| 详细分析14种可用于时间序列预测的损失函数 | 您所在的位置:网站首页 › 风速函数 › 详细分析14种可用于时间序列预测的损失函数 |
详细分析14种可用于时间序列预测的损失函数
|
论文 : https://arxiv.org/abs/2211.02989代码 : https://github.com/aryan-jadon/Regression-Loss-Functions-in-Time-Series-Forecasting-Tensorflow作者 :Aryan Jadon, Avinash Patil, Shruti Jadon 一 摘要时间序列预测方法包括使用一组历史时间序列进行预测,在信号处理、模式识别、计量经济学、数学金融、天气预报、地震预测等领域都有广泛应用。过去时间序列预测方法以线性方法为主,然而在许多最新的应用中已经尝试使用机器学习、深度学习、高斯过程和人工神经网络等技术来进行时间序列预测。在处理时间序列预测问任务时,损失函数的选择非常重要,因为它会驱动算法的学习过程。以往的工作提出了不同的损失函数,以解决数据存在偏差、需要长期预测、存在多重共线性特征等问题。本文工作总结了常用的的14个损失函数并对它们的优缺点进行分析,这些损失函数已被证明在不同领域提供了最先进的结果。本文在在各种时间序列基准任务上对它们的表现进行分析,希望能助行业专业人士和研究人员快速的为任务选取合适的损失函数,避免过多的实验尝试。  二 问题背景 二 问题背景回归是一种常见的预测建模技术,用于估计两个或多个变量之间的关系。它是一种监督学习技术,可以定义为用于对相关实数变量之间的关系建模的统计技术和自变量。时间序列数据与一般基于回归的数据略有不同,因为在特征中添加了时间信息,使目标更加复杂。时间序列数据具有以下组成部分 - level: 每个时间序列都有一个base level,简单的base level的计算可以直接通过对历史数据进行平均/中位数计算得到;周期性:时间序列数据也有一种称为周期性的模式,它不定期重复,这意味着它不会以相同的固定间隔出现;趋势:表示时间序列在一段时间内是增加还是减少。也就是说,它有上升(增加)或下降(减少)的趋势;季节性:在一段时间内重复出现的模式称为季节性;噪声:在提取水平、周期性、趋势和季节性之后,剩下的就是噪声,噪声是数据中完全随机的变化。每个机器学习模型的基本目标都是改进模型的选定指标并减少与之相关的损失。用于时间序列预测的机器学习或深度学习模型的一个重要组成部分是损失函数,模型的性能是根据损失函数来衡量的,促使了模型参数的更新。 