| 音频格式之AAC:(3)AAC编解码原理详解 | 您所在的位置:网站首页 › 音频压缩编码格式 › 音频格式之AAC:(3)AAC编解码原理详解 |
音频格式之AAC:(3)AAC编解码原理详解
|
系列文章目录
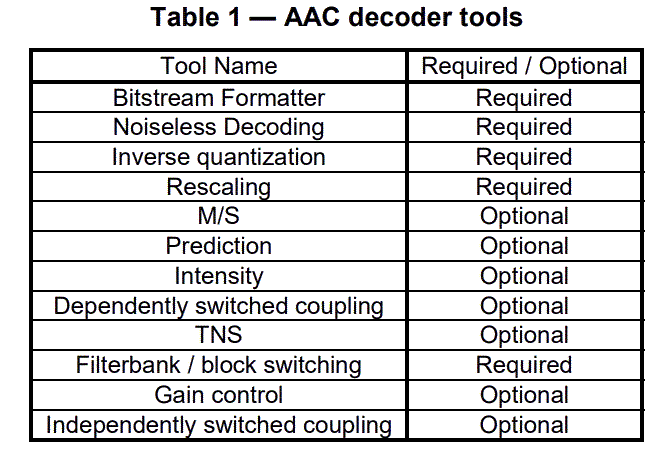
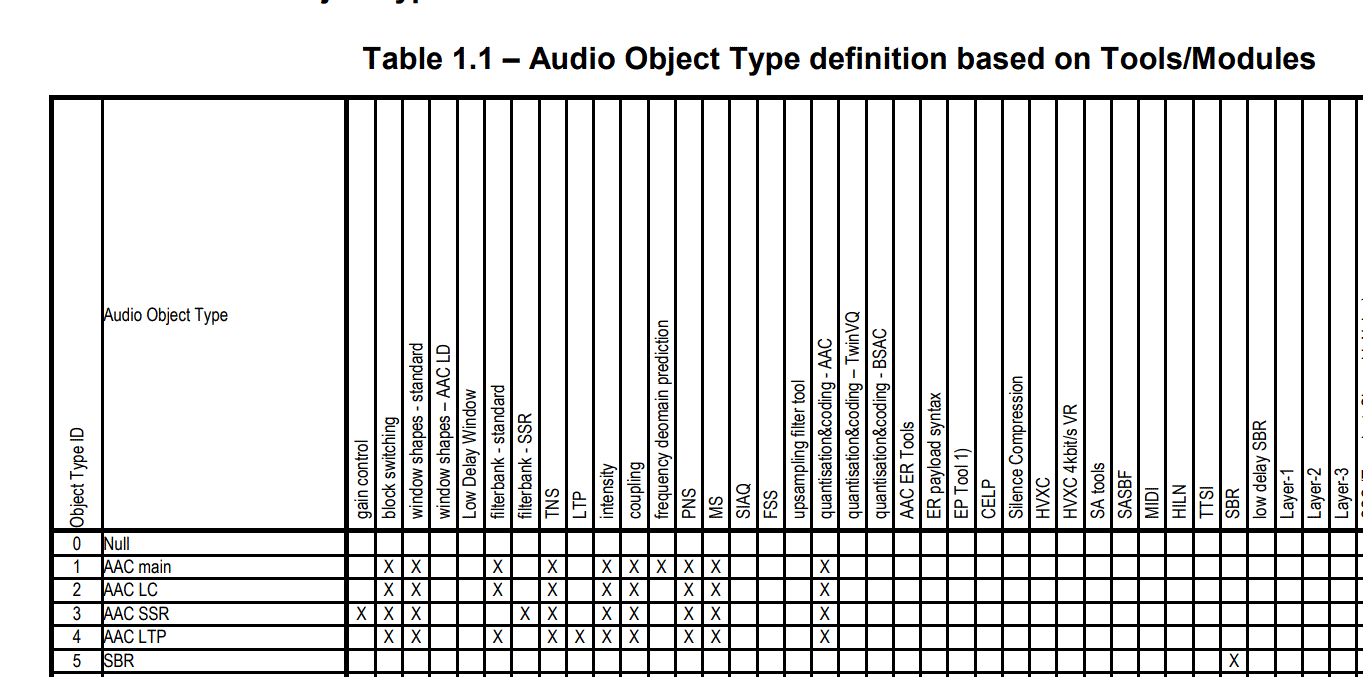
音频格式的介绍文章系列: 音频编解码格式介绍(1) ADPCM:adpcm编解码原理及其代码实现 音频编解码格式介绍(2) MP3 :音频格式之MP3:(1)MP3封装格式简介 音频编解码格式介绍(2) MP3 :音频格式之MP3:(2)MP3编解码原理详解 音频编解码格式介绍(3) AAC :音频格式之AAC:(1)AAC简介 音频编解码格式介绍(3) AAC :音频格式之AAC:(2)AAC封装格式ADIF,ADTS,LATM,extradata及AAC ES存储格式 音频编解码格式介绍(3) AAC :音频格式之AAC:(3)AAC编解码原理详解 文章目录 系列文章目录1、AAC简介2、AAC编解码模块介绍3、AAC编码流程1:听觉心里模型(Psychoacoustic Model)2:增益控制(gain control)3:MDCT4:瞬时噪声整形TNS(Temporal Noise Shaping Module)5:Joint Stereo Coding与预测(Prediction)模块6:量化与编码 4、AAC解码流程1)Bitstream Formatter,码流解析模块。2)Noiseless Decoding,无噪编解码模块。3)Inverse Quantization,量化和反量化模块。4)Rescaling,缩放因子处理模块。5)M/S,Mid/Side 立体声编解码模块。6)Prediction,预测模块。7)Intensity,强度立体声编解码模块。8)Dependently Switched Coupling,非独立交换耦合模块。9)TNS,瞬时噪音整形模块。10)Filterbank/Block Switching,滤波器组/块切换模块。11)Gain Control,增益控制模块。12)Independently Switched Coupling,独立交换耦合模块。1)LTP(Long Term Prediction),长时预测模块。2)PNS(Perceptual Noise Substitution),知觉噪声替换模块。3)SBR(Spectral Band Replication),频段复制技术。4)PS(Parametric Stereo),参数立体声技术。 