| python网络爬虫爬取vip电影 | 您所在的位置:网站首页 › 通过cookie解析vip › python网络爬虫爬取vip电影 |
python网络爬虫爬取vip电影
|
基于python实现的vip电影爬虫
序言:关于我CSDN连发五次文章都失败并且封号一天警告,一怒之下转博客园发现新大陆这件事。。。。 这篇文章的由来,是我为了一个月内看的三部电影,充了三个网站的会员之后,痛定思痛,决定再也不干这种傻事了,于是乎,我拿起了python—号称除了生孩子什么都能干的工具。 遗憾的是,在阅遍了CSDN,B站,知乎,博客园之后,并没有任何一个网站可以解决我的问题,尤其是我最依赖的CSDN,要么就是压根不能实践的方法,要么就是很老已经不能用的方法,滥竽充数和浑水摸鱼的文章浪费了大量的时间,只能说csdn的知识保护意识很强吧,现在但凡有一点擦边都不让发布。 由于解析电影的网站不同,衍生出了数种不同的爬虫思路,变化性较大,加之解析网站变动较大,这也是在各大资源网站都找不到有用的获取vip视频的教程的原因之一。 郑重声明:该文章仅供参考学习,他人不得利用非法手段牟利。 目录:
First and foremost:
电影资源常见解析类型
一.直接解析,另存为保存到本地(简单暴力下载)
小白食用,极度舒适。
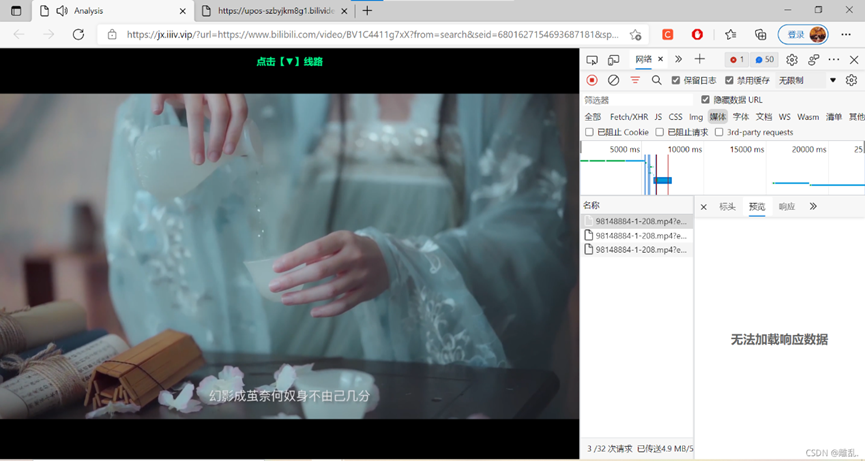
二.可直接抓包的电影
比较简单的抓包
三.无加密的m3u8格式电影
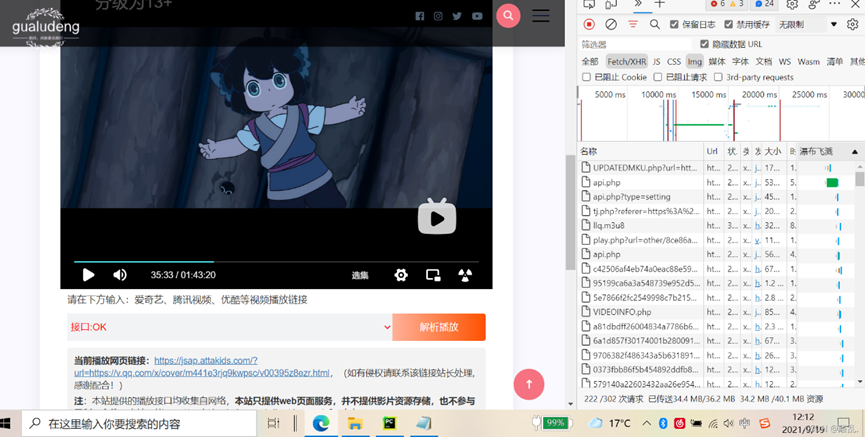
第一步,打开右键打开检查,在network(网络)里找到m3u8文件
第二步,通过m3u8文件下载每一个小的ts文件,并完成合并
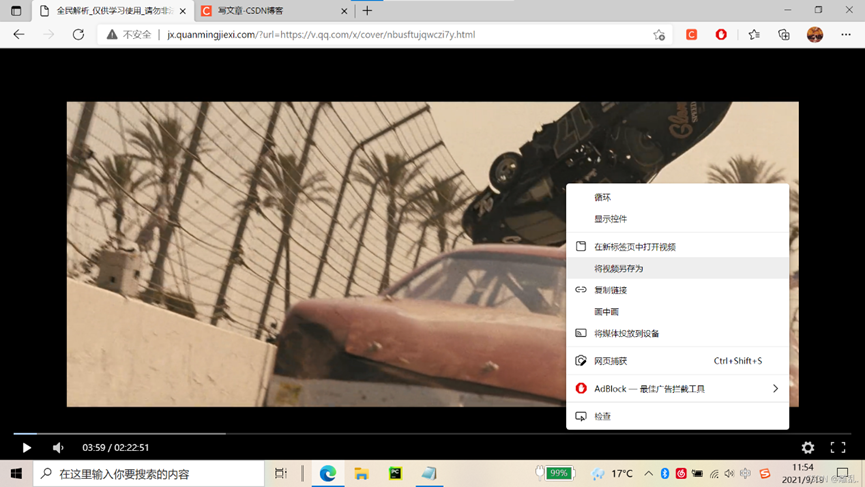
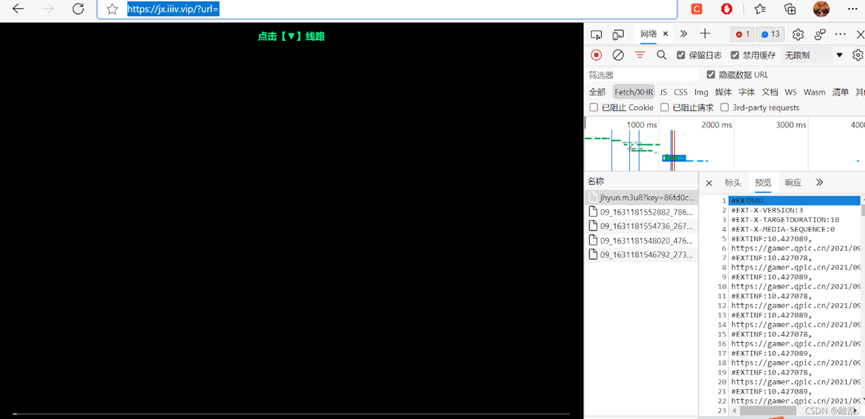
四.AES加密的的m3u8文件 基于第三种的基础,这里多了一个加密格式 first.我们需要下载每一的目录(m3u8文件) second.我们需要从目录里提取AES秘钥和每个ts网址(正则) last.用得到的秘钥解密每一个ts文件,开启多线程下载并合并文件 First and foremost: 本文文字叙述只是整理思路,辅助理解,真正的灵魂在代码,一定要认真看代码。 影视资源常见解析类型 适用人群: 1.纯小白,就是想白嫖电影的 2.初学者,emmm。。至少要会个requests和基本语法吧 3.较为高级一点的初学者,os,requests,time,基础re,基础concurrent,基础AES(为什么都是基础?因为我就这水平。。。。) 4.大佬(反正除了123就直接统称为大佬。。。鼠?) 一.直接解析,另存为保存到本地(简单暴力下载) 小白食用,极度舒适。 最简单没有之一的一种获取视频的方法,非常的香,无基础畅享! 解析地址https://jx.iiiv.vip/?url= 此网站实用于腾讯视频,爱奇艺,优酷,B站(非大会员)的解析观影 其中,腾讯视频直接鼠标两次右键另存为下载到本地。(注意格式是mp4,不是html) 而除了腾讯视频其他的视频平台则不能直接右键下载。另,此网站不能直接抓包。 二.可直接抓包的电影 这个是仅次于(一)的简单,打开检查,选中media(媒体),然后解析播放(切记顺序不要乱),就会刷新出文件,双击点开文件,进入视频界面,直接下载。大电影用的比较少,下载也不慢,不妨一试。 呃,比如b站视频不能直接下载嘛不是,直接抓包就完了。 解析地址选用:90偶尔 - QQ群:1265608 (iiiv.vip)(非常好用)