三 14种损失函数分析1. Mean Absolute Error (MAE)MAE,也称为 L1 损失,是预测值与实际值之间的绝对误差:  所有样本值的绝对误差的均值就称为MAE:  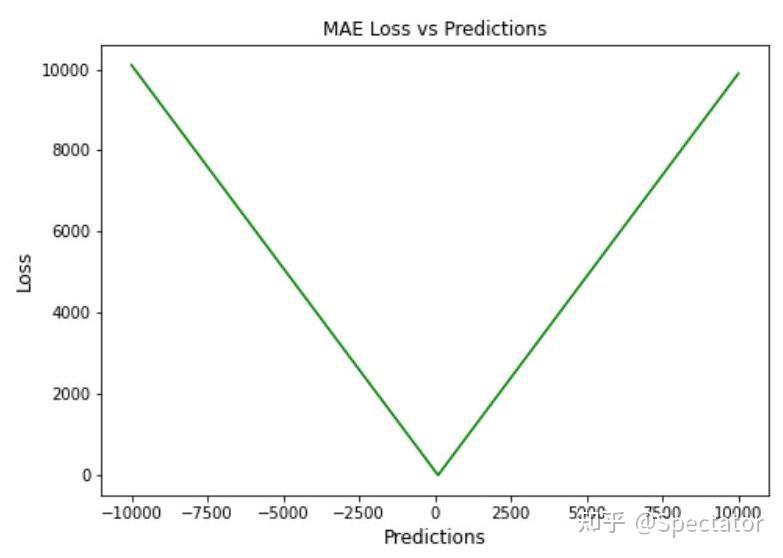 MAE Loss与Predictions的性能图MAE是回归模型中经常使用的一种简单有效的损失函数。但是由于异常值,回归问题中的变量可能不是严格的高斯变量会带来一些问题。 优点缺点MAE计算简单,并提供了模型性能的均匀度量。MAE对异常值不太敏感。MAE遵循线性评分方法,这意味着在计算平均值时,所有误差都被平均加权。由于MAE的陡峭性,我们可能会在反向传播过程中跳过最小值。MAE在零处不可微,因此计算梯度很困难。2 Mean Squared Error (MSE)MSE,也称为 L2 损失,是预测值与实际值之间的平方误差:  所有样本值的平方误差的均值就称为MSE, 也称作均方误差:  MSE 也称为二次损失,因为惩罚是平方而不是与误差成正比。当误差被平方时,离群值被赋予更多的权重,为较小的误差创建一个平滑的梯度。受益于这种对巨大错误的惩罚,有助于优化算法获得参数的最佳值。鉴于错误是平方的,MSE 永远不会是负数,错误的值可以是 0 到无穷大之间的任何值。随着错误的增加,MSE 呈指数增长,好的模型的 MSE 值将接近于0。  优点缺点当梯度逐渐减小时,MSE有助于对微小错误进行有效的最小收敛。MSE值用二次方程表示,有助于在异常值的情况下惩罚模型。对这些值进行平方可加快训练速度,但较高的损失值可能会导致反向传播过程中的大幅跳跃,这是不可取的。MSE对异常值特别敏感,这意味着数据中的显著异常值可能会影响我们的模型性能。3 Mean Bias Error (MBE) 优点缺点当梯度逐渐减小时,MSE有助于对微小错误进行有效的最小收敛。MSE值用二次方程表示,有助于在异常值的情况下惩罚模型。对这些值进行平方可加快训练速度,但较高的损失值可能会导致反向传播过程中的大幅跳跃,这是不可取的。MSE对异常值特别敏感,这意味着数据中的显著异常值可能会影响我们的模型性能。3 Mean Bias Error (MBE)高估或低估参数值的倾向称为偏差或平均偏差误差。偏差的唯一可能方向是正向或负向。正偏差表示数据误差被高估,而负偏差表示误差被低估。实际值和预期值之间的差异被测量为平均偏差误差 (MBE)。预测中的平均偏差由 MBE 量化。除了不考虑绝对值外,它实际上与 MAE 相同。