参考资料 1、AAC简介AAC,英文全称 Advanced Audio Coding,是由 Fraunhofer IIS、杜比实验室、AT&T、Sony 等公司共同开发,在 1997 年推出的基于 MPEG-2 的有损数字音频压缩的专利音频编码标准。 1997年制订不兼容MPEG-1的音频标准MPEG-2 NBC,即MPEG-2 AAC 1999年MPEG-2 AAC增加LTP(Long Term Prediction)和PNS(Perceptual Noise Substitution)工具,形成MPEG-4 AAC v1 2002年MPEG-4 AAC v1增加了SBR(Spectral Band Replication)和错误鲁棒性工具,形成MPEG-4 HE-AAC 2004年MPEG-4 HE-AAC引入PS(Parametric Stereo)模块,提升低码率性能,形成EAAC+ 技术指标 采样率:8kHz - 96kHz 码率: 8kbps - 576kbps 声道:最多支持48个主声道,16个低频增强声道 AAC 作为 MP3 的后继者而被设计出来,综合了许多新的技术,有很多新的特性,它支持从 8k 到 96k 的各种采样率,支持多种声道配置方案。在相同的比特率之下,AAC 相较于 MP3 通常可以达到更好的声音质量。 AAC 属于感知音频编码。与所有感知音频编码类似,其原理是利用人耳听觉的掩蔽效应,对变换域中的谱线进行编码,去除将被掩蔽的信息,并控制编码时的量化噪声不被分辨。 2、AAC编解码模块介绍MPEG-2 AAC 系统包含了增益控制、滤波器组、心理声学模型、量化与编码、预测、TNS、立体声处理等多种高效的编码工具。这些模块或过程的有机组合形成了 AAC 系统的基本编解码流程。 在实际应用中,并不是所有的功能模块都是必需的,下表列出了 MPEG-2 AAC 各模块的可选性: 相较于MPEG-2 AAC,MPEG-4 标准在原 AAC 的基础上加上了 LTP(Long Term Prediction)、PNS(Perceptual Noise Substitution)、SBR(Spectral Band Replication)、PS(Parametric Stereo)等技术,并提供了多种扩展工具。 为了允许其系统可对音频质量与内存/处理功率要求之间做一舍取,因此AAC 系统提供了三种profiles:Main profile、Low Complexity(LC) profile、Scaleable Sampling Rate(SSR) profile。且每一种profile所使用的tools皆不同,下表表示其三种不同profile所需使用的tools。 MPEG-4 AAC编码流程如下图: 送至听觉心里模型(Psychoacoustic Model)以求得信掩比,掩蔽阈值,M/S 立体声编码以及强度立体声编码需要的控制信息,还有滤波器组中应使用长短窗选择信息。 