| 数学建模之预测模型简要分析 | 您所在的位置:网站首页 › 预测模型分析的步骤 › 数学建模之预测模型简要分析 |
数学建模之预测模型简要分析
|
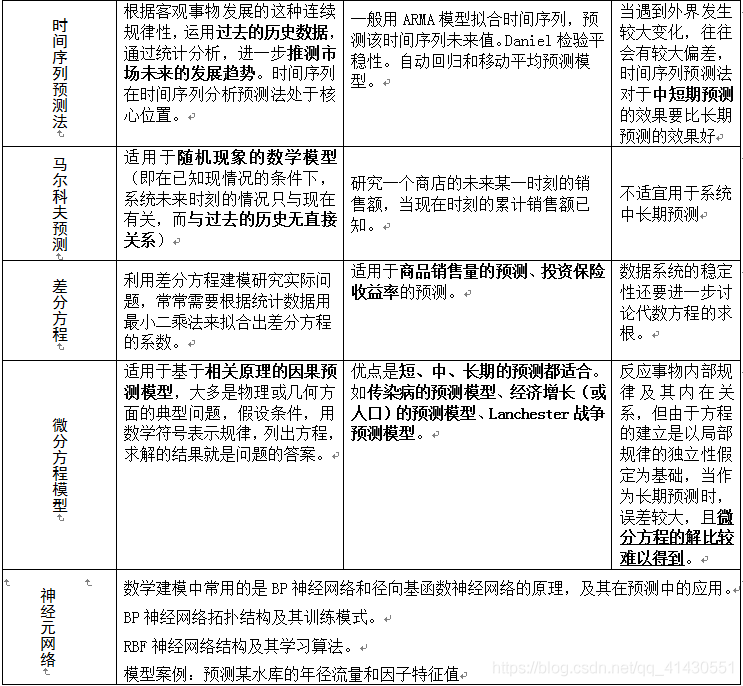
以下对数学建模常用的几种预测方法进行归纳总结: 1.灰色预测模型: 1.1 GM(1,1)预测模型实际操作 1)数据检验与处理,判断数据列的级比是否都落在可容覆盖内,从而判断已知该数据列是否可进行灰色预测; 2)根据预测算法建立模型得到预测值; 3)检验预测值----残差检验、级比偏差值检验; 4)给出预测预报即结论。 通过对原始数据的整理寻找数的规律,分为三类: a、累加生成:通过数列间各时刻数据的依个累加得到新的数据与数列。累加前数列为原始数列,累加后为生成数列。 b、累减生成:前后两个数据之差,累加生成的逆运算。累减生成可将累加生成还原成非生成数列。 c、映射生成:累加、累减以外的生成方式。 2.时间序列预测模型: 2.1常用方法 1)移动平均预测法—算术平均数、加权平均数等(逐期增量大体相同的情况) 2)指数平滑预测法—离预测期近的数据赋予较大权重,权数按距离远近呈指数递减。 3.趋势外推预测方法: 趋势外推预测方法是根据事物的历史和现实数据,寻求事物随时间推移而发展变化的规律,从而推测其未来状况的一种常用的预测方法。 趋势外推法的假设条件是: (1)假设事物发展过程没有跳跃式变化,即事物的发展变化是渐进型的。 (2)假设所研究系统的结构、功能等基本保持不变,即假定根据过去资料建立的趋势外推模型能适合未来,能代表未来趋势变化的情况。 由以上两个假设条件可知,趋势外推预测法是事物发展渐进过程的一种统计预测方法。简言之,就是运用一个数学模型,拟合一条趋势线,然后用这个模型外推预测未来时期事物的发展。 趋势外推预测法主要利用描绘散点图的方法(图形识别)和差分法计算进行模型选择。 主要优点是:可以揭示事物发展的未来,并定量地估价其功能特性。 趋势外推预测法比较适合中、长期新产品预测,要求有至少5年的数据资料。 4.回归预测方法 回归预测方法是根据自变量和因变量之间的相关关系进行预测的。自变量的个数可以一个或多个,根据自变量的个数可分为一元回归预测和多元回归预测。同时根据自变量和因变量的相关关系,分为线性回归预测方法和非线性回归方法。回归问题的学习等价于函数拟合:选择一条函数曲线使其很好的拟合已知数据且能很好的预测未知数据。 5.卡尔曼滤波预测模型 卡尔曼滤波是以最小均方误差为估计的最佳准则,来寻求一套递推估计的模型,其基本思想是: 采用信号与噪声的状态空间模型,利用前一时刻地估计值和现时刻的观测值来更新对状态变量的估计,求出现时刻的估计值。 它适合于实时处理和计算机运算。卡尔曼滤波器问题由预计步骤,估计步骤,前进步骤组成。 在预计步骤中, t时状态的估计取决于所有到t-1 时的信息。在估算步骤中, 状态更新后, 估计要于时间t的实际观察比较。更新的状态是较早的推算和新观察的综合。 置于每一个成分的权重由“ Kalmangain”(卡尔曼增益) 决定,它取决于噪声 w 和 v。(噪声越小,新的观察的可信度越高,权重越大,反之亦然)。前进步骤意味着先前的“新”观察在准备下一轮预计和估算时变成了“旧” 观察。 在任何时间可以进行任何长度的预测(通过提前状态转换)。 自适应卡尔曼滤波器的主要优点是只需要少量的数据得到预测的起始点(尽管多一点数据会使结果好一点),它可以自我调节,从连续的观察中自动设置参数。缺点是对考虑复杂性的能力有限,有时收敛慢或不收敛(有正式的标致来判断是否收敛)。 6.组合预测模型 组合预测法是对同一个问题,采用多种预测方法。组合的主要目的是综合利用各种方法所提供的信息,尽可能地提高预测精度。组合预测有 2 种基本形式,一是等权组合, 即各预测方法的预测值按相同的权数组合成新的预测值;二是不等权组合,即赋予不同预测方法的预测值不同的权数。 这 2 种形式的原理和运用方法完全相同,只是权数的取定有所区别。 根据经验,采用不等权组合的组合预测法结果较为准确。 |

【本文地址】