应谨慎对待 MBE,因为正向误差和负向误差可能会相互抵消。 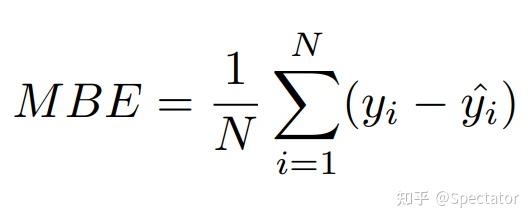 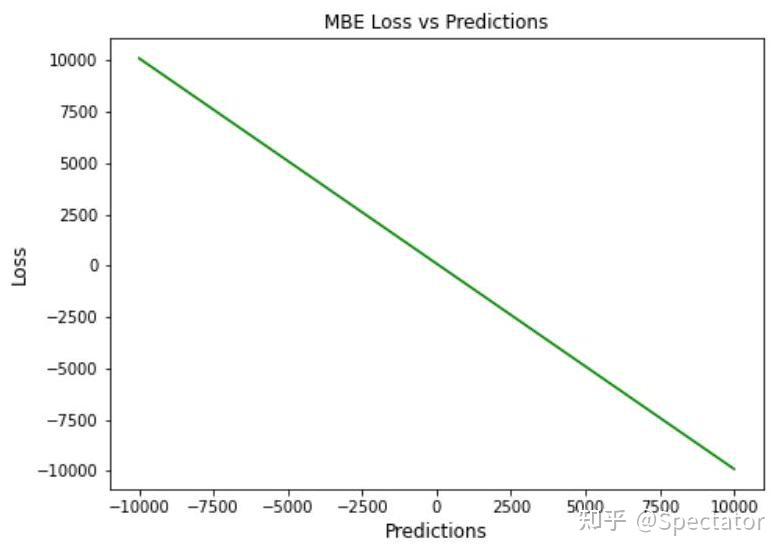 MBE Loss与Predictions的性能图优点缺点如果您希望识别和纠正模型偏差,则应使用MBE确定模型的方向(即,它是正向还是负向)。MBE倾向于在一个方向上不断犯错,同时试图预测信号模式。考虑到误差往往会相互抵消,对于(−∞,∞)范围的数字,不是一个合适的损失函数。4 Relative Absolute Error (RAE) MBE Loss与Predictions的性能图优点缺点如果您希望识别和纠正模型偏差,则应使用MBE确定模型的方向(即,它是正向还是负向)。MBE倾向于在一个方向上不断犯错,同时试图预测信号模式。考虑到误差往往会相互抵消,对于(−∞,∞)范围的数字,不是一个合适的损失函数。4 Relative Absolute Error (RAE)RAE的计算将总绝对误差除以平均值与实际值之间的绝对差值: 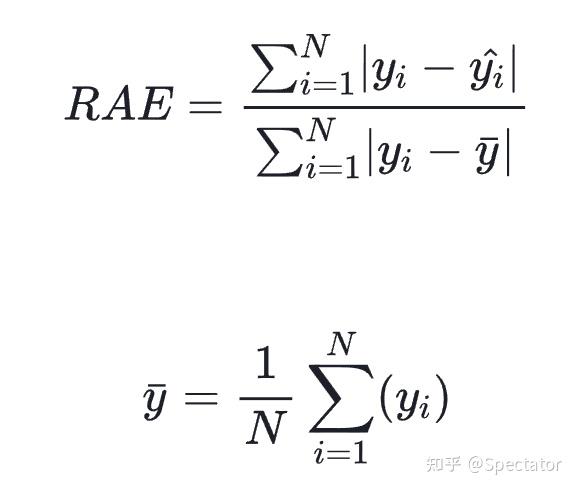 RAE是一种基于比率的指标,用于评估预测模型的有效性。RAE 的可能值介于 0 和 1 之间。接近零的值(零是最佳值)是良好模型的特征。  RAE Loss与Predictions的性能图优点缺点RAE可以比较以不同单位测量误差的模型。如果参考预测等于真值,RAE可能变得不可预测,这是其主要缺点之一。5 Relative Squared Error (RSE) RAE Loss与Predictions的性能图优点缺点RAE可以比较以不同单位测量误差的模型。如果参考预测等于真值,RAE可能变得不可预测,这是其主要缺点之一。5 Relative Squared Error (RSE)RSE 衡量在没有简单预测器的情况下结果的不准确程度。这个简单的预测变量仅代表实际值的平均值。结果,相对平方误差将总平方误差除以简单预测变量的总平方误差以对其进行归一化。可以在以不同单位计算误差的模型之间进行比较。 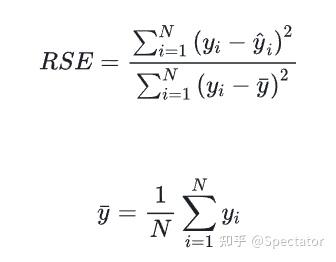  RSE Loss与Predictions的性能图优点缺点RSE与规模无关。当以不同单位测量误差时,它可以比较模型。RSE不受预测的平均值或大小的影响。6 Mean Absolute Percentage Error (MAPE) RSE Loss与Predictions的性能图优点缺点RSE与规模无关。