| 【C语言】链表太难学不懂?看这一篇就够了 | 您所在的位置:网站首页 › 高档suv车型排名前十 › 【C语言】链表太难学不懂?看这一篇就够了 |
【C语言】链表太难学不懂?看这一篇就够了
|
文章目录
前言😀1.什么是链表1.1链表的分类1 单向/双向链表2 带头/不带头3 循环或者非循环
2.开始敲代码!2.1 链表结构2.2 开辟节点2.3 尾插/头插2.4 尾删/头删2.5 查找/更改2.6 在pos位置前/后插入2.7 在pos位置删除数据2.8 打印链表2.9 销毁链表
3.测试结语🤳
前言😀
之前的博客中我们讲述了顺序表的数据结构,顺序表和之前C语言学习的数组还是比较相似的。 今天要学习的是链表,这是一个全新的数据结构,和之前我们学的内容都不相同。 编译器:VS2019 1.什么是链表链表,如其名所示,是一个带链子的表 和顺序表的扩容开辟相比,它可以利用内存堆区中的空闲空间,而不需要一个连续的长空间。从而达到提高空间利用效率的目的。
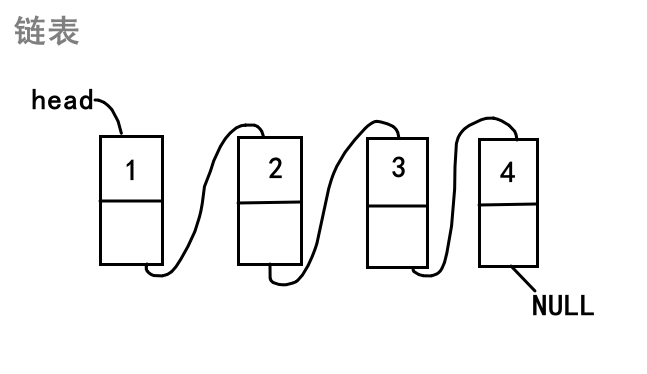
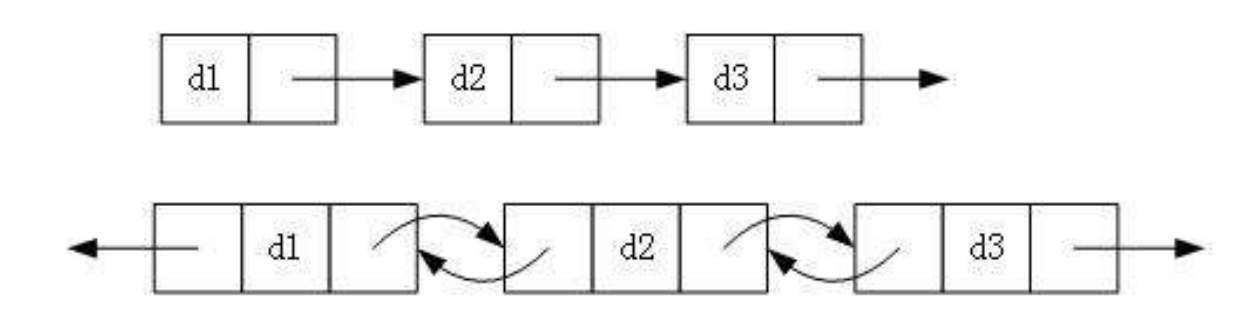
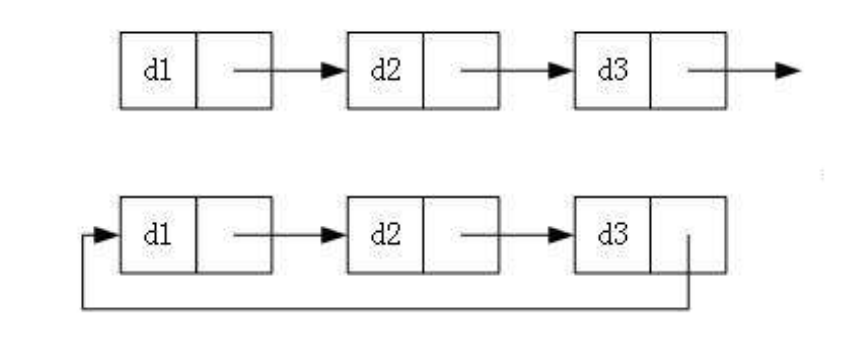
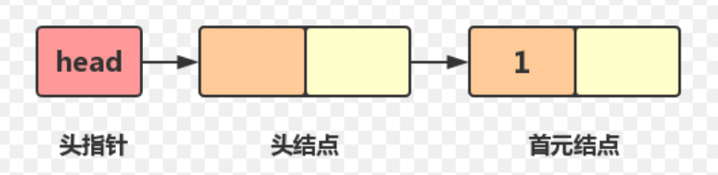
