| LogisticRegression模型对信贷违约的预测以及模型AUC、KS、PSI指标的计算 | 您所在的位置:网站首页 › 模型的ks值怎么算 › LogisticRegression模型对信贷违约的预测以及模型AUC、KS、PSI指标的计算 |
LogisticRegression模型对信贷违约的预测以及模型AUC、KS、PSI指标的计算
|
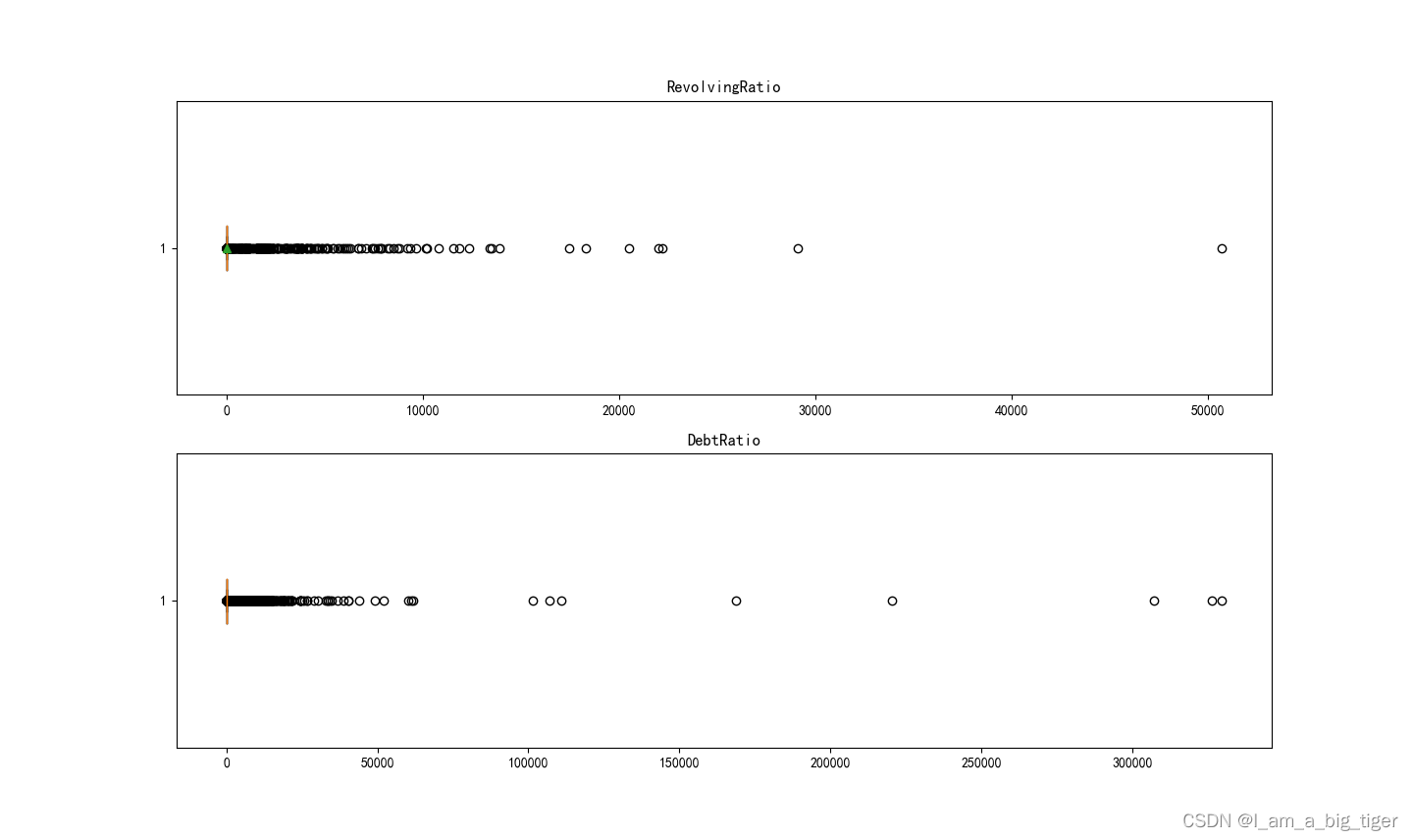
本文使用kaggle数据构建逻辑回归模型,使用AUC、KS、PSI指标对模型效果进行评估。主要过程如下: 1.数据处理:缺失值、异常值分析、缺失值填充。 2.构造新特征。3.相关性分析。4.分箱。5.WOE编码,IV值计算。6.特征选择。7.入模训练,预测。8.模型评估,AUC、KS、PSI指标计算。 (一)数据处理 1.数据导入及缺失值统计 '导入数据' data = pd.read_csv(r"D:\new_job\模型数据\KAGGLE\cs-training.csv") print(data.columns) data = data.iloc[:,1:] data.columns=['Label','RevolvingRatio','Age','30-59D','DebtRatio','MonthIncome','OpenL', '90D','RealEstate','60-89D','Dependents'] #修改列名 print(data.head()) '统计数据集缺失的情况' missingDf = data.isnull().sum().sort_values(ascending=False).reset_index() missingDf.columns = ['features','missing'] missingDf['missing_per'] = missingDf['missing']/data.shape[0] print(missingDf)Index(['ID', 'SeriousDlqin2yrs', 'RevolvingUtilizationOfUnsecuredLines', 'age', 