当以不同单位测量误差时,它可以比较模型。RSE不受预测的平均值或大小的影响。6 Mean Absolute Percentage Error (MAPE)平均绝对百分比误差 (MAPE),也称为平均绝对百分比偏差 (MAPD),是用于评估预测系统准确性的指标。它通过从实际值减去预测值的绝对值除以实际值来计算每个时间段的平均绝对百分比误差百分比。由于变量的单位缩放为百分比单位,因此平均绝对百分比误差 (MAPE) 广泛用于预测误差。当数据中没有异常值时,它效果很好,常用于回归分析和模型评估。 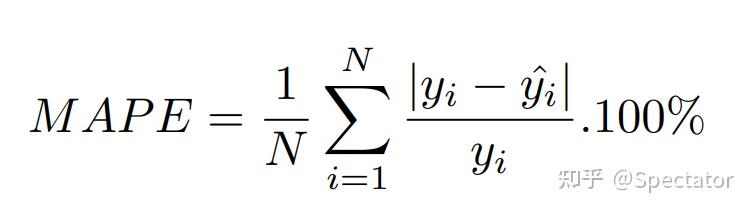 MAPE Loss与Predictions的性能图优点缺点MAPE损失是通过将所有误差标准化为百分之一来计算的。由于误差估计以百分比表示,MAPE与变量的规模无关。由于MAPE利用了绝对百分比误差,因此避免了正数抵消负数的问题。因为MAPE方程的分母是预测输出,它可以是零,导致未定义的值。MAPE对正错误的惩罚小于负错误。因此,当我们比较预测算法的精度时,它是有偏差的,因为它默认选择结果太低的算法。7 Root Mean Squared Error (RMSE) MAPE Loss与Predictions的性能图优点缺点MAPE损失是通过将所有误差标准化为百分之一来计算的。由于误差估计以百分比表示,MAPE与变量的规模无关。由于MAPE利用了绝对百分比误差,因此避免了正数抵消负数的问题。因为MAPE方程的分母是预测输出,它可以是零,导致未定义的值。MAPE对正错误的惩罚小于负错误。因此,当我们比较预测算法的精度时,它是有偏差的,因为它默认选择结果太低的算法。7 Root Mean Squared Error (RMSE)MSE 的平方根用于计算 RMSE。均方根偏差是 RMSE 的另一个名称。它考虑了实际值的变化并测量误差的平均幅度。RMSE 可以应用于各种特征,因为它有助于确定特征是否增强模型预测。当非常不希望出现巨大错误时,RMSE 最有用。 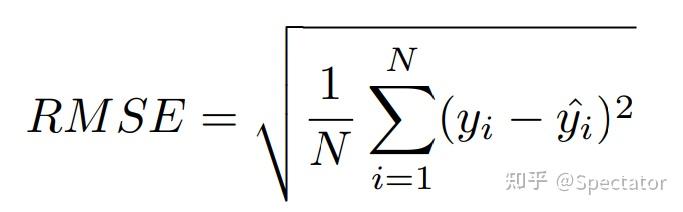  RMSE Loss与Predictions的性能图优点缺点RMSE用作模型的训练启发式。许多优化方法选择它,因为它很容易区分,并且计算简单。即使值更大,极端损失也更少,平方根导致RMSE惩罚的误差小于MSE。由于RMSE仍然是一个线性评分函数,所以梯度在最小值附近是突变的。