| python如何找出声母韵母声调出现次数最多的成语 | 您所在的位置:网站首页 › 韵母en或eng的词语 › python如何找出声母韵母声调出现次数最多的成语 |
python如何找出声母韵母声调出现次数最多的成语
|
文章目录
背景建模流程预处理程序生成频率表和成语信息统计不重复元素个数更新元素词典频数表转换为频率表
打分并排序
结果讨论
背景
昨天玩了这么个游戏 点击此处跳转游戏界面
假如不看提示,就只能盲猜一个成语。在这种情况下,猜什么样的成语才有利于尽快破解答案呢? 根据游戏规则,最坏的情况,就是我猜第一个词之后,返回的结果是没有一个声母、韵母或声调(姑且成为拼音元素)是猜中的。那么,比较聪明的做法,当然应该猜拼音元素都比较多一点的词,这样说不定就能撞上几个元素。最优的情况,当然就是这个四字成语有不同的四个声母、四个韵母、四个声调,一共12个拼音元素。 不过,如果这个成语很生僻(如哺糟歠醨,有12个相异的拼音元素),那用它作为开局成语似乎也没什么意义,还不如用常用一点的。 这是成语常不常用,如果关注细粒度的东西,我们还希望声母、韵母、声调、汉字也常用。 需求来了:如何找到拼音元素为12且尽量常用的成语呢? 建模流程思路太简单了,只要把所有的成语都统计一遍就好了,然后对各成语排序,下面就来实现! 首先我们来看下数据集:THUOCL:清华大学开放中文词库 | 成语
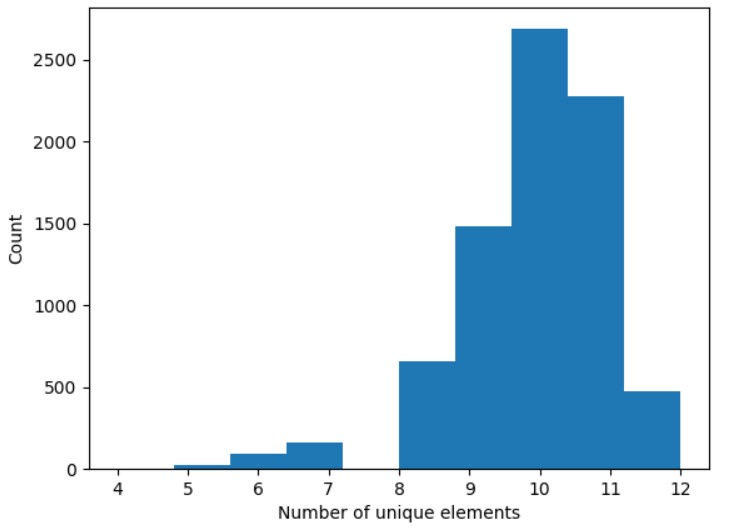
这个数据集中总共有8519条成语,右边的数字是词频 (Document frequency),THU真贴心啊,这样我就可以很方便地度量常用程度了。所以, 第一步就是要预处理这个数据集,转换成python能处理的。第二步,就是对每个成语,统计它的各个拼音元素和汉字,保存下来。顺便还能在统计每个成语时,同时统计的所有的声母、韵母、汉字的出现频率。注意,这里我们并不打算统计四个声调的出现频率了,因为对于每一个12个拼音元素的成语,都是具有四个不同的声调,因此声调作为成语的得分指标没有任何意义。第三步,根据第二步的统计结果,首先取出12个拼音元素的成语,然后对其打分、排序。所以,咱们的主程序就是以下这样的。 import pickle import pandas as pd # pypinyin是python有关拼音的包 from pypinyin import lazy_pinyin, Style from pypinyin.contrib import tone_convert as tcv from typing import List, Dict from functools import partial from matplotlib import pyplot as plt import numpy as np if __name__ == '__main__': preprocess() gen_fq_idiom_info() score_and_sort()下面讲讲其中涉及到的自定义函数 预处理程序 def preprocess(): with open('THUOCL_chengyu.txt', 'r', encoding='utf-8') as th_idiom_file: data = th_idiom_file.readlines() idiom_df_dicts = [] for each in data: text, df = each.split() if len(text) == 4: # 只要四字成语 idiom_df_dicts.append({'text': text, 'df': df}) with open('idiom-df dict.pkl', 'wb') as pf1: pickle.dump(idiom_df_dicts, pf1)我们把成语和词频放进字典中,然后保存在pickle文件里,因为pickle文件能够保存很多python类型的数据,而且读写比较快。 生成频率表和成语信息注意:根据 《汉语拼音方案》 , 'y'和'w',都不是声母。但这里我们不这么严格,因此下面一些参数会指定 strict=False ,即非严格转换。 def gen_fq_idiom_info(): with open('idiom-df dict.pkl', 'rb') as pf2: idiom_dicts = pickle.load(pf2) initial_dct = dict() # 统计声母频率 final_dct = dict() # 统计韵母频率 char_dct = dict() # 统计汉字频率 for ind, entry in enumerate(idiom_dicts): # idiom_pinyin形式为['ā', 'bí', 'dì', 'yù'] idiom_pinyin = lazy_pinyin(entry['text'], style=Style.TONE3) # 抽取各个声母 initials = list(map(partial( tcv.to_initials, strict=False), idiom_pinyin)) # y