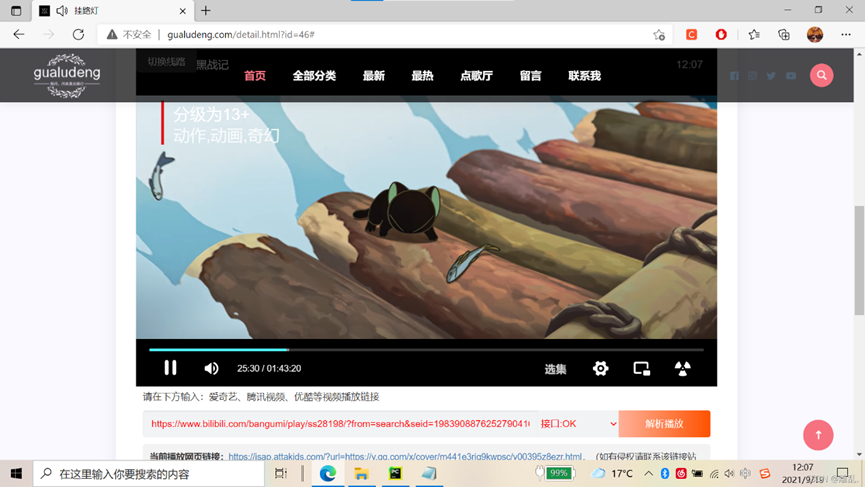
三.无加密的m3u8格式电影 所用到模块:requests,os,time,concurrent(不必须) 最近在看罗小黑战记(时隔七年终于更新了),然鹅,居然只有某站大会员才能看,本着能白嫖绝不三连,呸,花钱,的思想,我找到了一个可以解析某站会员视频的网站: 解析地址挂路灯 (gualudeng.com) 顺便推荐这个很好地网站,里面东西非常多。(我当时用的时候还好好的,时隔半年,它现在要关注微信公众号才能顺利使用了·····,顺便一提,现在大多数资源都要关注公众号,而且理由都是恶意爬虫、恶意盗用接口等等,也不知道真的还是想恰个饭。。。。) 选择OK接口(当时了,现在不行的话随机应变自己找找吧)
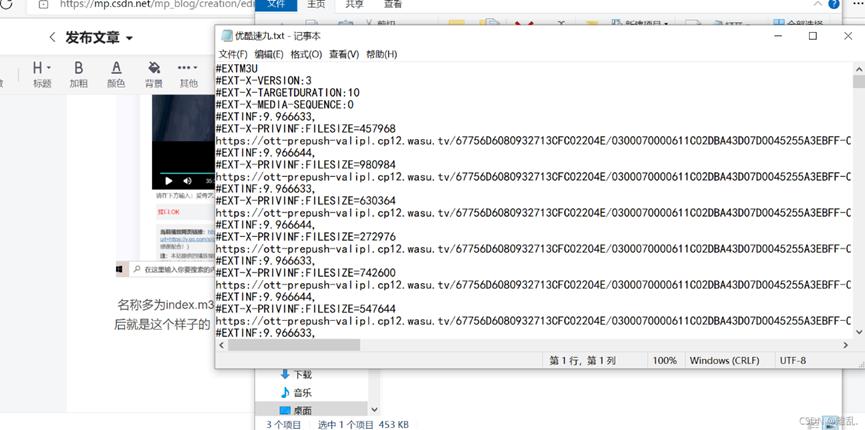
此时就可以观看该电影,嗯,用过的应该知道,m3u8格式的视频不在大网站上的话,非常容易卡,十分影响观影体验,于是我们选择下载电影。那么,重点就来了。 对于m3u8格式,简单来说就是将一个大视频(几个小时)切割成上千个小的视频片段,后缀为ts,可以跟正常的MP4一样播放。然后你看视频的时候就一个个片段渲染,更详细的可以直接在CSDN或者百度搜搜,这里不赘述(其实是我也没有深入了解嘿嘿嘿)。 所以我们的思路就是: 0.在解析网站中获取m3u8文件(or php) 1.把所有的网址提取出来,剔除‘#’开头的没用数据 2.遍历获取每一个视频片段 3.然后将所有的视频片段合并成一个大的电影文件 4.删除下载的每一个视频片段 #补充 5.编写一个下载ts片段的函数,用于开创线程池,加快速度 6.下载过程可能会失败,所以一定要设置最长get时间,并且限定次数防止由于资源问题程序卡死 都是血与泪教训,一步一步探索出来的东西。 第一步,打开右键打开检查,在network(网络)里找到m3u8文件 打开检查,选中XHR,然后解析播放(切记顺序不要乱),就会刷新出许多文件 名称多为index.m3u8,没有的话就找后缀为m3u8的文件双击,就会下载到本地一个文档,打开之后就是这个样子的
大概有两千多行吧。。。。 嗯,这个文件能看到许多的https网址,就是每一个视频片段,ts格式的。 第二步,编写python代码 ok,思路清晰了以后,就开始编写代码了。