| Wise | 您所在的位置:网站首页 › 飞机v1v2v3速度 › Wise |
Wise
|
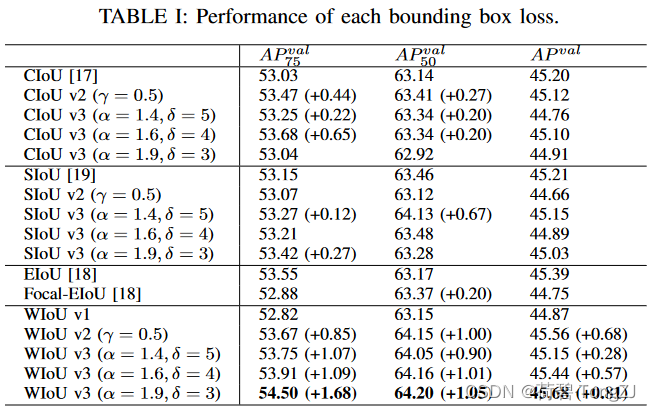
论文地址:Wise-IoU: Bounding Box Regression Loss with Dynamic Focusing Mechanism GitHub:https://github.com/Instinct323/wiou 摘要:目标检测作为计算机视觉的核心问题,其检测性能依赖于损失函数的设计。边界框损失函数作为目标检测损失函数的重要组成部分,其良好的定义将为目标检测模型带来显著的性能提升。近年来的研究大多假设训练数据中的示例有较高的质量,致力于强化边界框损失的拟合能力。但我们注意到目标检测训练集中含有低质量示例,如果一味地强化边界框对低质量示例的回归,显然会危害模型检测性能的提升。Focal-EIoU v1 被提出以解决这个问题,但由于其聚焦机制是静态的,并未充分挖掘非单调聚焦机制的潜能。基于这个观点,我们提出了动态非单调的聚焦机制,设计了 Wise-IoU (WIoU)。动态非单调聚焦机制使用“离群度”替代 IoU 对锚框进行质量评估,并提供了明智的梯度增益分配策略。该策略在降低高质量锚框的竞争力的同时,也减小了低质量示例产生的有害梯度。这使得 WIoU 可以聚焦于普通质量的锚框,并提高检测器的整体性能。将WIoU应用于最先进的单级检测器 YOLOv7 时,在 MS-COCO 数据集上的 AP-75 从 53.03% 提升到 54.50% 前言:因为我能使用的算力有限,所以做实验时只在 YOLOv7 上做了。而且因为完整的 MS-COCO 需要更大的参数量,训练一个模型需要 3 天时间,所以我只取了其中四分之一的数据进行训练 (28474 张训练图片)。这篇论文的硬伤在于实验量是严重不足的,所以我也不确保这个方法的普适性。此外,WIoU 是一个依赖超参数的方法,所以建议大家根据自己的实验数据调整超参数,而不是直接使用我的默认参数