2:增益控制(gain control)同时送到增益控制(gain control)模块中,将信号做某个程度的衰减,以降低其峰值大小,如此可减少Pre-echo 的发生。 3:MDCT通过滤波器组(进行加窗 MDCT 变换,)将时域信号转换至频率域。 4:瞬时噪声整形TNS(Temporal Noise Shaping Module)瞬时噪声整形TNS(Temporal Noise Shaping Module)模块中,来判断是否需要启动TNS,此模块系利用开回路预测(open-loop prediction) 来修饰其量化噪声,如此可将其量化噪声的分布,修饰到原始信号能量所能含盖的范围之下,进一步的减少Pre-echo 的发生,若TNS 被启动,则传出其预测差值;反之,则传出原始频谱值。 5:Joint Stereo Coding与预测(Prediction)模块Joint Stereo Coding与预测(Prediction)模块来进一步消除信号间的冗余成份。在Joint Stereo Coding中又可分为Intensity Stereo Coding 与M/S Stereo Coding。在Intensity Stereo Coding模块中,是利用信号在高频时,人耳只对能量较敏感,对于其相位不敏感之特性,将其左右声道之频谱系数合并,以节省使用之位;在M/S Stereo Coding 模块中,利用左右声道之和与差,做进一步地压缩,若其差值能量很小,如此便可以用较少之位编码此一声道,将剩余之位应用于另一声道上的编码,如此来提升其压缩率。而预测模块的主要架构是使用Backward Adaptive Predictors,利用前两个音频帧来预测现在的音频帧,若决定启动此模块,则传出其预测差值,如此一来可以减少其数据量,达数据压缩之目的。 6:量化与编码量化与编码,为了达到量化编码的最佳化,AAC 使用了双巢状式循环(two nested loop)的量化编码结构,以得最佳的压缩质量。 4、AAC解码流程MPEG-4 AAC解码流程图如下图: 在解码时,该模块将 AAC 数据流分解为各个工具模块对应的数据模块,并为每个工具模块提供与该工具相关的比特流数据信息。这个模块的输出包括: 无噪声编码频谱的分段信息 无噪声编码频谱 Mid/Side 决策信息 预测器状态信息 强度立体声控制信息和耦合通道控制信息 时域噪声修整(TNS)信息 滤波器组控制信息 增益控制信息 2)Noiseless Decoding,无噪编解码模块。无噪编码就是哈夫曼编码,它的作用在于进一步减少尺度因子和量化后频谱的冗余,即将尺度因子和量化后的频谱信息进行哈夫曼编码。在解码时,该模块从码流解析模块获得输入的数据流,从中解码霍夫曼编码数据,并重建量化频谱、霍夫曼编码和 DPCM 编码的比例因子。 