|
HashCode的意义和作用
HashCode的介绍
哈希码是按照某种规则生成的int类型的数值
哈希码并不是完全唯一的。
让同一个类的对象按照自己不同的特征尽量的有不同的哈希码,但不是说不同的对象哈希码就一定不同,也有相同的情况。
首先我们需要了解hashCode方法和equals方法两个重要的规范:
规范1
若重写了某个类的equals方法,请一定重写hashCode方法,要能保证通过equals方法判断为true的两个对象,其hashCode方法的返回值相等,换句话说,就是要保证”两个对象相等,其hashCode一定相同”始终成立;
规范2
若equals方法返回false,即两个对象不相等,并不要求这两个对象的hashCode得到不同的数;
在这些规范下才能得到如下推论:
两个对象相等,其HashCode一定相同;
两个对象不相等,其HashCode有可能相同;
HashCode相同的两个对象,不一定相等;
HashCode不相同的两个对象,一定不相等;
关于第四条推论,有人可能会举出反例:两个类的hashCode方法故意返回不同的值,其对应的equals方法始终返回true,但这意味他们生成的对象和其他任意对象均会相等,其次是违反了规范1,所以反例是无效的。
这个只是规范,违反并不会造成编译或运行时的错误,但会在存储一些集合中时造成潜在的bug,因为有些集合会首先根据hashCode来判断是否重复。
HashCode的意义
HashMap插入重复的key,HashSet插入重复的value,,其value会被覆盖掉,那么,就有一个问题,他们怎么来判断重复呢?假设数据量庞大,每次插入要进行的判断重复操作就会非常耗时。 据了解,他们判断两个对象是否相等的规则是:
1)首先判断两个对象的hashCode是否相等
如果不相等,认为两个对象也不相等,完毕
如果相等,转入2)
2)判断两个对象用equals运算是否相等
如果不相等,认为两个对象也不相等
如果相等,认为两个对象相等(equals()是判断两个对象是否相等的关键)
由此判断方式可知,如果你违反了规范1,致使出现两个对象相等,但其hashCode不等的情况,这些集合会认为是两个不同对象,从而不会覆盖,造成问题;
就HashMap而言,对于键值对
HashCode的作用
下面将以HashMap为例说明HashCode的作用:根据资料可知,HashMap的数据结构为“链表+数组”形式: 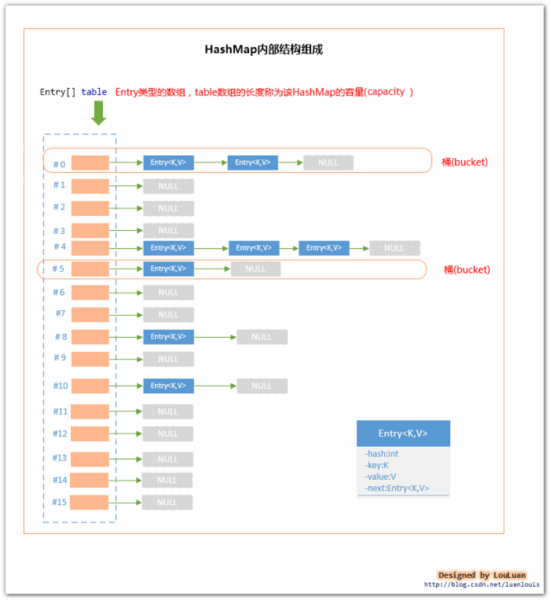
/**
* 这是HashMap中的put方法
* 将放入HashMap中,若key值已存在,则返回被替换的value,允许key,value为null
*
* @param key
* the key.
* @param value
* the value.
* @return 被替换的value
*/
@Override
public V put(K key, V value) {
//对key为null进行处理
if (key == null) {
return putValueForNullKey(value);
}
/**Collections.secondaryHash(key)
* 实际调用了Collections.secondaryHash(key.hashCode())
* 可以说明,此处是拿到key的hashCode值然后进行了二次hash,
* 得到一个新的hash值
* */
int hash = Collections.secondaryHash(key);
HashMapEntry[] tab = table;
//通过hash值来计算应该被分配到哪个桶,获取桶的索引
int index = hash & (tab.length - 1);
//遍历当前桶中的链表
for (HashMapEntry e = tab[index]; e != null; e = e.next) {
/**如果是放到同一个桶,则index值肯定相同,但这并不能说明hash值是相等的
* 所以判断对象相等,要先判断对象持有的hash值与计算得到的hash值是否相等,
* 再比较key是否相等,若均相等,则进行替换操作
***/
if (e.hash == hash && key.equals(e.key)) {
preModify(e);
V oldValue = e.value;
e.value = value;
return oldValue;
}
}
// No entry for (non-null) key is present; create one
modCount++;
//这是扩大容量的判断
if (size++ > threshold) {
tab = doubleCapacity();
index = hash & (tab.length - 1);
}
//若没有重复,创建一个新的HashMapEntry并将其放在桶的头部
addNewEntry(key, value, hash, index);
return null;
}
//这是对key为null进行处理
private V putValueForNullKey(V value) {
HashMapEntry entry = entryForNullKey;
if (entry == null) {
addNewEntryForNullKey(value);
size++;
modCount++;
return null;
} else {
preModify(entry);
V oldValue = entry.value;
entry.value = value;
return oldValue;
}
}
public static int secondaryHash(Object key) {
return secondaryHash(key.hashCode());
}
//二次散列操作
private static int secondaryHash(int h) {
// Spread bits to regularize both segment and index locations,
// using variant of single-word Wang/Jenkins hash.
h += (h >> 10);
h += (h >> 6);
h += (h > 16);
}
总结如下: HashMap每一次插入操作,首先对key值为null的情况进行处理,不为null的话,则对key的hashCode进行二次散列得到一个新的hash值, 对此hash进行计算来判断能装进哪个桶,得到桶的索引,再去遍历此桶中的链表,比较对象所持有的hash值与得到的hash值是否相等以及对象的key与所给的key是否相等,均相等,则说明为同一对象,则进行替换操作,若不相等,则说明不为同一对象,则在对应桶的位置增加,且是放在头部;
|