CIoU、SIoU 的 v2 使用和 WIoU v2 一致的单调聚焦机制,v3 使用和 WIoU v3 一致的动态非单调聚焦机制,详见论文的消融实验 在计算速度上,WIoU 所增加的计算成本主要在于聚焦系数的计算、IoU 损失的均值统计。在实验条件相同时,WIoU 因为没有对纵横比进行计算反而有更快的速度,WIoU 的计算耗时为 CIoU 的 87.2% 在性能提升上,数据集的标注质量越差 (当然差到一定程度就不叫数据集了),WIoU 相对其它边界框损失的表现越好。比如说我在一个检测火焰的比赛里用的 WIoU (那时的初版还比较捞) 使 mAP 提升了 1.70% (相比 CIoU) 这篇博客没有像论文那么详细,大家有什么地方看不明白的欢迎在评论区提问,我会抽时间补上的 ~ 现有工作记锚框为
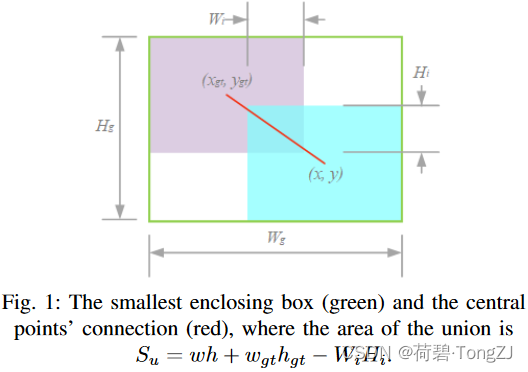
IoU 用于度量目标检测任务中预测框与真实框的重叠程度,定义为: 同时,IoU 有一个致命的缺陷,可以在下面公式中观察到。当边界框之间没有重叠时 现有的工作考虑了许多与包围盒相关的几何因素并构造了惩罚项 DIoU 将惩罚项定义为中心点连接的归一化长度: 同时为最小包围框的尺寸 但不可否认的是,距离度量的确是一个极其有效的解决方案,成为高效边界框损失的必要因子。EIoU 在此基础上加大了对距离度量的惩罚力度,其惩罚项定义为: 在 其中的 其中
Zhora Gevorgyan 证明了中心对齐的边界框会具有更快的收敛速度,以 angle cost、distance cost、shape cost 构造了 SIoU。其中 angle cost 描述了边界框中心连线与 x-y 轴的最小夹角: distance cost 描述了两边界框的中心点在x轴和y轴上的归一化距离,其惩罚力度与 angle cost 正相关。distance cost 被定义为: shape cost 描述了两边界框的形状差异,当两边界框的尺寸不一致时不为 0。shape cost 被定义为:
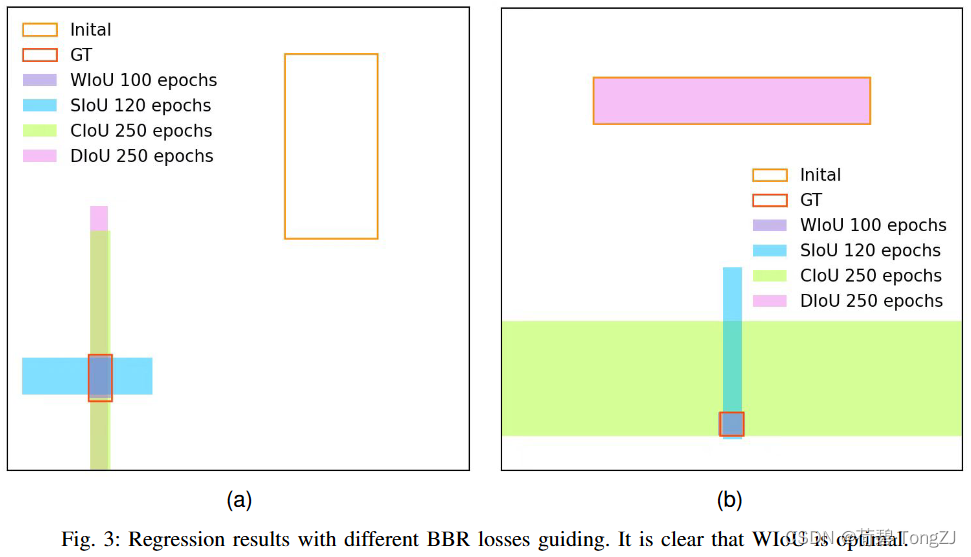
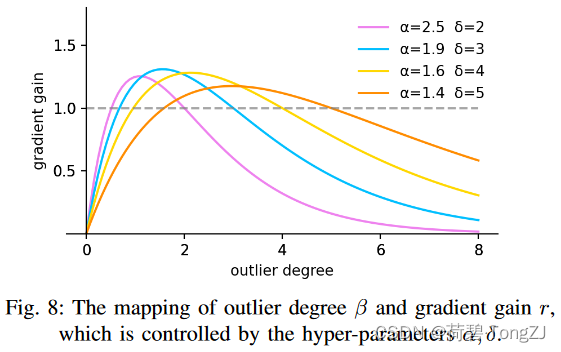
本文所涉及的聚焦机制有以下几种: 静态:当边界框的 IoU 为某一指定值时有最高的梯度增益,如 Focal EIoU v1动态:享有最高梯度增益的边界框的条件处于动态变化中,如 WIoU v3单调:梯度增益随损失值的增加而单调增加,如 Focal loss非单调:梯度增益随损失值的增加呈非单调变化WIoU v1 构造了基于注意力的边界框损失,WIoU v2 和 v3 则是在此基础上通过构造梯度增益 (聚焦系数) 的计算方法来附加聚焦机制 Wise-IoU v1因为训练数据中难以避免地包含低质量示例,所以如距离、纵横比之类的几何度量都会加剧对低质量示例的惩罚从而使模型的泛化性能下降。