| 用Python爬取网易云音乐全部歌手信息(歌手id和歌手名字) | 您所在的位置:网站首页 › 骁龙865是三星还是台积电 › 用Python爬取网易云音乐全部歌手信息(歌手id和歌手名字) |
用Python爬取网易云音乐全部歌手信息(歌手id和歌手名字)
|
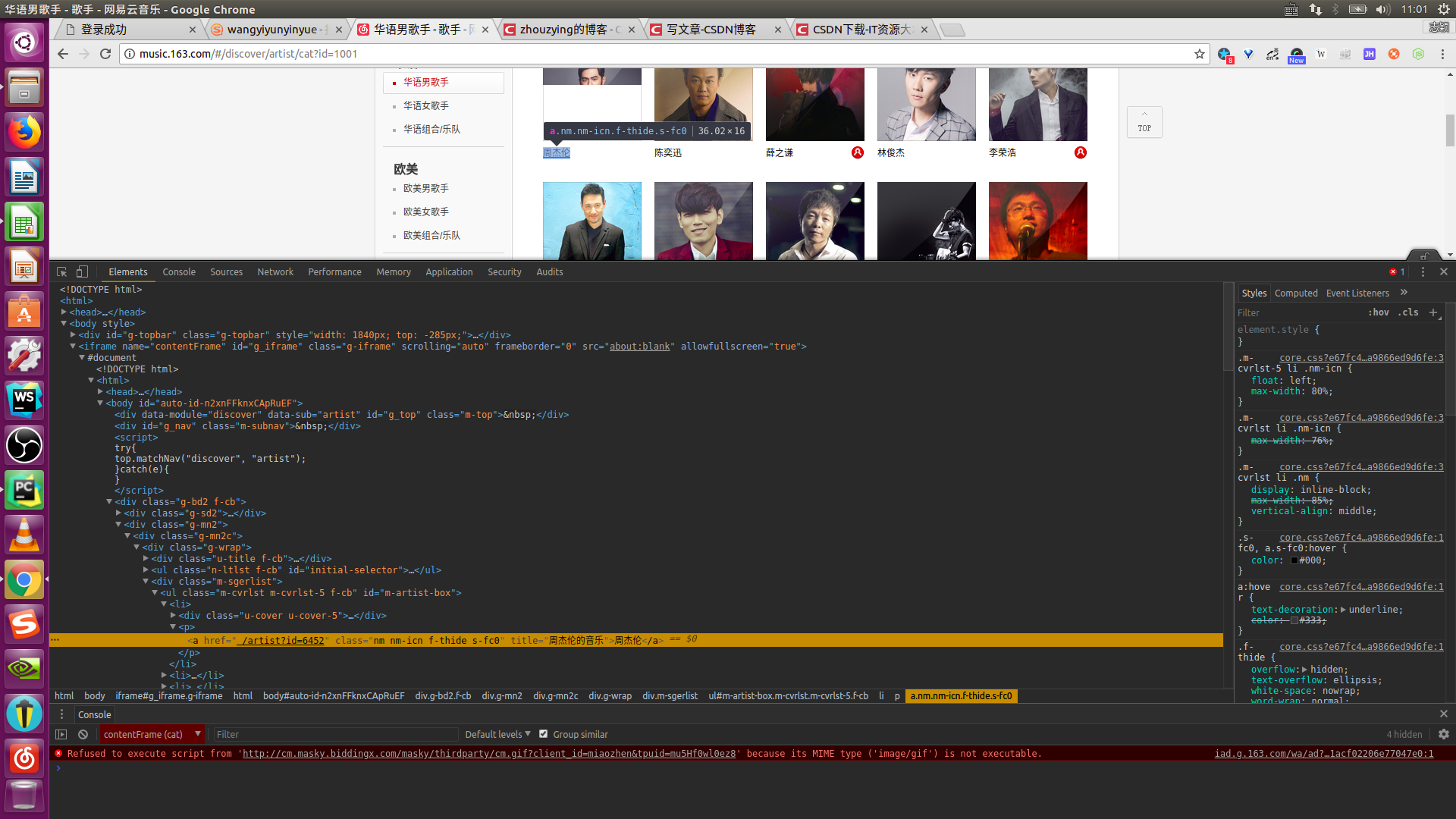
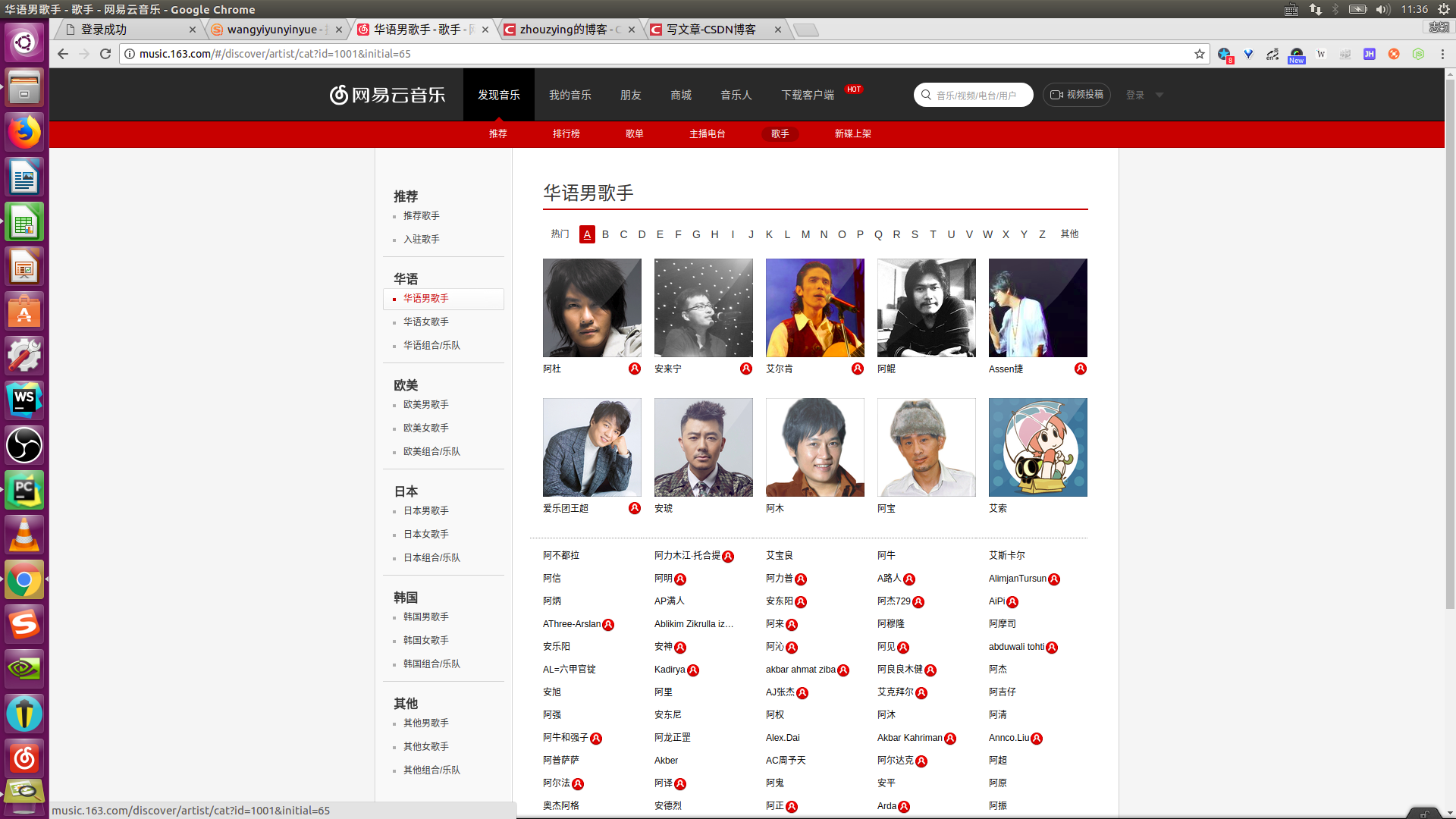
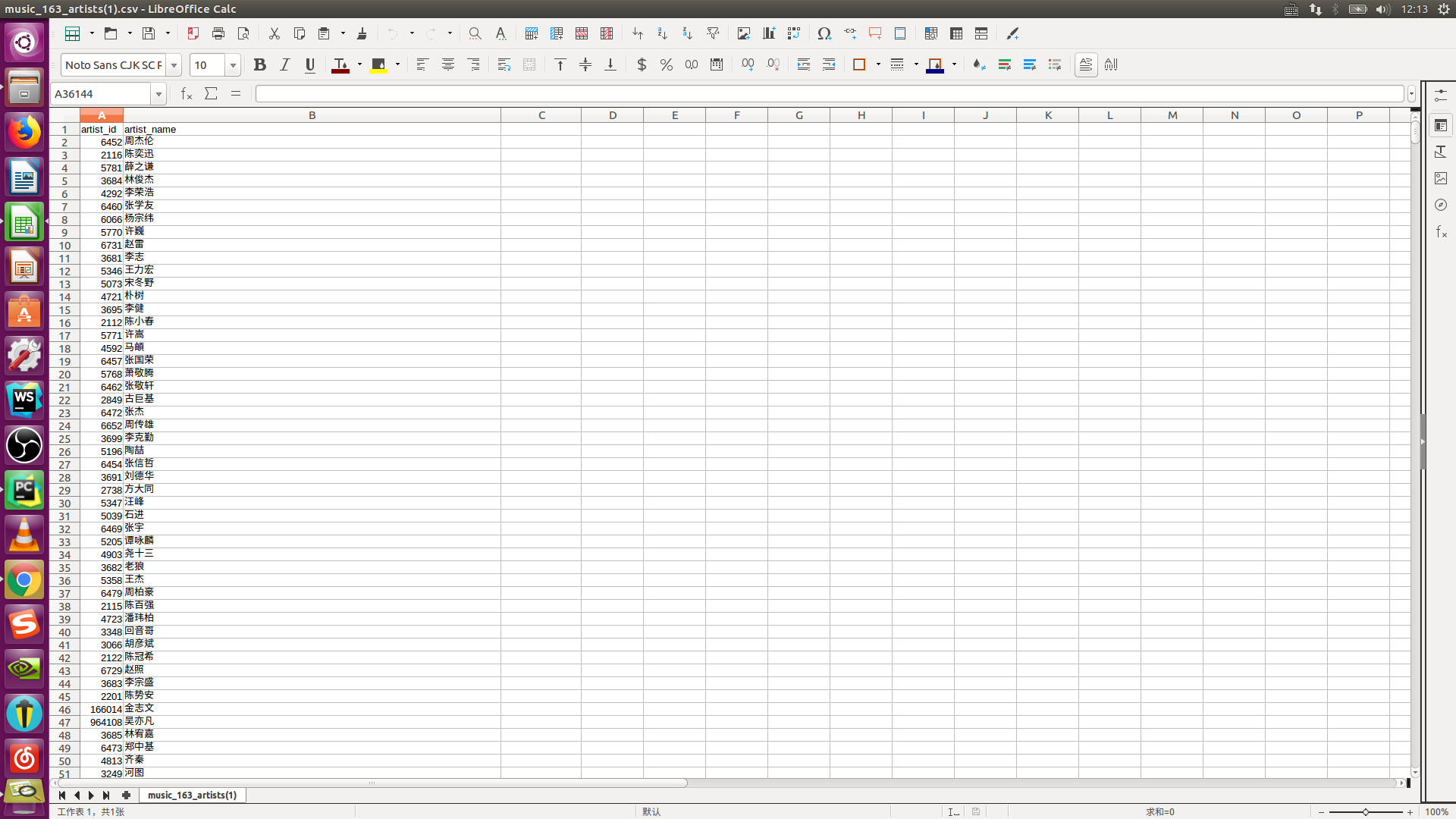
本文介绍用Python爬取网易云音乐全部歌手信息,歌手的id和歌手的名字。 这里我们来看一下歌手周杰伦的id号: 通过浏览器的检查元素,我们可以查看周杰伦的id号为6452。 要想爬取这些数据,就必须在使用requests库时设置好请求的头部(headers)特别是cookie。 接下来开始分析: 首先是找到网易云音乐歌手网页: 在左侧我们可以看到歌手的分类,每个分类都对应一个url的id参数,同一类歌手又通过歌手名字的首字母进行排序,对应url中的initial参数。这里以华语歌手,A打头的网页的url为例。 url='http://music.163.com/#/discover/artist/cat?id=1001&initial=65'因此我们只需要改变网址中的id和initial参数的值便可以将网易云音乐上所有的歌手信息爬取下来。 ls1 = [1001, 1002, 1003, 2001, 2002, 2003, 6001, 6002, 6003, 7001, 7002, 7003, 4001, 4002, 4003] # id的值 ls2 = [-1, 0, 65, 66, 67, 68, 69, 70, 71, 72, 73, 74, 75, 76, 77, 78, 79, 80, 81, 82, 83, 84, 85, 86, 87, 88, 89, 90] # initial的值 for i in ls1: for j in ls2: url = 'http://music.163.com/discover/artist/cat?id=' + str(i) + '&initial=' + str(j)这里我们创建两个列表来存储id和initial的值,从而构建爬取全部歌手信息的网页url。 