'NumberOfTime30-59DaysPastDueNotWorse', 'DebtRatio', 'MonthlyIncome', 'NumberOfOpenCreditLinesAndLoans', 'NumberOfTimes90DaysLate', 'NumberRealEstateLoansOrLines', 'NumberOfTime60-89DaysPastDueNotWorse', 'NumberOfDependents'], dtype='object') Label RevolvingRatio Age 30-59D ... 90D RealEstate 60-89D Dependents 0 1 0.766127 45 2 ... 0 6 0 2.0 1 0 0.957151 40 0 ... 0 0 0 1.0 2 0 0.658180 38 1 ... 1 0 0 0.0 3 0 0.233810 30 0 ... 0 0 0 0.0 4 0 0.907239 49 1 ... 0 1 0 0.0 [5 rows x 11 columns] features missing missing_per 0 MonthIncome 29731 0.198207 1 Dependents 3924 0.026160 2 Label 0 0.000000 3 RevolvingRatio 0 0.000000 4 Age 0 0.000000 5 30-59D 0 0.000000 6 DebtRatio 0 0.000000 7 OpenL 0 0.000000 8 90D 0 0.000000 9 RealEstate 0 0.000000 10 60-89D 0 0.000000 2.缺失值填充。缺失值有 MonthIncome和Dependents,MonthIncome使用随机森林方法填充,Dependents使用众数进行填充。 