随着误差幅度的增加,数据的规模决定了RMSE,对异常值的敏感性也随之增加。为了收敛模型,必须降低灵敏度,从而导致使用RMSE的额外开销。8 Mean Squared Logarithmic Error (MSLE) RMSE Loss与Predictions的性能图优点缺点RMSE用作模型的训练启发式。许多优化方法选择它,因为它很容易区分,并且计算简单。即使值更大,极端损失也更少,平方根导致RMSE惩罚的误差小于MSE。由于RMSE仍然是一个线性评分函数,所以梯度在最小值附近是突变的。随着误差幅度的增加,数据的规模决定了RMSE,对异常值的敏感性也随之增加。为了收敛模型,必须降低灵敏度,从而导致使用RMSE的额外开销。8 Mean Squared Logarithmic Error (MSLE)均方对数误差 (MSLE) 衡量实际值与预期值之间的差异。添加对数减少了 MSLE 对实际值和预测值之间的百分比差异以及两者之间的相对差异的关注。MSLE 将粗略地处理小的实际值和预期值之间的微小差异以及大的真实值和预测值之间的巨大差异。 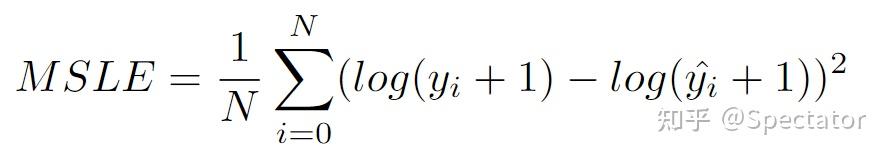 这种损失可以解释为真实值和预测值之间比率的度量:   MSLE Loss与Predictions的性能图优点缺点将小的实际值和预测值之间的小差异视为大的实际值与预测值之间大的差异。MSLE惩罚不充分的预测比惩罚过度的预测更多。9 Root Mean Squared Logarithmic Error (RMSLE) MSLE Loss与Predictions的性能图优点缺点将小的实际值和预测值之间的小差异视为大的实际值与预测值之间大的差异。MSLE惩罚不充分的预测比惩罚过度的预测更多。9 Root Mean Squared Logarithmic Error (RMSLE)RMSLE通过应用log到实际和预测的值,然后进行相减。当同时考虑小误差和大误差时,RMSLE 可以避免异常值的影响。  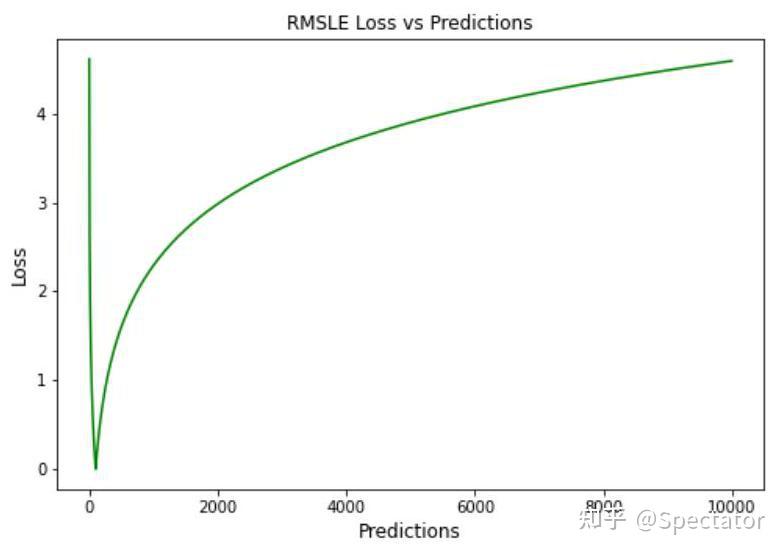 RMSLE Loss与Predictions的性能图优点缺点RMSLE适用于多种尺度,且不依赖于尺度。它不受显著异常值的影响。仅考虑实际值与预期值之间的相对误差。RMSLE是有偏见的处罚,低估比高估受到更严重的惩罚。10 Normalized Root Mean Squared Error (NRMSE) RMSLE Loss与Predictions的性能图优点缺点RMSLE适用于多种尺度,且不依赖于尺度。