这样我们在使用的时候,就可以用过next指针访问链表的下一个节点,一直到最后一个节点的next为空停止。 需要注意的是,链表的每个节点之间并没有实际意义上的箭头,画出箭头只是方便我们理解。实际上,在内存中,链表的next指针就充当了箭头的角色。 链表的结构在逻辑上连续,但在物理上不一定连续 实际上在堆区开辟空间中,分配的内存可能连续,可能不连续 1.1链表的分类 1 单向/双向链表
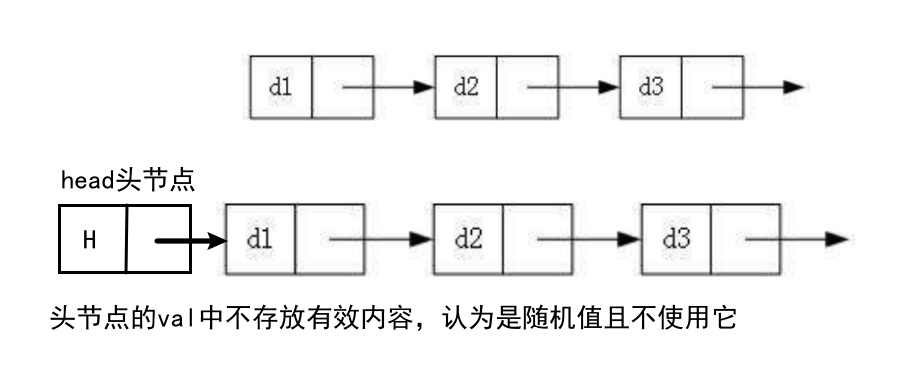
这里的头,指的是一个头节点。该节点的next指向链表实际的表头,val中不存放有效数据 实际使用时,带头的head->next相当于不带头的phead指针
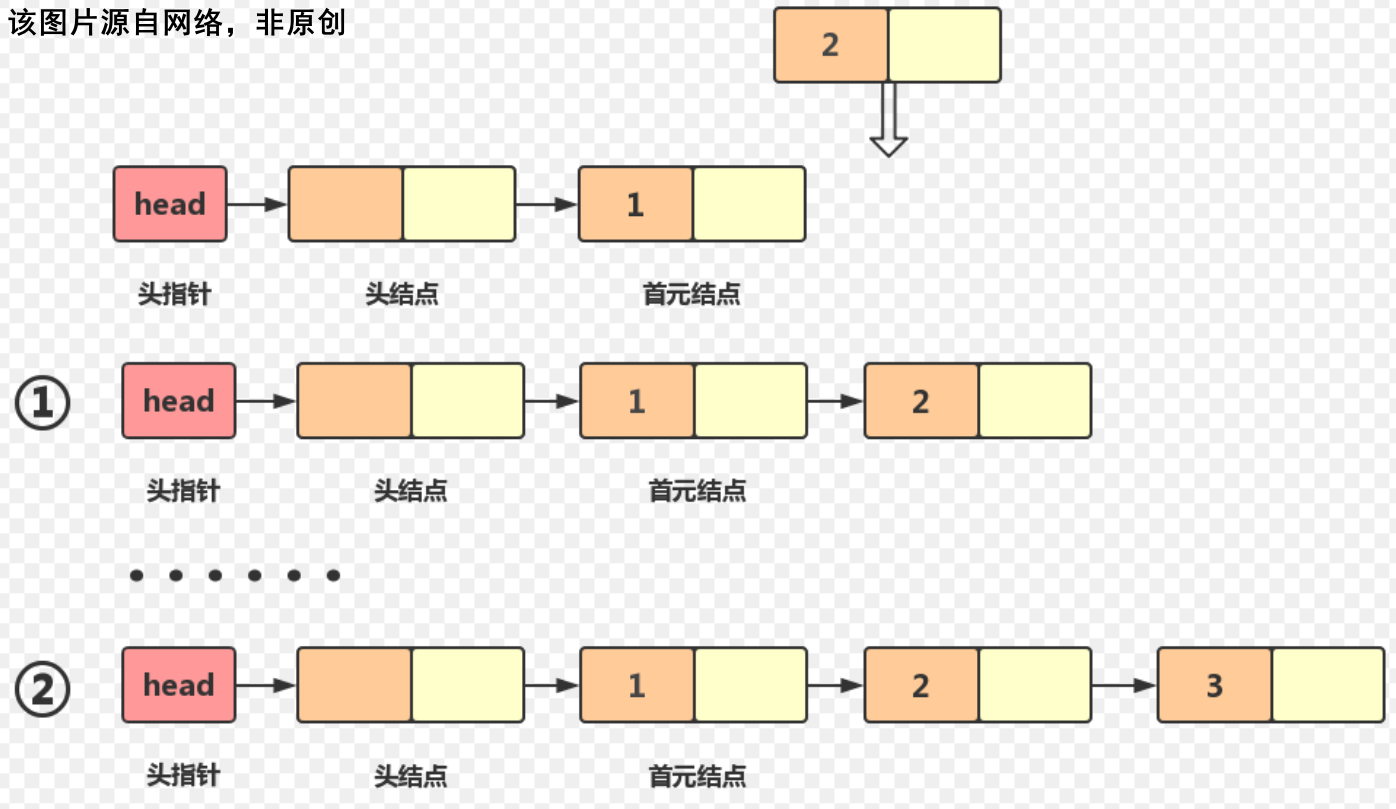
本篇博客讲解的是无头单向非循环链表,双向链表将在之后的博客里面讲解! 2.开始敲代码!实际编写代码的时候,一定要记住:写完一个模块就要测试一次,不要全写完再测试!!! 2.1 链表结构和顺序表一样,使用单链表之前,我们需要创建一个“模板”,即单链表每个节点的结构体 typedef int SLTDataType;//定义新符号,与该符号相关的都是链表内容 typedef struct SListNode { SLTDataType data; //val-存放内容 struct SListNode* next; //存储下一个节点的地址 }SListNode, SLN; 2.2 开辟节点当我们使用单链表时,需要先开辟一个头节点,并使它的next指针指向NULL SListNode* node1 = (SListNode*)malloc(sizeof(SListNode)); node1->data = 1; node1->next = NULL;这部分我们可以封装一个函数来实现! SListNode* BuySListNode(SLTDataType x)//x代表该节点val的值 { SListNode* newnode = (SListNode*)malloc(sizeof(SListNode)); if (newnode == NULL) { printf("malloc fail\n"); exit(-1); } else { newnode->data = x; newnode->next = NULL; } return newnode; }需要注意的是,使用这个函数的时候,我们应该先让另外一个指针来接收返回的newnode地址,不建议直接让上一个节点的next来接收返回值 这样做能方便我们后续debug! //建议做法 SListNode* newnode = BuySListNode(x); tail->next = newnode; //不建议 tail->next=BuySListNode(x); 2.3 尾插/头插尾插:将一个新节点连接到已有链表的尾部 假设我们现在已经有了一个这样的链表,当我们需要尾插的时候,要怎么做呢?