count 1.202690e+05 mean 6.670221e+03 std 1.438467e+04 min 0.000000e+00 25% 3.400000e+03 50% 5.400000e+03 75% 8.249000e+03 max 3.008750e+06 Name: MonthIncome, dtype: float64 count 1.500000e+05 mean 6.025803e+03 std 1.300245e+04 min 0.000000e+00 25% 2.554000e+03 50% 4.973000e+03 75% 8.076000e+03 max 3.008750e+06 Name: MonthIncome, dtype: float64 ''' dependents缺失值的处理 ---用众数填充 ''' print(data['Dependents'].describe()) data['Dependents'].fillna(data['Dependents'].mode()[0],inplace=True) print(data['Dependents'].describe())count 146076.000000 mean 0.757222 std 1.115086 min 0.000000 25% 0.000000 50% 0.000000 75% 1.000000 max 20.000000 Name: Dependents, dtype: float64 count 150000.000000 mean 0.737413 std 1.107021 min 0.000000 25% 0.000000 50% 0.000000 75% 1.000000 max 20.000000 Name: Dependents, dtype: float64 3.异常值处理,观察RevolvingRatio,DebtRatio等百分比特征的数据分布情况。 import seaborn as sns import matplotlib.pyplot as plt from pylab import mpl mpl.rcParams['font.sans-serif'] = ['SimHei'] fig = plt.figure(figsize=(20,15)) ax1= fig.add_subplot(2,1,1) lst1 = list(data['RevolvingRatio']) ax1.boxplot(lst1,vert=False,showmeans=True) ax1.set_title('RevolvingRatio') # ax1.set_xticklabels('RevolvingRatio',fontsize=10) ax2 = fig.add_subplot(2,1,2) ax2.boxplot(data['DebtRatio'],vert = False) ax2.set_title('DebtRatio') plt.show() 4.处理RevolvingRatio,DebtRatio百分比异常的数值,使用删除大于1的数值计算均值,替代大于1的百分比。 '''处理百分比异常值''' ruulDf = data[data['RevolvingRatio']1的部分 ruulDf_mean = ruulDf['RevolvingRatio'].mean() #计算均值 data.loc[data['RevolvingRatio']>1,'RevolvingRatio']=ruulDf_mean ##均值代替 ruulDf = data[data['DebtRatio']1,'DebtRatio'] = ruulDf_mean5.逾期数据特征分析:30-59,60-89,90以上。 ''' fig = plt.figure(figsize=(20,15)) ax1 = fig.add_subplot(3,1,1) lst1 = list(data['30-59D']) ax1.boxplot(lst1,vert =False) ax1.set_title('30-59D') ax2 = fig.add_subplot(3,1,2) lst2 = list(data['60-89D']) ax2.boxplot(lst2,vert = False) ax2.set_title('60-89D') ax3 = fig.add_subplot(3,1,3) lst3 = list(data['90D']) ax3.boxplot(lst3,vert=False) ax3.set_title('90D') plt.show()