w都当作声母 if '' in initials: # 删去无声母情况 initials.remove('') # 存放该成语的声母 entry['initials'] = initials # 存放该成语的不同声母个数 entry['init_num'] = count_unique(initials) # 更新声母频率字典 initial_dct = update_element_dct(initial_dct, initials) # 抽取各个韵母 finals = list(map(tcv.to_finals, idiom_pinyin)) # 统计结果显示,塞翁得马和瓮天蠡海里的eng都被当成了ueng,不符合现代拼音习惯,因此换掉 if 'ueng' in finals: finals[finals.index('ueng')] = 'eng' # 存放该成语的韵母 entry['finals'] = finals # 存放该成语的不同韵母个数 entry['final_num'] = count_unique(finals) # 更新韵母频率字典 final_dct = update_element_dct(final_dct, finals) # 抽取音调 tones = list(map(lambda x: x[-1], idiom_pinyin)) # 存放该成语的不同音调个数 entry['tone_num'] = count_unique(tones) # 存放该成语的总计不同拼音元素个数 entry['element_num'] = entry['init_num'] + idiom_dicts[ ind]['final_num'] + entry['tone_num'] # 抽取汉字 chars = ' '.join(entry['text']).split() # 存放该成语的汉字 entry['chars'] = chars # 不统计不同汉字个数,因为若汉字同,则声母韵母也同,属重复指标 # 更新汉字频率字典 char_dct = update_element_dct(char_dct, chars) initial_dct = count2fq(initial_dct) final_dct = count2fq(final_dct) char_dct = count2fq(char_dct) # 保存频率结果 with open('fq of initial, final and char.pkl', 'wb') as pf3: pickle.dump({ 'initial-fq': initial_dct, 'final-fq': final_dct, 'char-fq': char_dct }, pf3) with open('idiom-element info.pkl', 'wb') as pf4: pickle.dump(idiom_dicts, pf4)这其中又用到了一些自定义的函数,实现一些小功能。 统计不重复元素个数 def count_unique(str_lst: List[str]) -> int: """ 对于给定的声母/韵母/声调列表,统计不重复元素个数 :param str_lst:声母/韵母/声调列表 :return: 不重复元素个数 """ str_set = set(str_lst) # 去重 return len(str_set) # 统计元素个数 更新元素词典 def update_element_dct(element_dct: Dict, update_val: List[str]) -> Dict: """ 更新一个存放元素频次的字典 :param element_dct: 声母/韵母/汉字的字典 :param update_val: 由某种元素对象组成的列表 :return: 更新后的字典 """ for element in update_val: if element_dct.__contains__(element): element_dct[element] += 1 # 是已有元素 else: element_dct[element] = 1 # 是新元素 return element_dct 频数表转换为频率表 def count2fq(cnt_dct: Dict) -> Dict: """ 用于把一个存放各元素频数的字典转换成频率 :param cnt_dct:存放各元素频数的字典 :return:存放各元素频率的字典 """ gross = sum(cnt_dct.values()) fq_dct = dict(zip(cnt_dct.keys(), map( lambda x: x / gross, cnt_dct.values()))) return fq_dct 打分并排序最简单的就是直接相加了。 