话不多说上代码(也不算长) #导入模块 import requests import os import time from concurrent.futures import ThreadPoolExecutor start = time.time() #准备下载路径 m3u8 = [] with open('play.php','r') as file: lst = file.readlines() for i in lst: i = i.strip() if i.startswith('#'): continue else: m3u8.append(i) print(f'目标文件数共{len(m3u8)}个') #下载一个ts文件的函数 def download_ts(i): for _ in range(10): try: with open(f'{i}.ts','wb') as file: resp = requests.get(m3u8[i],timeout=15).content file.write(resp) print(f'第{i}个ts片段已下载完成!') break except: print(f'第{i}个ts文件下载失败,重新下载!') continue with ThreadPoolExecutor(100) as t: for i in range(len(m3u8)): t.submit(download_ts,i) t.shutdown() #补录程序 with ThreadPoolExecutor(50) as f: for i in range(len(m3u8)): with open(f'{i}.ts','rb+') as file: if file.read(): continue else: f.submit(download_ts,i) f.shutdown() print('ts文件下载完毕') #ts文件的合并 print('ts文件开始合并....') with open('罗小黑战记.mp4','wb') as file: for i in range(len(m3u8)): with open(f'{i}.ts','rb') as f: f_view = f.read() file.write(f_view) print('ts文件合并完毕!') #ts文件的删除操作 print('开始删除ts文件....') for i in range(len(m3u8)): try: os.remove(rf'C:\Users\我的电脑\Desktop\python学习\python爬虫项目\vip电影全解\罗小黑战记番剧\{i}.ts') except FileNotFoundError: continue print('ts文件删除完毕!') print('电影完美下载!') end = time.time() print('本次下载共耗时长:',end-start,'s')headers是反爬,在这里不加也没有影上面的程序开了线程池(ThreadPoolExecutor),所以一部电影三分钟就能下载下来,不开的话就非常的慢,遍历下载得一个多小时才行。 另外,由于网络爬虫可能存在各种错误,所以在downlaod函数和后续删除ts片段中都用try-except捕获异常,并且开了一个线程池做补录,下载第一次未能顺利下载下来的内容。 time模块用来反馈下载电影所用时间,也可以不用。 