它不受显著异常值的影响。仅考虑实际值与预期值之间的相对误差。RMSLE是有偏见的处罚,低估比高估受到更严重的惩罚。10 Normalized Root Mean Squared Error (NRMSE)归一化均方根误差 (NRMSE) RMSE 有助于不同尺度模型之间的比较。该变量具有观测范围的归一化 RMSE (NRMSE),它将 RMSE 连接到观测范围。 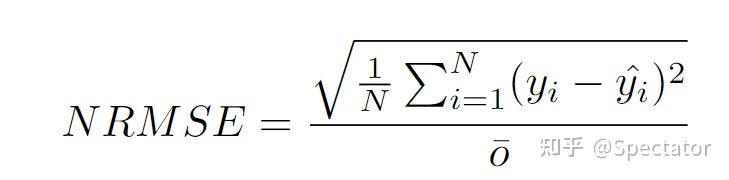  NRMSE Loss与Predictions的性能图优点缺点NRMSE克服了尺度依赖性,简化了不同尺度或数据集模型之间的比较。NRMSE失去与响应变量相关的单位。11 Relative Root Mean Squared Error (RRMSE) NRMSE Loss与Predictions的性能图优点缺点NRMSE克服了尺度依赖性,简化了不同尺度或数据集模型之间的比较。NRMSE失去与响应变量相关的单位。11 Relative Root Mean Squared Error (RRMSE)RRMSE 是没有维度的 RMSE 变体。相对均方根误差 (RRMSE) 是一种均方根误差度量,它已根据实际值进行缩放,然后由均方根值归一化。虽然原始测量的尺度限制了 RMSE,但 RRMSE 可用于比较各种测量方法。当您的预测被证明是错误的时,会出现增强的 RRMSE,并且该错误由 RRMSE 相对或以百分比表示。  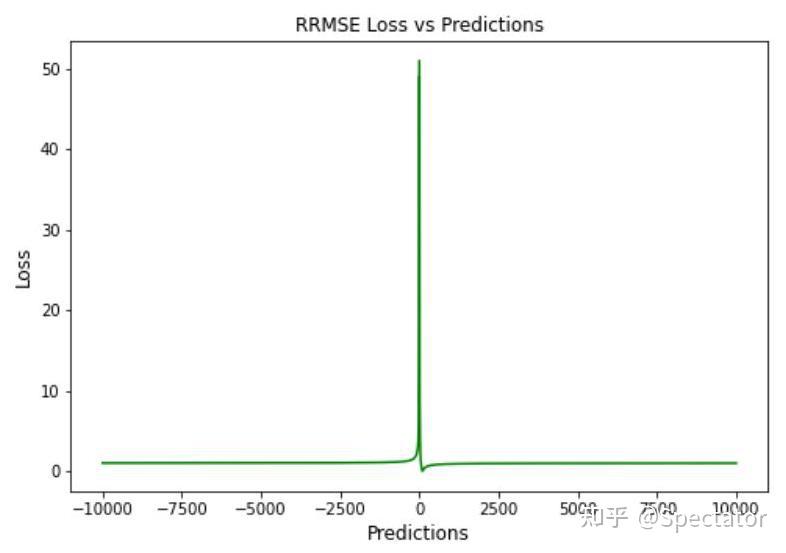 RRMSE Loss与Predictions的性能图优点缺点RRMSE可用于比较不同的测量技术。RRMSE可以隐藏实验结果中的不精确性。12 Huber Loss RRMSE Loss与Predictions的性能图优点缺点RRMSE可用于比较不同的测量技术。RRMSE可以隐藏实验结果中的不精确性。12 Huber LossHuber 损失是二次和线性评分算法的理想组合。还有超参数 delta.对于小于 delta 的损失值,应该使用 MSE;对于大于 delta 的损失值,应使用 MAE。这成功地结合了两种损失函数的最大特点。   Huber Loss与Predictions的性能图优点缺点超参数δ以上的线性保证了异常值被赋予适当的权重(不像MSE中那样极端)。添加超参数δ允许灵活地适应任何分布。超参数δ下的弯曲形状保证了在反向传播过程中台阶的长度是正确的由于额外的条件和比较,Huber损失在计算上非常昂贵,特别是如果数据集很大的话。