7.使用箱线图分析'Age','MonthIncome','OpenL','RealEstate','Dependents'变量分布特征。 ''' fig = plt.figure(figsize=(20,15)) ax1 = fig.add_subplot(5,1,1) lst1 = list(data['Age']) ax1.boxplot(lst1,vert=False) plt.title('Age') ax1 = fig.add_subplot(5,1,2) lst1 = data['MonthIncome'] ax1.boxplot(lst1,vert=False) ax1.set_title('MonthIncome') ax2 = fig.add_subplot(5,1,3) lst2 = data['OpenL'] ax2.boxplot(lst2,vert=False) ax2.set_title('OpenL') ax3 = fig.add_subplot(5,1,4) lst3 = data['RealEstate'] ax3.boxplot(lst3,vert=False) ax3.set_title('RealEstate') ax4 = fig.add_subplot(5,1,5) lst4 = data['Dependents'] ax4.boxplot(lst4,vert=False) ax4.set_title('Dependents') plt.show()
9.构造新的特征,IncAvg:家庭中每个人平均分摊的月收入 ---MonthDept:每月应还债务 ---DeptAvg:每月每个家庭成员应还债务。 data['IncAvg'] = data['MonthIncome']/(data['Dependents']+1) data['MonthDept'] = data['MonthIncome']*data['DebtRatio'] data['DeptAvg'] = data['MonthDept']/(data['Dependents']+1)10.