在XHR里找m3u8,预览里一般都可以看到上千行的网址,如上图。 四.AES加密的的m3u8文件 所用到的模块:requests,re,AES,os,time,concurrent(非必须) 比较进阶一点的爬虫的(真的就是一点点) 在(三)中,我们学会了如何下载m3u8格式的视频,但并非所有的m3u8都是那么的纯洁,有些网站非常的狗,对文件设置了加密(我只见过AES加密的,but据说有其他加密模式反正我没见到),所以这里我们只讨论如何解决有AES加密的视频。 1.首先,我们需要判断是否有加密 2.其次,既然是加密,我们就需要秘钥(key),获取他 3.通过秘钥(key)来解析获取ts文件 #其实就是比(二)多了个解密模块嘛 我们这里选取B站会员(最难处理的就它了,傲娇的要死)的罗小黑战记(37-40集),作为范例。 first.我们需要下载每一集的目录(m3u8文件) 按照(三)中的方法下载就完了。 b站大会员选ok接口 (很显然,现如今如果变动了的话随机应变都是可以解决的) #导入模块 import requests import os from Crypto.Cipher import AES #AES解密模块 import time from concurrent.futures import ThreadPoolExecutor import re start = time.time() #准备下载路径 headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64' 'AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.131 Safari/537.36 Edg/92.0.902.73'} def download_ts(i): for _ in range(10): try: with open(f'{i}.ts', 'wb') as file: response = requests.get(m3u8[i], headers=headers, timeout=15).content cryptor = AES.new(key, AES.MODE_CBC, key) file.write(cryptor.decrypt(response)) print(f'第{i}个ts片段已下载完成!') break except: print(f'第{i}个ts文件下载失败,重新下载!') continue for _ in range(4): m3u8=[] with open(f'index ({_+7}).m3u8','r+',encoding='utf-8') as file: r = file.read() obj = re.compile(r'URI="(?P.