接着我们开始设置请求的头(即headers的值),打开浏览器的开发者工具栏(鼠标右键点击检查),点击network,再点击Doc,找到原始请求返回的文件(即网址对应的文件),点击headers,里面有Request Headers,把里面的值全部设置为请求的头部的值。 下面具体来看一下请求的头部的设置,一定不能漏了cookie的值。 headers={'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8', 'Accept-Encoding': 'gzip, deflate', 'Accept-Language': 'zh-CN,zh;q=0.9', 'Connection': 'keep-alive', 'Cookie': '_iuqxldmzr_=32; _ntes_nnid=0e6e1606eb78758c48c3fc823c6c57dd,1527314455632; ' '_ntes_nuid=0e6e1606eb78758c48c3fc823c6c57dd; __utmc=94650624; __utmz=94650624.1527314456.1.1.' 'utmcsr=(direct)|utmccn=(direct)|utmcmd=(none); WM_TID=blBrSVohtue8%2B6VgDkxOkJ2G0VyAgyOY;' ' JSESSIONID-WYYY=Du06y%5Csx0ddxxx8n6G6Dwk97Dhy2vuMzYDhQY8D%2BmW3vlbshKsMRxS%2BJYEnvCCh%5CKY' 'x2hJ5xhmAy8W%5CT%2BKqwjWnTDaOzhlQj19AuJwMttOIh5T%5C05uByqO%2FWM%2F1ZS9sqjslE2AC8YD7h7Tt0Shufi' '2d077U9tlBepCx048eEImRkXDkr%3A1527321477141; __utma=94650624.1687343966.1527314456.1527314456' '.1527319890.2; __utmb=94650624.3.10.1527319890', 