相关性分析,删除相关性大于0.6的特征,'IncAvg'和'DeptAvg' '''计算皮尔逊相关系数''' nu_fea = data.columns[1:] ##选择数值类特征计算相关系数 nu_fea = list(nu_fea) ##特征名列表 pearson_mat = data[nu_fea].corr(method='pearson') #计算皮尔逊相关系数矩阵 plt.figure(figsize=(20,15)) sns.heatmap(pearson_mat,annot=True,cmap='YlGnBu') ##用热度图表示相关系数矩阵 # plt.show()
(二)分箱,woe编码,计算iv值 1.先粗分箱,定义一个分箱函数,并观察分箱情况,woe单调性 ''' 分箱 ---定义一个分箱函数 ''' from scipy.stats import stats ##统计推断包 def optimal_bins(Y,X,n): ''' :param Y: 目标变量 :param X:待分箱特征 :param n:分箱数初始值 :return:统计值,分箱边界值列表,woe,iv ''' r = 0 total_bad =Y.sum() ##总的坏样本 total_good = Y.count()-total_bad ##总的好样本 ##分箱过程 while np.abs(r) |
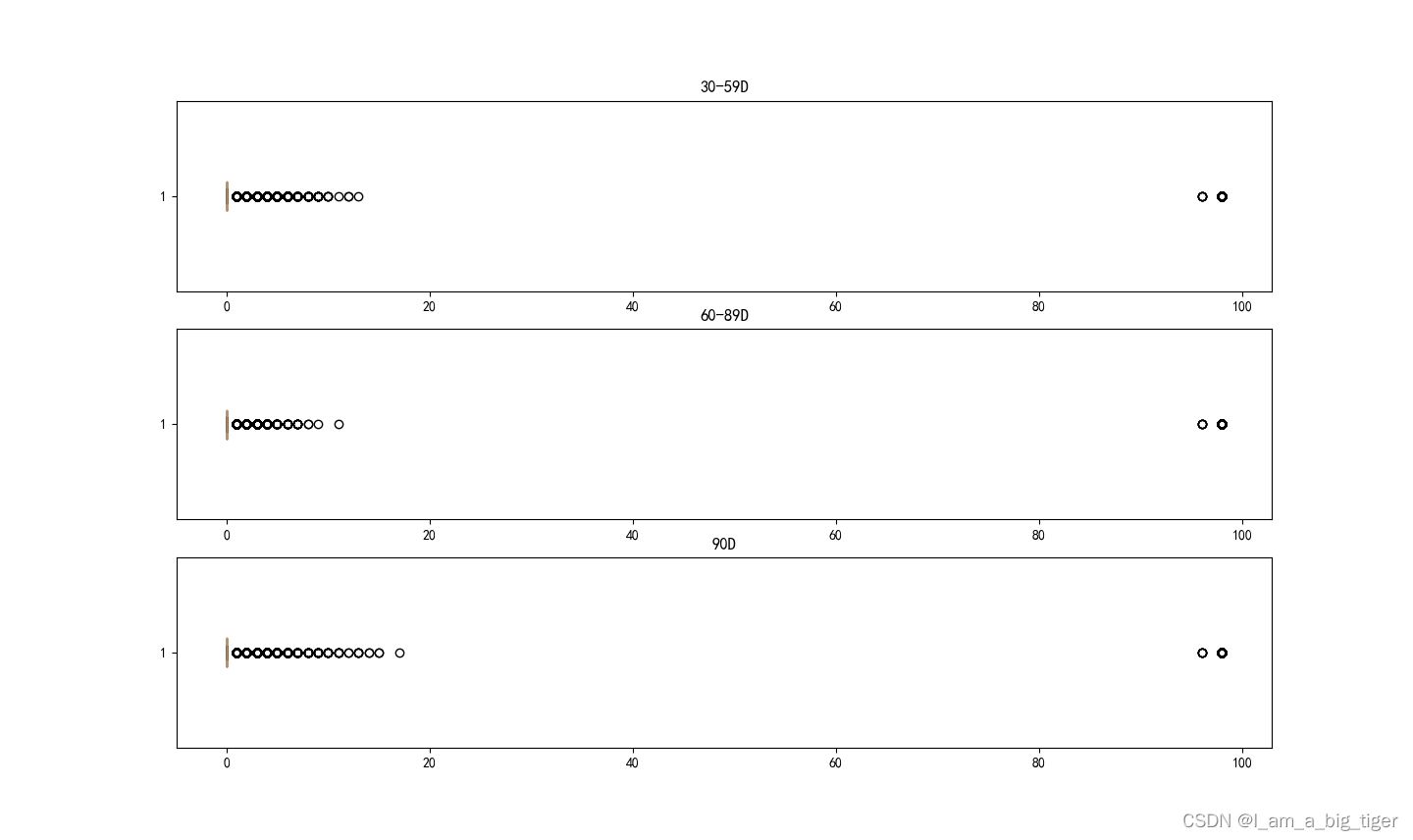 6.查看逾期异常值发现来自相同的样本,删除。
6.查看逾期异常值发现来自相同的样本,删除。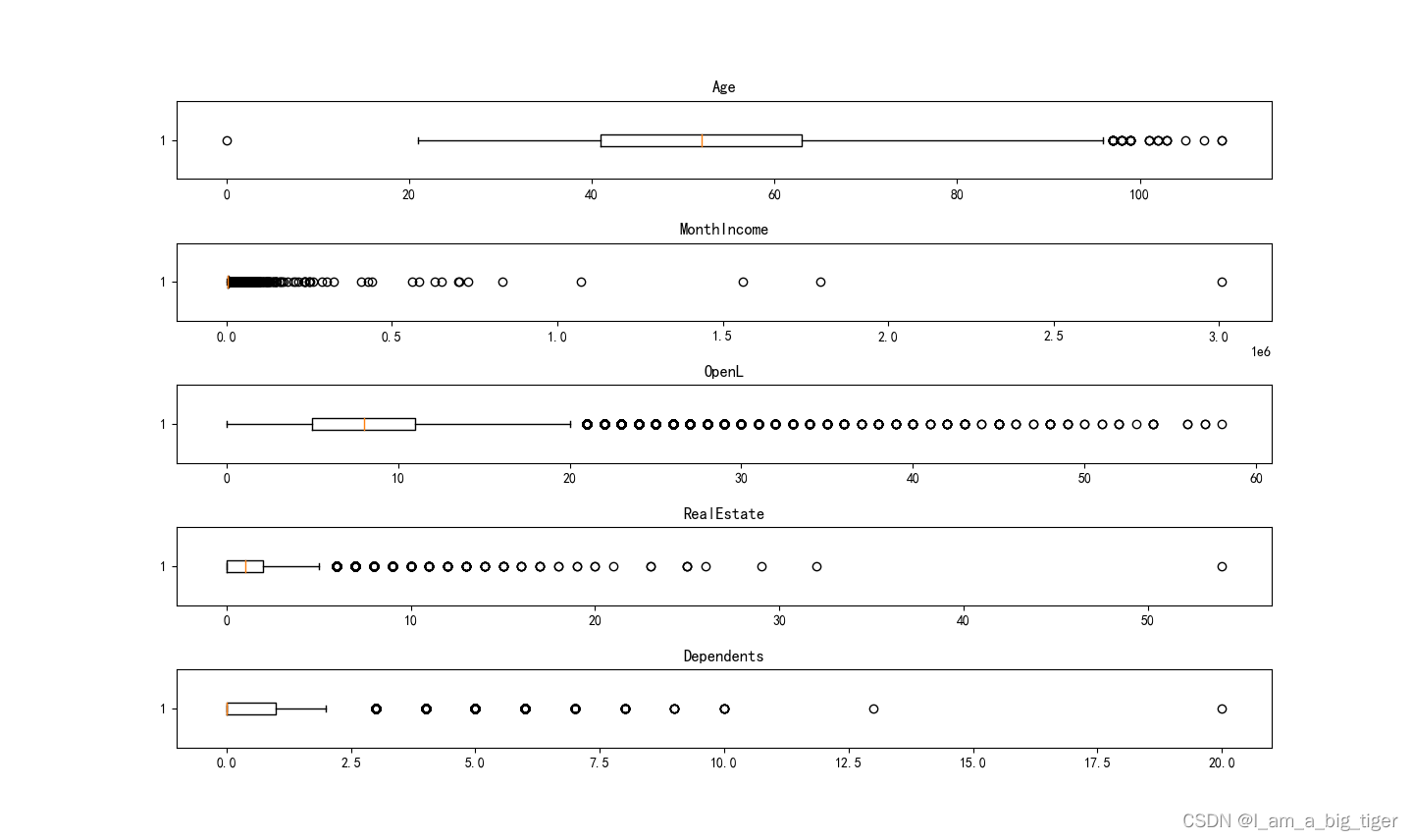 8.根据箱线图,删除异常值。Age大于96小于8的数值,MonthIncome删除大于3.0的数据,realestate删除大于50的数值,dependents删除大于50的数值。
8.根据箱线图,删除异常值。Age大于96小于8的数值,MonthIncome删除大于3.0的数据,realestate删除大于50的数值,dependents删除大于50的数值。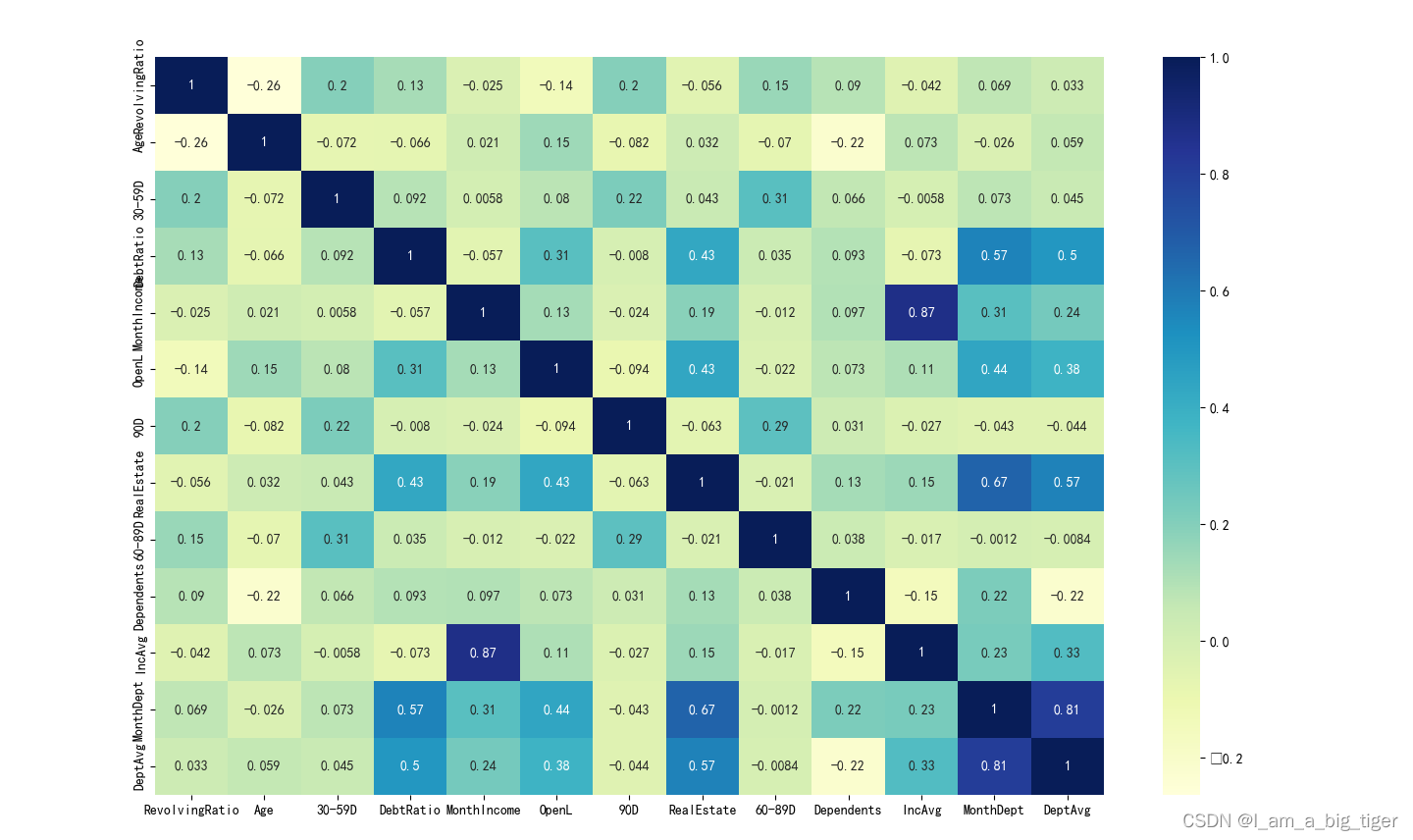
【本文地址】