def score_and_sort(): with open('fq of initial, final and char.pkl', 'rb') as pf5: data1 = pickle.load(pf5) initial_fq = data1['initial-fq'] final_fq = data1['final-fq'] char_fq = data1['char-fq'] with open('idiom-element info.pkl', 'rb') as pf6: idiom_info = pickle.load(pf6) element_nums = [entry['element_num'] for entry in idiom_info] # 直方图可视化 plt.hist(element_nums) plt.xlabel('Number of unique elements') plt.ylabel('Count') # 提取拼音元素个数为12的 idiom_info = sorted( idiom_info, key=lambda x: x['element_num'], reverse=True) idiom_info = idiom_info[:element_nums.count(12)] # 指标:df、initials_fq、final_fq、char_fq text_lst = [] init_score_lst = [] final_score_lst = [] char_score_lst = [] df_score_lst = [] for entry in idiom_info: text_lst.append(entry['text']) init_score_lst.append(score(initial_fq, entry['initials'])) final_score_lst.append(score(final_fq, entry['finals'])) char_score_lst.append(score(char_fq, entry['chars'])) df_score_lst.append(entry['df']) # 归一化 score_mat = np.asarray(( init_score_lst, final_score_lst, char_score_lst, df_score_lst ), dtype=float).T score_mat = (score_mat - score_mat.min(axis=0)) / score_mat.ptp(axis=0) score_mat = np.c_[score_mat, score_maan(axis=1, keepdims=True)] score_frame = pd.DataFrame(score_mat, index=text_lst, columns=[ '声母得分', '韵母得分', '汉字得分', '词频得分', '平均分']) score_frame.sort_values(by='平均分', inplace=True, ascending=False) for col in score_frame.columns: cur_score = score_frame[col].to_list() # 求各指标的排名 score_frame[col + '排名'] = [ sorted(cur_score, reverse=True ).index(each) + 1 for each in cur_score] # 调整各列顺序 score_frame = score_frame[score_frame.columns[[9, 4, 5, 0, 6, 1, 7, 2, 8, 3]]] writer = pd.ExcelWriter('只考虑12拼音元素的成语.xlsx') score_frame.to_excel(writer) writer.save()打分规则是什么呢?最简单的就是直接相加了。 def score(fq_dct: Dict, element_lst: List) -> int: """ 计算第二轮筛选给定成语的总频率(得分) :param fq_dct: 各频率 :param element_lst: 成语各元素 :return: 总频率 """ # 用频率替换element_lst中的每个元素,然后求和 return sum(map(lambda x: fq_dct[x], element_lst)) 结果讨论
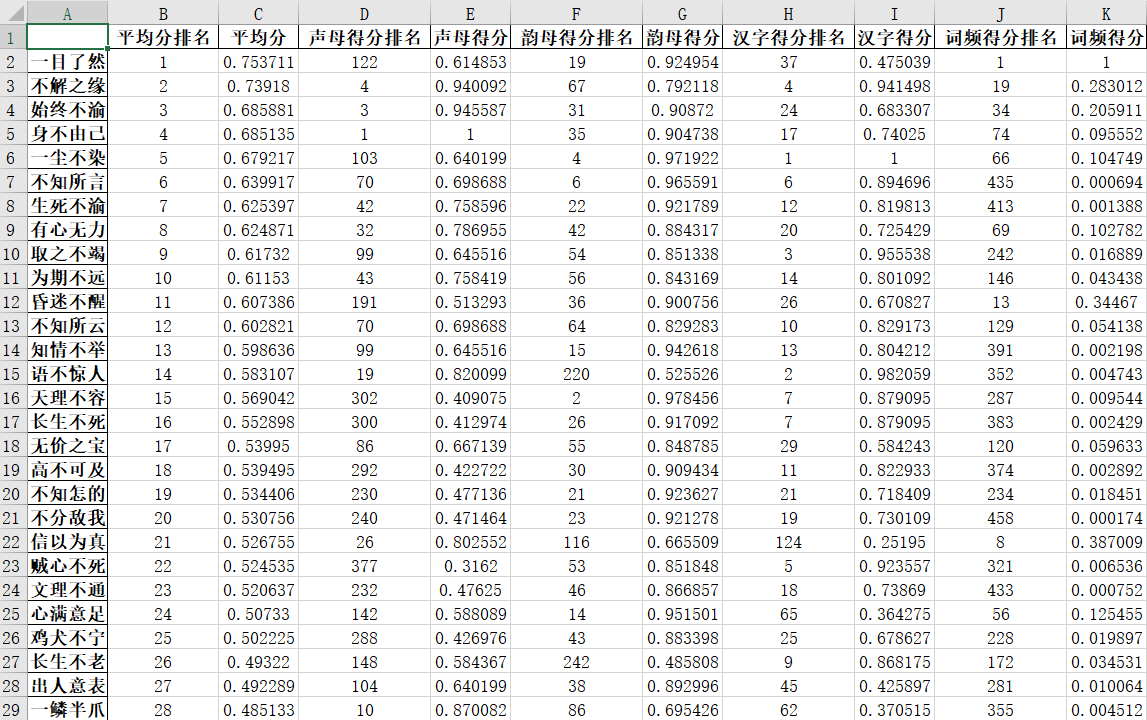
以上就是不同成语的拼音元素个数分布了,可以看到最优情况(4声母、4韵母、4声调)的成语还是很多的,有476个。 对这476个进一步打分、排序。
可以看出来,排在前面的基本上都是有“一”、“不”这种汉字,确实,这些在成语里挺常见的。 如果我们觉得算术平均值不太合理,还可以在Excel里面手动加权平均。 |

 其实,我猜第一个词之前就看了提示,才会知道成语里有个“风”字,所以能很快地猜出来。
其实,我猜第一个词之前就看了提示,才会知道成语里有个“风”字,所以能很快地猜出来。
【本文地址】