'Host': 'music.163.com', 'Referer': 'http://music.163.com/', 'Upgrade-Insecure-Requests': '1', 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) ' 'Chrome/66.0.3359.181 Safari/537.36'}最后构造一个获取这些信息的函数即可。 # 构造函数获取歌手信息 def get_artists(url): headers={'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8', 'Accept-Encoding': 'gzip, deflate', 'Accept-Language': 'zh-CN,zh;q=0.9', 'Connection': 'keep-alive', 'Cookie': '_iuqxldmzr_=32; _ntes_nnid=0e6e1606eb78758c48c3fc823c6c57dd,1527314455632; ' '_ntes_nuid=0e6e1606eb78758c48c3fc823c6c57dd; __utmc=94650624; __utmz=94650624.1527314456.1.1.' 'utmcsr=(direct)|utmccn=(direct)|utmcmd=(none); WM_TID=blBrSVohtue8%2B6VgDkxOkJ2G0VyAgyOY;' ' JSESSIONID-WYYY=Du06y%5Csx0ddxxx8n6G6Dwk97Dhy2vuMzYDhQY8D%2BmW3vlbshKsMRxS%2BJYEnvCCh%5CKY' 'x2hJ5xhmAy8W%5CT%2BKqwjWnTDaOzhlQj19AuJwMttOIh5T%5C05uByqO%2FWM%2F1ZS9sqjslE2AC8YD7h7Tt0Shufi' '2d077U9tlBepCx048eEImRkXDkr%3A1527321477141; __utma=94650624.1687343966.1527314456.1527314456' '.1527319890.2; __utmb=94650624.3.10.1527319890', 'Host': 'music.163.com', 'Referer': 'http://music.163.com/', 'Upgrade-Insecure-Requests': '1', 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) ' 'Chrome/66.0.3359.181 Safari/537.36'} r = requests.get(url, headers=headers) csvfile = open('/home/zhiying/文档/music_163_artists(1).csv', 'a') # 文件存储的位置 writer = csv.writer(csvfile) writer.writerow(('artist_id', 'artist_name')) soup = BeautifulSoup(r.text, 'html5lib') for artist in soup.find_all('a', attrs={'class': 'nm nm-icn f-thide s-fc0'}): artist_name = artist.string artist_id = artist['href'].replace('/artist?id=', '').strip() try: writer.writerow((artist_id, artist_name)) except Exception as msg: print(msg)至此利用Python爬取网易云音乐全部歌手信息的爬虫就完成了,这里我把信息存储成了csv 文件。来看一下结果: 大家在爬取的时候有啥问题,欢迎在评论区留言,我会及时为大家解答。 查看完整代码请上我的Github 也可以点击这里下载代码和歌手信息 2018年9月18日更新:最近发现一种新的爬取方法,具体请参考这篇文章! 欢迎大家加爬虫QQ群:565712652讨论! |



【本文地址】
公司简介
联系我们