*?)"',re.S) keyurlx = obj.finditer(r) for x in keyurlx: keyurl = x.group('url') file.seek(0,0) lst = file.readlines() for i in lst: i = i.strip() if i.startswith('#'): continue else: m3u8.append(i) print(f'目标文件数共{len(m3u8)}个') respn = requests.get(keyurl,headers=headers) key = respn.text.encode('utf-8') with ThreadPoolExecutor(100) as t: for i in range(len(m3u8)): t.submit(download_ts,i) t.shutdown() #补录程序 with ThreadPoolExecutor(50) as f: for i in range(len(m3u8)): with open(f'{i}.ts','rb+') as file: if file.read(): continue else: f.submit(download_ts,i) f.shutdown() print('ts文件下载完毕') #ts文件的合并 print('ts文件开始合并....') with open(f'实验vip电影{_}.mp4','wb') as file: for i in range(len(m3u8)): with open(f'{i}.ts','rb') as f: f_view = f.read() file.write(f_view) print('ts文件合并完毕!') #ts文件的删除操作 print('开始删除ts文件....') for i in range(len(m3u8)): try: os.remove(rf'C:\Users\我的电脑\Desktop\python学习\python爬虫项目\vip电影全解\罗小黑战记番剧\{i}.ts') except FileNotFoundError: continue print('ts文件删除完毕!') print('电影完美下载!') end = time.time() print('本次下载共耗时长:',end-start,'s') #很显然,除了一下下载几集之外,唯一的不同点就是解密,直接套用解密模板就行了。 response = requests.get(m3u8[i], headers=headers, timeout=15).content cryptor = AES.new(key, AES.MODE_CBC, key) file.write(cryptor.decrypt(response))就像这样。 由于这个是几集,所以key我们选择从下载的m3u8文件里提取,这里就用到了一点点的re(正则表达式)内容,当然也可以手动提取粘贴到代码里,就是对于好几集的剧来说太麻烦了。不过正则在提取每个ts文件网址的时候还是要用的。emmm除非你跟我一样精,调用字符串startswich函数。。。。 key获取之后一定要编码成utf-8的格式,要不然程序会报错(python这个笨逼他读不懂其他编码格式的数据) 上述的四种方法,一般来讲前三种就能解决大多数视频了,并且都不难,就是遇到哪种情况就用对应的方法解决就完了。 |

【本文地址】