这个模块的输入包括: 无噪声编码频谱的分段信息 无噪声编码频谱 输出包括: 比例因子的解码整数表示 频谱的量化值 3)Inverse Quantization,量化和反量化模块。在 AAC 编码中,逆量化频谱系数是由一个非均匀量化器来实现的,在解码中需进行其逆运算。在解码时,该模块将频谱的量化值转换为整数值来表示未缩放的重建频谱。此量化器是非均匀的量化器。通过对量化分析的良好控制,比特率能够被更高效地利用。在频域调整量化噪声的基本方法就是用尺度因子来进行噪声整形,尺度因子就是一个用来改变在一个尺度因子带的所有的频谱系数的振幅增益值,使用尺度因子这种机制是为了使用非均匀量化器在频域中改变量化噪声的比特分配。 这个模块的输入包括: 频谱的量化值 输出包括: 未缩放的,逆量化的频谱 量化公式如下: x_quant = int (( abs( mdct_line ) * (2^(- ¼ * (sf_decoder - SF_OFFSET))) )^(3/4) + MAGIC_NUMBER) 其中MAGIC_NUMBER=0.4054,SF_OFFSET = 100 4)Rescaling,缩放因子处理模块。解码时,该模块将比例因子的整数表示转换为实际值,然后将未缩放的逆量化频谱乘以相关比例因子。 这个模块的输入包括: 比例因子的解码整数表示 未缩放的,逆量化的频谱 输出包括: 缩放后的逆量化的频谱 5)M/S,Mid/Side 立体声编解码模块。是联合立体声编码(Joint Stereo)的一种方案,编码时兼顾了这两个声道的共同信息量。该模块基于 Mid/Side 决策信息将频谱对从 Mid/Side 模式转换为 Left/Right 模式,以提高编码效率。一般在左右声道信息相似度较高时使用,处理方式是将左右声道信息合并(L+R)得到新的一轨,再将左右声道信息相减(L-R)得到另外一轨,然后再将这两轨信息用心理声学模型和滤波器处理。 这个模块的输入包括: Mid/Side 决策信息 和声道关联的缩放后的逆量化的频谱 输出包括: 在 M/S 解码之后,与声道对相关的缩放后的逆量化频谱 6)Prediction,预测模块。解码时,该模块会在预测状态信息的控制下重新插入在编码时提取出的冗余信息。该模块实现为二阶后向自适应预测器。对音频信号进行预测可以减少重复冗余信号的处理,提高效率。 这个模块的输入包括: 预测器状态信息 缩放后的逆量化的频谱 输出包括: 应用了预测的缩放后的逆量化的频谱 7)Intensity,强度立体声编解码模块。是联合立体声编码(Joint Stereo)的一种方案,编码时兼顾了这两个声道的共同信息量。一般在低流量时使用,利用了人耳对于低频信号指向性分辨能力的不足,将音频信息中的低频分解出来合成单声道数据,剩余的高频信息则合成另一个单声道数据,并记录高频信息的位置数据来重建立体声效果。