实际上,我们只需要开辟一个新的节点,并将上一个节点的next指向这个新开辟节点的地址即可!(尾插的新节点的next=NULL)
而头插就没有尾插那么麻烦了! 我们只需要将新节点的next指向原链表的头部,再将head头指针更改为新节点的地址即可 void SListPushFront(SListNode** pphead, SLTDataType x) { assert(pphead); SListNode* newnode = BuySListNode(x); newnode->next = *pphead; *pphead = newnode; }细心的你应该注意到了,这里我们使用的都是二级指针pphead 因为假设我们使用一级指针,直接传入头指针phead时,当我们需要更改该指针指向的地址时,改动只会在函数内部生效,main函数中的phead指针并没有被改变 这是一个经典的函数传址和传值问题 当我们需要更改phead本身时,需要传入二级指针 2.4 尾删/头删尾删时,需要先进行找尾。并且需要保存尾部的前一个节点的地址 while(tail->next!=NULL)//会找到尾节点本身,不符合要求 //尾删应该找到尾节点的前一个 while (tail->next->next != NULL)同时,我们需要想到特殊情况 链表为空,无需尾删链表只有一个,无需找尾具体的代码实现如下 void SListPopBack(SListNode** pphead) { assert(pphead); if (*pphead==NULL) { return; } else if((*pphead)->next==NULL) { free(*pphead); *pphead = NULL; } else { //有多个尾巴的情况 SListNode* tail = *pphead;//找尾巴 while (tail->next->next != NULL) { tail = tail->next; } free(tail->next); tail->next = NULL; } return; }头删的情况依旧简单一些 我们需要用一个变量保存头节点,再让头指针phead指向原本头节点的next,最后free掉头节点即可 void SListPopFront(SListNode** pphead) { assert(pphead); if (*pphead == NULL) { return; } else { SListNode* oldhead = *pphead; *pphead = (*pphead)->next; free(oldhead); oldhead = NULL; } return; } 2.5 查找/更改查找函数需要我们在单链表中进行遍历,找到用户输入的x值,并返回它所在节点的地址 查找函数并不需要更改phead指针,所以这里我们只需要传入一级指针 SListNode* SListFind(SListNode* phead, SLTDataType x) { assert(phead); SListNode* curt = phead;//找x的位置 while (curt->next != NULL) { if (curt->data == x) { return curt; } else { curt = curt->next; } } //找不到,返回空 return NULL; }你可能会有一个疑惑,假设我的链表里面有多个x呢?