好的损失函数应该在锚框与目标框较好地重合时削弱几何度量的惩罚,不过多地干预训练将使模型有更好的泛化能力。在此基础上,我们根据距离度量构建了距离注意力,得到了具有两层注意力机制的 WIoU v1: 为了防止 Focal Loss 设计了一种针对交叉熵的单调聚焦机制,有效降低了简单示例对损失值的贡献。这使得模型能够聚焦于困难示例,获得分类性能的提升。类似地,我们构造了 在模型训练过程中,梯度增益 其中的 定义离群度以描述锚框的质量,其定义为: 离群度小意味着锚框质量高,我们为其分配一个小的梯度增益,以便使边界框回归聚焦到普通质量的锚框上。对离群度较大的锚框分配较小的梯度增益,将有效防止低质量示例产生较大的有害梯度。我们利用
其中,当
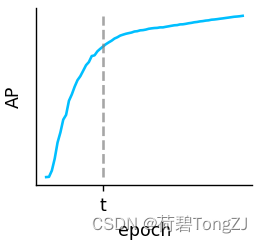
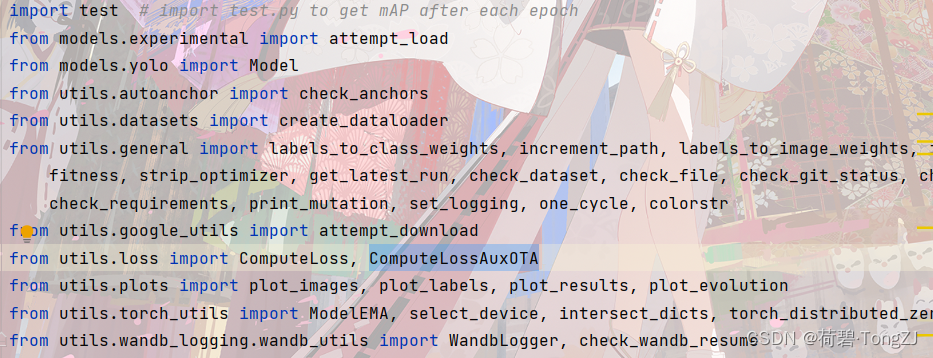
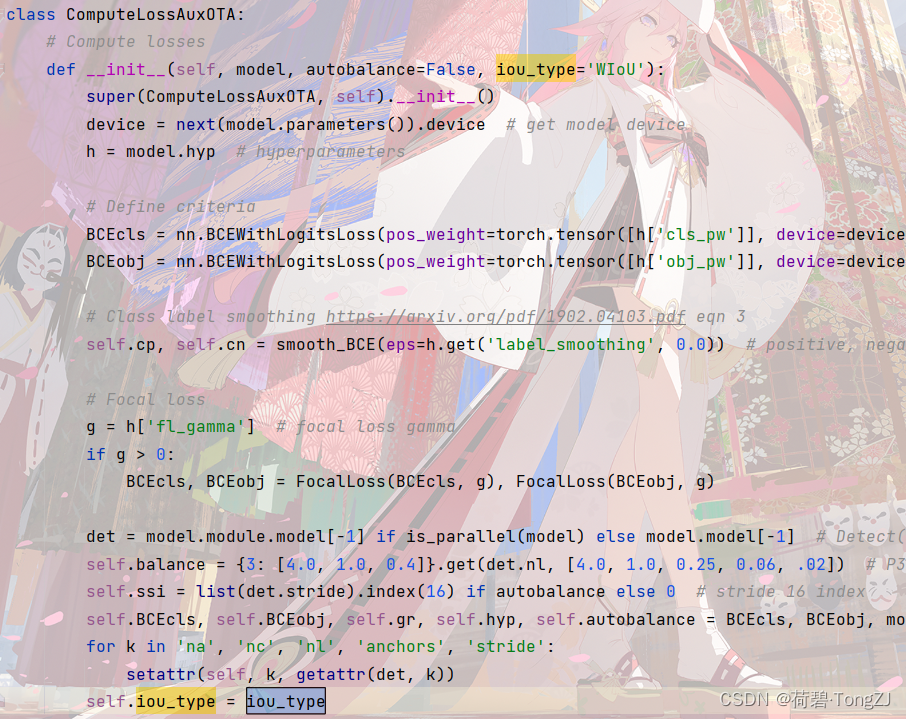
为了防止低质量锚框在训练初期落后,我们初始化 这种设置使得经过 IoU_Cal 类 (在最上面的 Github 链接里) 可以计算现有的边界框损失 (IoU,GIoU,DIoU,CIoU,EIoU,SIoU,WIoU),核心的类变量有: iou_mean:即此外,聚焦机制会对边界框损失的值进行缩放,具体通过实例方法 _scaled_loss 实现 其中,WIoU v3 包含 α, δ 两个超参数,不同的超参数可能适用于不同的模型和数据集,需要自行调整 _scaled_loss 的缺省值以找到最优解 在将 WIoU v3 引进 YOLOv7 时,先在 train_aux.py 中找到损失函数的位置。ComputeLossAuxOTA 是 train 的时候用的,找到其源代码并进行修改 因为 YOLOv7 对模型性能的比较主要利用 utils/metrics 里的 fitness 函数,与损失值无关。而 ComputeLoss 是在 eval 的时候用的,保证不出 bug 就行
在初始化函数动一下手脚,指定使用的损失函数