解码时,该模块对频谱对执行强度立体声解码。Mid/Side Stereo 和 Intensity Stereo 都有利用部分相位信息的损失来换得较高的音色数据信息。 这个模块的输入包括: 逆量化的频谱 强度立体声控制信息 输出包括: 强度立体声道解码后的逆量化频谱 8)Dependently Switched Coupling,非独立交换耦合模块。解码时,该模块基于耦合控制信息的指导,将非独立交换耦合声道中的相关数据添加到频谱中。 这个模块的输入包括: 逆量化的频谱 耦合控制信息 输出包括: 和非独立交换耦合声道耦合的逆量化频谱 9)TNS,瞬时噪音整形模块。该模块实现了对编码噪声的精细时间结构的控制。在编码时,TNS 处理过程会修整声音信号的时域包络。在解码时,该模块会基于 TNS 信息的控制,在对应的逆处理过程中会还原实际的时域包络。这是通过对部分频谱数据进行滤波处理来实现的。这项神奇的技术可以通过在频率域上的预测,来修整时域上的量化噪音的分布。在一些特殊的语音和剧烈变化信号的量化上,TNS 技术对音质的提高贡献巨大。 这个模块的输入包括: 逆量化的频谱 TNS 信息 输出包括: 逆量化的频谱 10)Filterbank/Block Switching,滤波器组/块切换模块。解码时,该模块应用了在编码器中执行的频率映射的逆函数。滤波器组工具使用了一个逆修正离散余弦变换(IMDCT),这个 IMDCT 可以配置为支持一组 128 或 1024,或四组 32 或 256 频谱系数。 这个模块的输入包括: 逆量化的频谱 滤波器组控制信息 输出包括: 时域重建的音频信号 IMDCT公式如下: 当输出时,该模块将单独的时域增益控制应用于已由编码器中的增益控制 PQF 滤波器组创建的 4 个频带中的每个频带。然后,它会组合 4 个频带,并通过增益控制工具的滤波器组来重建时间波形。该模块仅可用于 SSR(Scalable SampleRate) Profile。 这个模块的输入包括: 时域重建的音频信号 增益控制信息 输出包括: 时域重建的音频信号 12)Independently Switched Coupling,独立交换耦合模块。解码时,该模块基于耦合控制信息的指导,将独立交换耦合声道中的相关数据添加到时间信号中。 这个模块的输入包括: 滤波器组输出的时间信号 耦合控制信息 输出包括: 和独立交换耦合声道耦合的时间信号 以上是 MPEG-2 AAC 各模块的介绍,在 MPEG-4 AAC 还新增了其他功能模块,比如: 1)LTP(Long Term Prediction),长时预测模块。它用来减少连续两个编码音框之间的信号冗余,对于处理低码率的语音非常有效。 