这个函数只能返回找到的第一个x的地址 很遗憾,我们并没有什么好的办法来解决这个问题。除非用户知道他想找的x的准确地址,不然是很难搞定的。 实际应用中,链表的一个节点存放的并不只有一个整型x。我们可以通过其他参数进行多重判断。 比如通讯录中,我们可以用名字+性别来精确查找。也可将所有找到的x都返回给用户进行选择,但那就不是本篇博客会涉及到的内容啦 更改函数中,我们需要用户输入待更改节点的地址,和新的val 如果用户不知道需要更改节点的地址,可以用查找函数来查找。 void SListmodify(SListNode* phead, SListNode* pos, SLTDataType x) { assert(phead); pos->data = x; return; } 2.6 在pos位置前/后插入除了基本的头尾增加,用户可能还需要在某一个特定节点前后进行插入,方便管理数据。这时候我们就需要灵活转变了 链表不存在顺序表中的数据越界pos位置可由find函数找到假设用户需要在pos位置之后插入,我们需要暂时断开链表,新插入一个节点后,重新链接 void SListInsertAfter(SListNode** pphead, SListNode* pos, SLTDataType x) { assert(pphead); assert(pos); SListNode* newnode = BuySListNode(x); SListNode* next = pos->next;//原本pos的下一位 pos->next = newnode;//新插入的pos下一位 newnode->next = next; return; }如果是在pos之前插入,需要遍历查找pos的前一位,使用相同方法断开、插入、重连 void SListInsert(SListNode** pphead, SListNode* pos, SLTDataType x) { assert(pphead); assert(pos); if (pos == *pphead) { SListPushFront(pphead, x); } else { SListNode* tail = *pphead;//找pos前一个 while (tail->next != NULL) {//只写了这个情况,没有考虑pos是第一个的情况 if (tail->next == pos) { SListNode* newnode = BuySListNode(x); tail->next = newnode; tail->next->next = pos; return; } else { tail = tail->next; } } } return; }这里我们都传入了二级指针,因为当pos就是链表的头节点时,在pos前插入就相当于头插,可以直接调用之前写好的头插函数。 当pos就是链表的头节点时,在其后插入相当于尾插。 该函数不存在链表为空的情况,因为函数需要传入pos。空链表中没有节点,pos为空,assert断言会报错。 