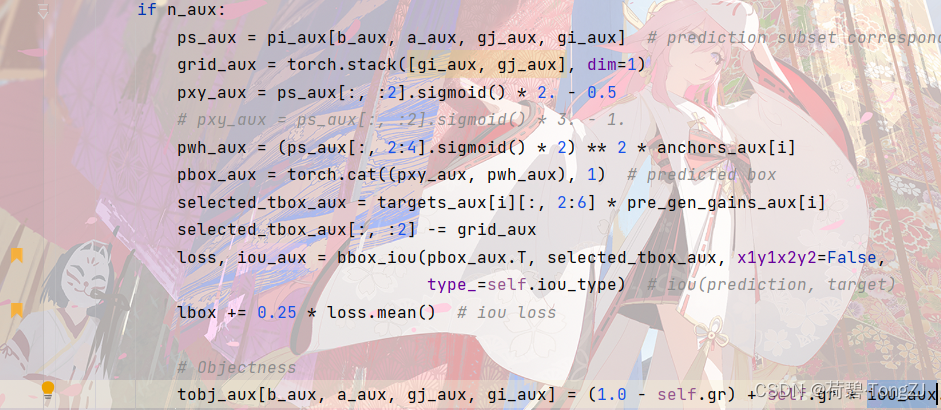
再修改 __call__ 函数 (修改的行已用书签标注出)
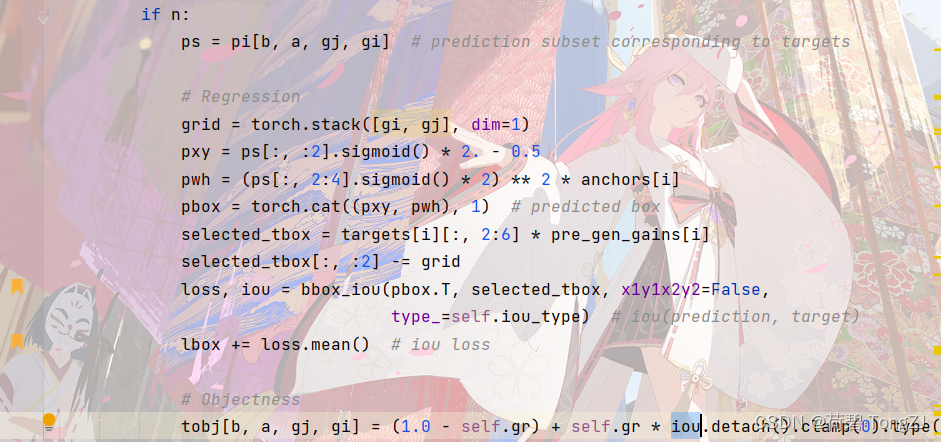
再找到 bbox_iou 函数的所在位置,修改边界框损失的计算方法 这里因为形参、返回值都和原函数不同,所以要检查 ComputeLoss 中调用这个函数的地方,以防报错 def bbox_iou(box1, box2, type_, x1y1x2y2=True): # Returns the IoU of box1 to box2. box1 is 4, box2 is nx4 box2 = box2.T # Get the coordinates of bounding boxes if x1y1x2y2: # x1, y1, x2, y2 = box1 b1_x1, b1_y1, b1_x2, b1_y2 = box1[0], box1[1], box1[2], box1[3] b2_x1, b2_y1, b2_x2, b2_y2 = box2[0], box2[1], box2[2], box2[3] else: # transform from xywh to xyxy b1_x1, b1_x2 = box1[0] - box1[2] / 2, box1[0] + box1[2] / 2 b1_y1, b1_y2 = box1[1] - box1[3] / 2, box1[1] + box1[3] / 2 b2_x1, b2_x2 = box2[0] - box2[2] / 2, box2[0] + box2[2] / 2 b2_y1, b2_y2 = box2[1] - box2[3] / 2, box2[1] + box2[3] / 2 # 将边界框信息拼接 b1 = torch.stack([b1_x1, b1_y1, b1_x2, b1_y2], dim=-1) b2 = torch.stack([b2_x1, b2_y1, b2_x2, b2_y2], dim=-1) self = IoU_Cal(b1, b2) loss = getattr(IoU_Cal, type_)(b1, b2, self=self) iou = 1 - self.iou return loss, iou |
【本文地址】