2)PNS(Perceptual Noise Substitution),知觉噪声替换模块。当编码器发现类似噪音的信号时,并不对其进行量化,而是作个标记就忽略过去,当解码时再还原出来,这样就提高了效率。在具体操作上,PNS 模块对每个尺度因子带侦测频率 4k Hz 以下的信号成分。如果这个信号既不是音调,在时间上也无强烈的能量变动,就被认为是噪声信号。其信号的音调及能量变化都在心理声学模型中算出。 3)SBR(Spectral Band Replication),频段复制技术。音乐的主要频谱集中在低频段,高频段幅度很小,但很重要,决定了音质。对整个频段编码时,若为保护高频就会造成低频段编码过细导致编码效率较低;若只保存低频的主要成分而丢掉高频成分又会损失音质。SBR 把频谱切开,低频单独编码只保存主要成分,提高编码效率;高频单独放大编码,兼顾音质。 4)PS(Parametric Stereo),参数立体声技术。原本立体声双声道的编码输出是一个声道的两倍,但是两个声道的声音存在某种相似性。PS 存储一个声道的全部信息,然后花较少的字节用参数描述另一个声道的差异部分来提升编码效率。 参考资料[1]:ISO/IEC 13818-7 http://www.telemidia.puc-rio.br/~rafaeldiniz/public_files/normas/ISO-13818/ISO_IEC_13818-7_2006(E).pdf [2]:ISO/IEC 14496-3 https://csclub.uwaterloo.ca/~ehashman/ISO14496-3-2009.pdf [3]:音频编码:入门看这篇就够了丨音视频基础 https://zhuanlan.zhihu.com/p/499760382?utm_id=0 [4]:aac解码算法原理详解 https://www.doc88.com/p-5754123606296.html [5]:AAC 系统算法分析 https://www.cnblogs.com/gaozehua/archive/2012/05/03/2479960.html |
 其整体AAC 编解码系统,如图所示,其编码流程概述如下:
其整体AAC 编解码系统,如图所示,其编码流程概述如下: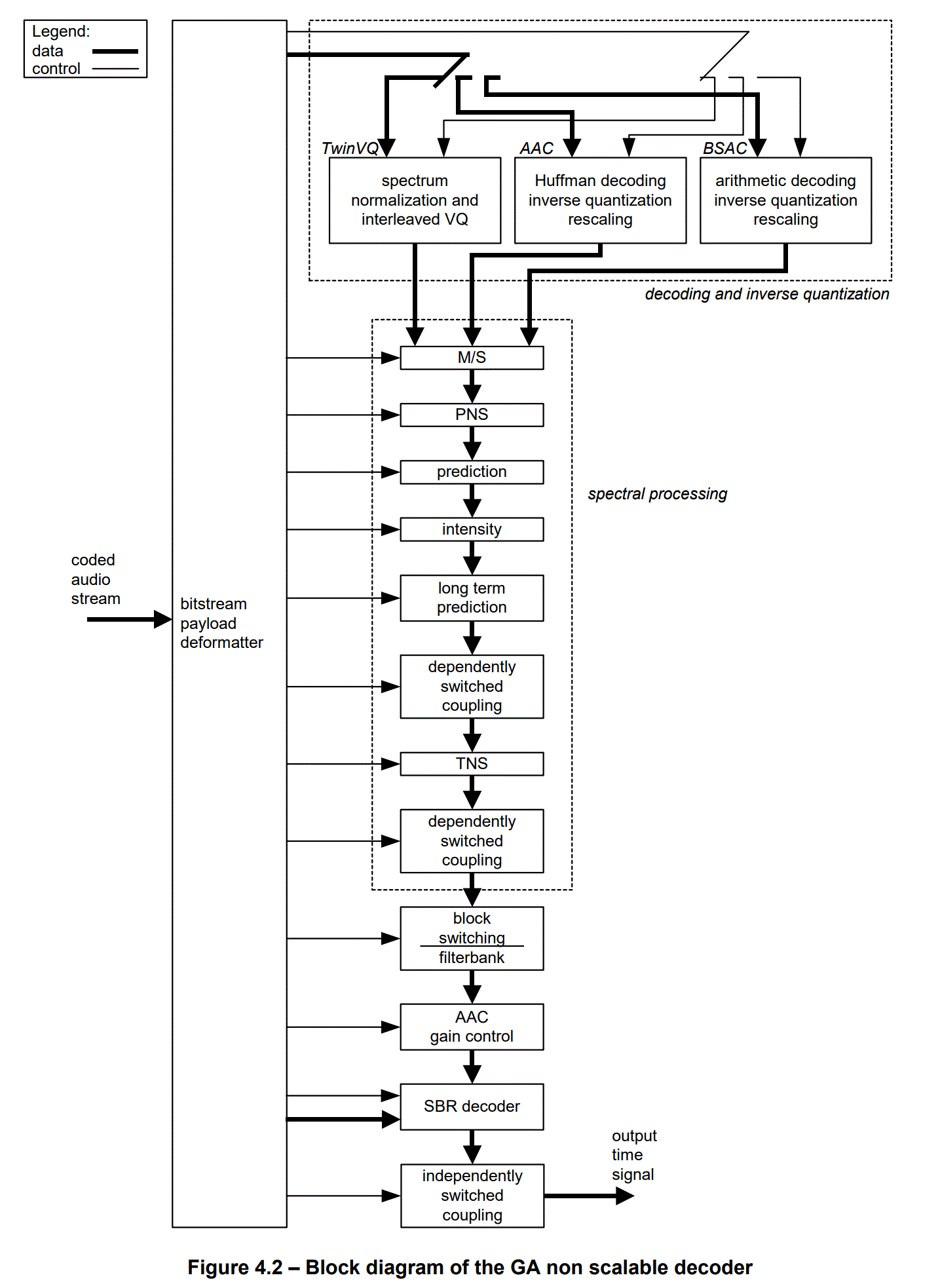
 因为aac每帧1024或960个samples,window length有50%的重叠,所以window length为2048或1920。window分long,short,具体如下:
因为aac每帧1024或960个samples,window length有50%的重叠,所以window length为2048或1920。window分long,short,具体如下: 
【本文地址】