这里我编写的功能很简单,所以需要用户严格遵守使用规定,传入一个合法的pos 2.7 在pos位置删除数据说完了插入,再来说说删除 这里提供两个函数,一个是在删除pos位置的节点,另一个是删除pos下一位的节点 这一部分其实就是对上一步的逆向,具体的就不详细说啦(偷懒) 大家如果有不懂的,可以在评论区提问~~看到了就会回复的! void SListErase(SListNode** pphead, SListNode** pos) { assert(pphead); assert(pos); if (*pos == *pphead) {//如果pos是头节点,等同于头删 SListPopFront(pphead); } else { SListNode* tail = *pphead;//找pos前一个 while (tail->next != NULL) { if (tail->next == *pos) { tail->next = (*pos)->next; free(*pos);//删除后main函数传过来的pos位置已被free *pos = NULL;//*pos置空,此时main函数中的pos也被置空 pos = NULL; return; } else { tail = tail->next; } } } return; } void SListEraseAfter(SListNode** pphead, SListNode* pos) { assert(pphead); assert(pos); SListNode* next = pos->next->next; free(pos->next); pos->next = next; return; } 2.8 打印链表打印的时候可以打印出->箭头,方便我们查看链表的结构 void SListPrint(SListNode* phead) { SListNode* cur = phead; while (cur != NULL) { printf("%d->", cur->data); cur = cur->next; } printf("NULL\n"); } 2.9 销毁链表对于顺序表来说,销毁链表只需要free掉顺序表中指向堆区空间的指针 但对于链表来说,我们需要一步一步进行释放操作,并在释放完毕后将头指针置空 如果该链表有头节点,则还需将头节点一并置空 void SListDestroy(SListNode** pphead) { assert(pphead); SListNode* curt = *pphead; while (curt) { SListNode* next = curt->next; free(curt); curt = next; } *pphead = NULL; return ; } 3.测试这一次,我依旧使用了多文件编程的方法来敲单链表的代码 这样的好处在于,别人只需要看你的.h头文件,就能清楚的知道你这个项目大概实现了什么样的功能,就好比一篇文章的大纲一样。对于后续的项目实战来说,是非常重要的编程能力积累
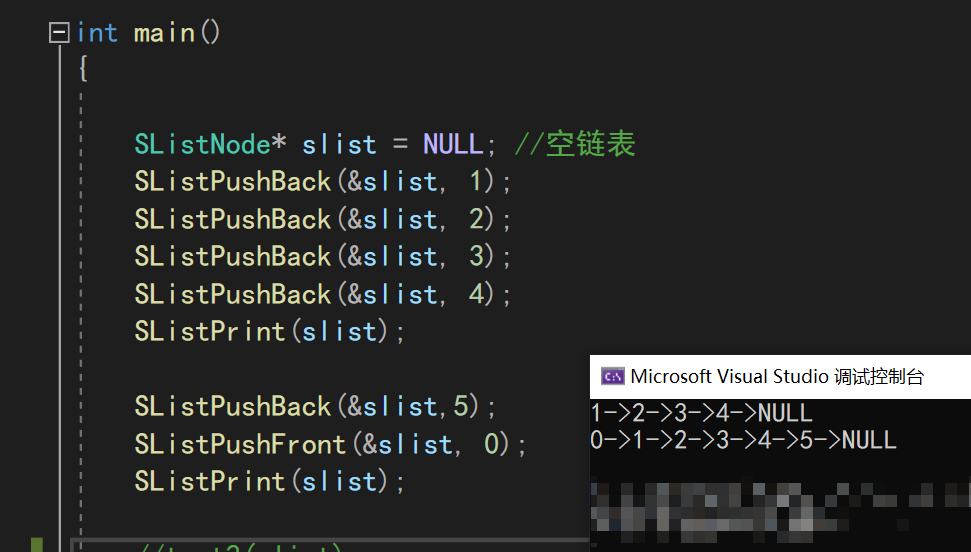
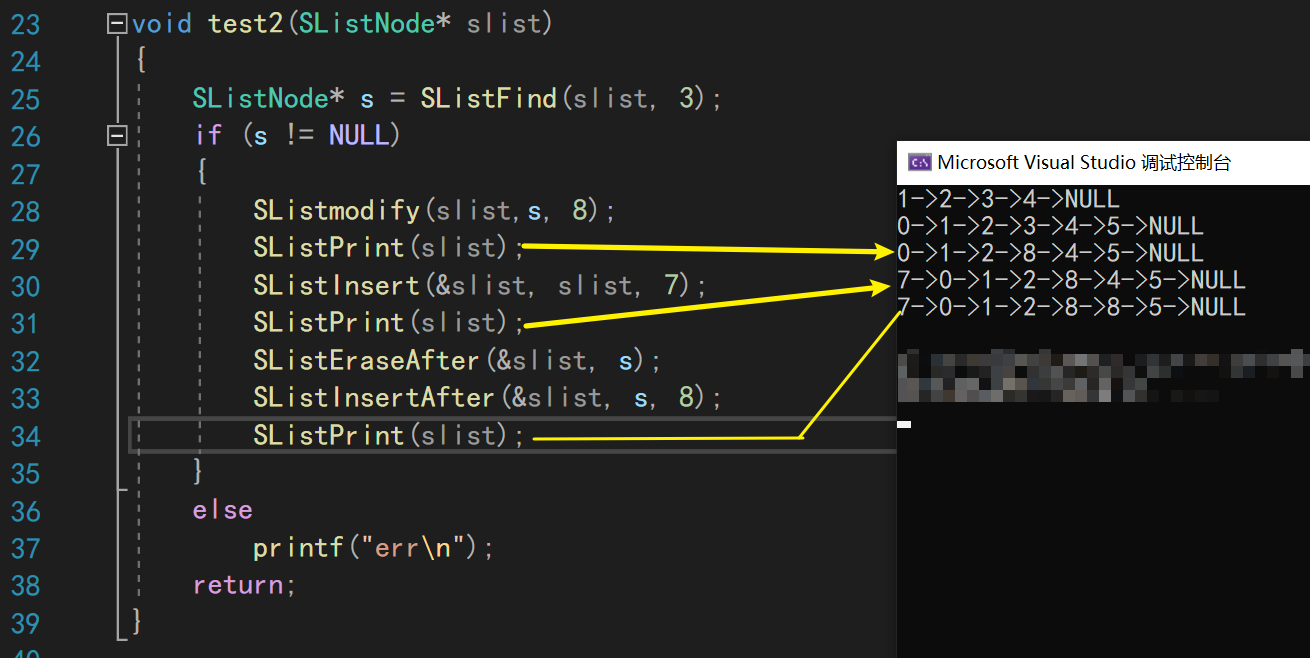
测试一下我们的代码,可以看到,所有函数的功能都能正常实现!
学习完单链表后,我开始接触了一些链表的oj题目,不得不说,链表这部分的题目,难度还是比之前C语言的时候练习的题目更大的!有很多题目都需要我们融会贯通之前的知识。 最重要的是通读代码和调试的能力,这样才能更好地编写出算法 如果这篇博客对你有帮助,还请点个👍,万分感谢! 有什么问题的话,大家可以在评论区提出哦 |
【本文地址】