为了实现最佳结果,必须优化,这提高了训练要求。13 LogCosh Loss Huber Loss与Predictions的性能图优点缺点超参数δ以上的线性保证了异常值被赋予适当的权重(不像MSE中那样极端)。添加超参数δ允许灵活地适应任何分布。超参数δ下的弯曲形状保证了在反向传播过程中台阶的长度是正确的由于额外的条件和比较,Huber损失在计算上非常昂贵,特别是如果数据集很大的话。为了实现最佳结果,必须优化,这提高了训练要求。13 LogCosh LossLogCosh 计算误差的双曲余弦的对数。这个函数比二次损失更平滑。它的功能类似于 MSE,但不受重大预测误差的影响。鉴于它使用线性和二次评分技术,它非常接近 Huber 损失。   LogCosh Loss与Predictions的性能图优点缺点因为Logcosh计算误差的双曲余弦的对数。因此,由于其连续性和可微性,它比Huber损失具有相当大的优势。与Huber相比,所需的计算更少。它的适应性不如Huber,因为没有超参数进行调节。推导比Huber损失更复杂,需要更多的研究。14 Quantile Loss LogCosh Loss与Predictions的性能图优点缺点因为Logcosh计算误差的双曲余弦的对数。因此,由于其连续性和可微性,它比Huber损失具有相当大的优势。与Huber相比,所需的计算更少。它的适应性不如Huber,因为没有超参数进行调节。推导比Huber损失更复杂,需要更多的研究。14 Quantile Loss分位数回归损失函数用于预测分位数。分位数是指示组中有多少值低于或高于特定阈值的值。它计算跨预测变量(独立)变量值的响应(因)变量的条件中位数或分位数。除了第 50 个百分位数是 MAE,损失函数是 MAE 的扩展。它不对响应的参数分布做出任何假设,甚至为具有非常量方差的残差提供预测区间。 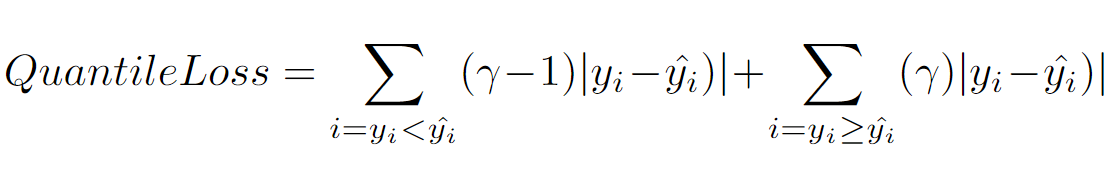  Quantile Loss与Predictions的性能图优点缺点可以避免异常值的影响。与点估计相比,这有利于进行区间预测。该函数也可用于神经网络和基于树的模型中,以确定预测间隔。Quantile Loss是计算密集型的。如果我们估计平均值或使用平方损失来量化效率,则Quantile Loss将更糟。四 实验分析各种损失函数在时间序列任务上的表现 Quantile Loss与Predictions的性能图优点缺点可以避免异常值的影响。与点估计相比,这有利于进行区间预测。