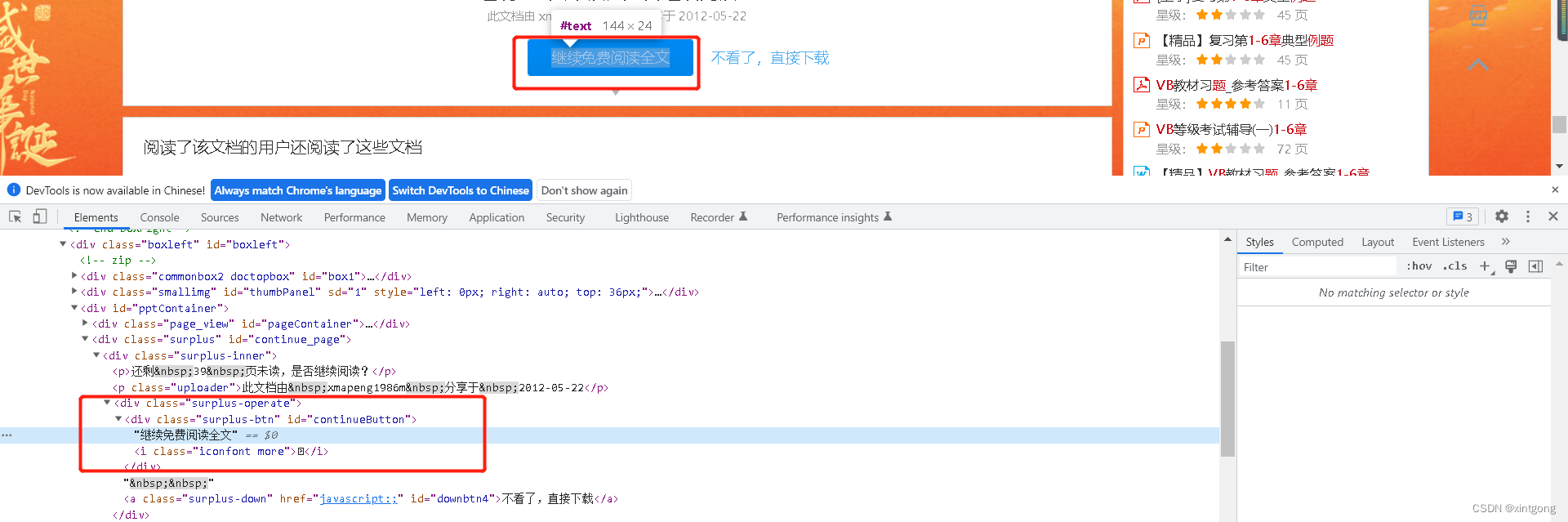 因此,我们需要利用selenium的点击操作,在按钮加载出来时,就点击按钮 因此,我们需要利用selenium的点击操作,在按钮加载出来时,就点击按钮
# #等待网页加载
time.sleep(10)
#等待按钮
element=WebDriverWait(browser, 20).until(EC.visibility_of_element_located((By.XPATH, "//div[@id='continueButton']")))
element.click()
接下来就是下载图片啦,我们可以利用selenium调用js的功能
js = "return action=document.body.scrollHeight"
# 初始化现在滚动条所在高度为0
height = 0
# 当前窗口总高度
new_height = browser.execute_script(js)
k=0
while k |