该函数也可用于神经网络和基于树的模型中,以确定预测间隔。Quantile Loss是计算密集型的。如果我们估计平均值或使用平方损失来量化效率,则Quantile Loss将更糟。四 实验分析各种损失函数在时间序列任务上的表现数据集 电力负荷数据集 - 数据集包含 370 点/客户端的电力消耗。交通数据集 - 数据集包含 15 个月的每日数据(440 条每日记录),描述了旧金山湾区高速公路不同车道随时间变化的占用率,数值介于 0 和 1 之间。Favorita 数据集 - 包含日期、商店和商品信息、该商品是否正在促销以及单位销售额的杂货数据集。波动率数据集 - 数据集包含衡量金融资产或指数过去波动性。评估指标实验使用P10、P50和P90度量评估了所有损失函数的性能。预测的上限和下限可以通过分位数提供。80%置信区间是可以获得的值范围,例如,通过使用预测类型0.1(P10)和0.9(P90)。在10%的情况下,观测值应小于P10值,在90%的情况下P90值应更高。 总的来说: 在电力数据集的任务上,Quantile Loss、MSE和RRMSE损失表现良好。在交通数据集任务上,Log Cosh Loss、Quantile Loss 和 MAE 表现更好。在 Favorita 数据集任务上,RAE、LogCosh Loss 和 Quantile Loss 表现更好。在波动率数据集任务上,Quantile Loss、MAE 和 Huber Loss 表现更好。   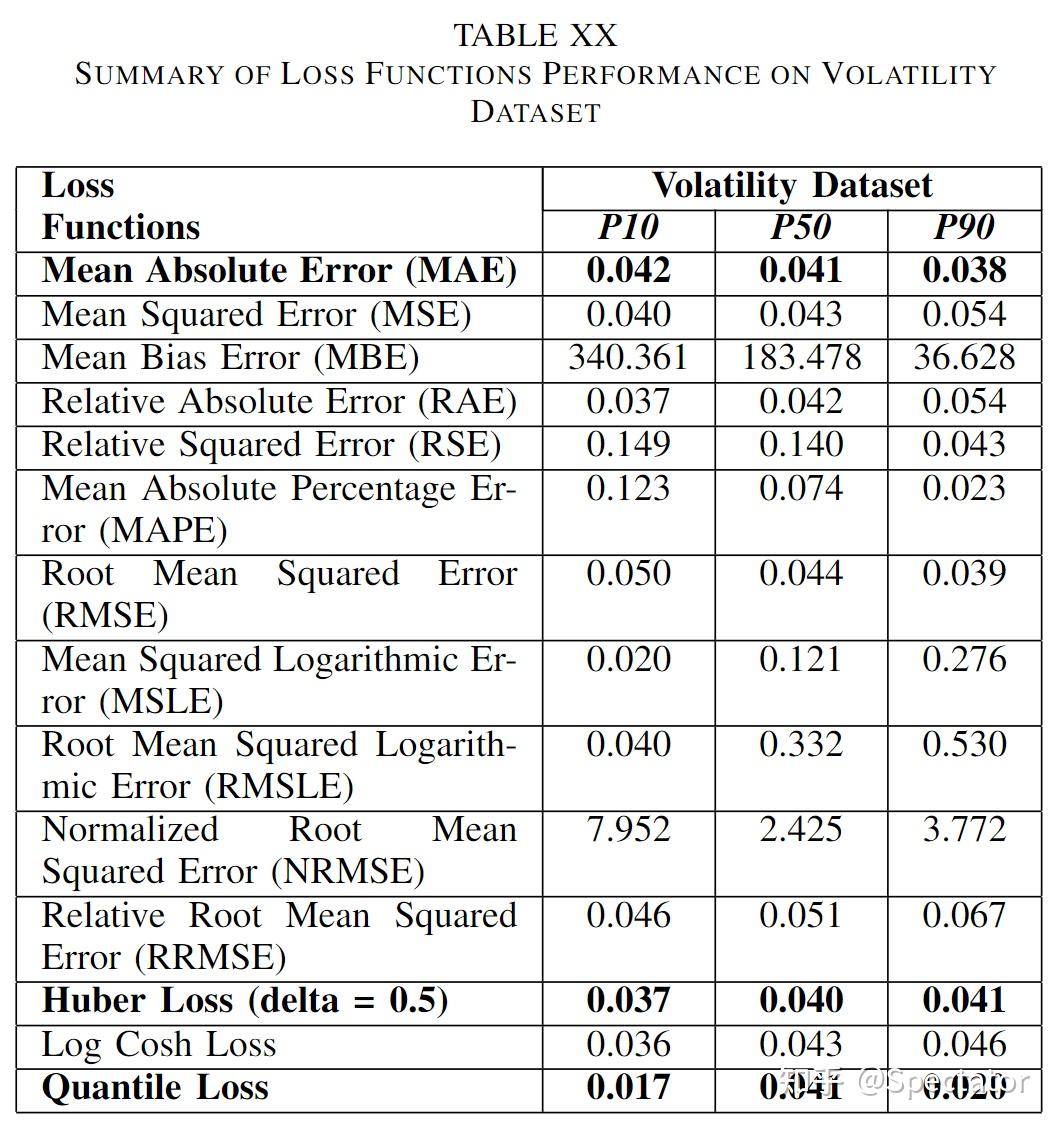 五 总结展望 五 总结展望损失函数在确定给定目标的良好拟合模型中起着关键作用。对于时间序列预测等复杂目标,不可能确定通用损失函数。有很多因素,如异常值、数据分布的偏差、ML模型要求、计算要求和性能要求。没有适用于所有类型数据的单一损失函数。在主要关注模型架构和数据类型的学术环境中,损失函数可以通过用于训练的数据集属性(如分布、边界等)来确定。这项工作试图构建特定损失函数可能有用的情况,例如在数据集中出现异常值的情况下,均方误差是最佳策略;然而,如果有更少的异常值,则平均绝对误差将是比MSE更好的选择。同样,如果我们希望保持平衡,并且我们的目标基于百分位数损失,那么使用LogCosh是更好的方法。本文总结了用于时间序列预测的14个著名损失函数,并开发了一种易于处理的损失函数形式,用于改进和更准确的优化。 参考: P10,P50,P90和方差 |
【本文地址】
| 今日新闻 |
| 推荐新闻 |
| 专题文章 |