| 《机器学习实战》 | 您所在的位置:网站首页 › 递归树状图python › 《机器学习实战》 |
《机器学习实战》
|
目录决策树决策树简介决策树的构造信息增益划分数据集递归构建决策树在 Python 中使用 Matplotlib 注解绘制树形图Matplotlib 注解构造注解树测试和存储分类器测试算法:使用决策树执行分类使用算法:决策树的存储示例:使用决策树预测隐形眼镜类型总结
决策树
决策树简介
在数据集中度量一致性
使用递归构造决策树
使用 Matplotlib 绘制树形图
决策树简介
让我们来玩一个游戏,你现在在你的脑海里想好某个事物,你的同桌向你提问,但是只允许问你20个问题,你的回答只能是对或错,如果你的同桌在问你20个问题之前说出了你脑海里的那个事物,则他赢,否则你赢。惩罚,你自己定咯。 决策树的工作原理就类似与我们这个游戏,用户输入一些列数据,然后给出游戏的答案。 决策树听起来很高大善,其实它的概念很简单。通过简单的流程就能理解其工作原理。 图3-1 决策树流程图
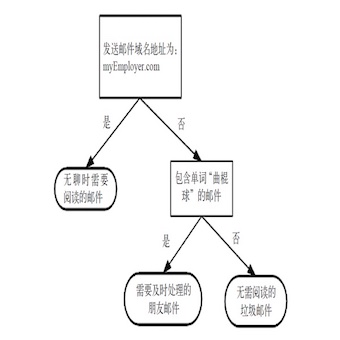
从图3-1我们可以看到一个流程图,他就是一个决策树。长方形代表判断模块,椭圆形代表终止模块,从判断模块引出的左右箭头称作分支。该流程图构造了一个假想的邮件分类系统,它首先检测发送邮件域名地址。如果地址为 myEmployer.com,则将其放在分类“无聊时需要阅读的邮件”;如果邮件不是来自这个域名,则检查邮件内容里是否包含单词 曲棍球 ,如果包含则将邮件归类到“需要及时处理的朋友邮件”;如果不包含则将邮件归类到“无需阅读的垃圾邮件”。 第二章我们已经介绍了 k-近邻算法完成很多分类问题,但是它无法给出数据的内在含义,而决策树的主要优势就在此,它的数据形式非常容易理解。 那如何去理解决策树的数据中所蕴含的信息呢?接下来我们就将学习如何从一堆原始数据中构造决策树。首先我们讨论构造决策树的方法,以及如何比那些构造树的 Python 代码;接着提出一些度量算法成功率的方法;最后使用递归建立分类器,并且使用 Matplotlib 绘制决策树图。构造完成决策树分类器之后,我们将输入一些隐形眼睛的处方数据,并由决策树分类器预测需要的镜片类型。 决策树的构造 优点: 计算复杂度不高,输出结果易于理解,对中间值的缺失不敏感,可以处理不相关特征数据。 缺点: 可能会产生过度匹配问题。在构造决策树的时候,我们将会遇到的第一个问题就是找到决定性的特征,划分出最好的结果,因此我们必须评估每个特征。 # 构建分支的伪代码函数 create_branch 检测数据集中的每个子项是否属于同一分类: if yes return 类标记 else 寻找划分数据集的最好特征 划分数据集 创建分直节点 for 每个划分的子集 调用函数 create_branch 并增加返回结果到分支节点 return 分支节点在构造 create_branch 方法之前,我们先来了解一下决策树的一般流程: 1. 收集数据: 可以使用任何方法 2. 准备数据: 树构造算法只适用于标称型数据,因此数值型数据必须离散化 3. 分析数据: 可以使用任何方法,构造树完成之后,我们应该检查图形是否符合预期 4. 训练算法: 构造树的数据结构 5. 测试算法: 使用经验树计算错误率 6. 使用算法: 此步骤可以适用于任何监督学习算法,而使用决策树可以更好的理解数据的内在含义一些决策树采用二分法划分数据,本书并不采用这种方法。如果依据某个属性划分数据将会产生4个可能的值,我们将把数据划分成四块,并创建四个不同的分支。本书将采用 ID3 算法划分数据集。*关于 ID3 算法的详细解释。* 表3-1 海洋生物数据 不浮出水面是否可以生存 是否有脚蹼 属于鱼类 1 是 是 是 2 是 是 是 3 是 否 否 4 否 是 否 5 否 是 否 信息增益划分大数据的大原则是:将无序的数据变得更加有序。其中组织杂乱无章数据的一种方法就是使用信息论度量信息。*信息论是量化处理信息的分支科学。*我们可以在划分数据之前或之后使用信息论量化度量信息的内容。其中在划分数据之前之后信息发生的变化称为信息增益,获得信息增益最高的特征就是最好的选择。 在数据划分之前,我们先介绍熵*也称作香农熵*。熵定义为信息的期望值,它是信息的一种度量方式。 信息——如果待分类的事务可能划分在多个分类之中,则符号\(x_i\)的信息定义为: \(l(x_i)=-log_2p(x_i)\) \(p(x_i)\)是选择该分类的概率 所有类别所有可能包含的信息期望值: \(H=-\sum_{i=1}^np(x_i)log_2p(x_i)\)n是分类的数目 对公式有一定的了解之后我们在 trees.py 文件中定义一个 calc_shannon_ent 方法来计算信息熵。 # trees.py from math import log def calc_shannon_ent(data_set): # 计算实例总数 num_entries = len(data_set) label_counts = {} # 统计所有类别出现的次数 for feat_vec in data_set: current_label = feat_vec[-1] if current_label not in label_counts.keys(): label_counts[current_label] = 0 label_counts[current_label] += 1 # 通过熵的公式计算香农熵 shannon_ent = 0 for key in label_counts: # 统计所有类别出现的概率 prob = float(label_counts[key] / num_entries) shannon_ent -= prob * log(prob, 2) return shannon_ent def create_data_set(): """构造我们之前对鱼鉴定的数据集""" data_set = [[1, 1, 'yes'], [1, 1, 'yes'], [1, 0, 'no'], [0, 1, 'no'], [0, 1, 'no']] labels = ['no surfacing', 'flippers'] return data_set, labels def shannon_run(): data_set, labels = create_data_set() shannon_ent = calc_shannon_ent(data_set) print(shannon_ent) # 0.9709505944546686 if __name__ == '__main__': shannon_run()混合的数据越多,则熵越高,有兴趣的同学可以试试增加一个 ’maybe’ 的标记。 如果还有兴趣的可以自行了解另一个度量集合无序程度的方法是基尼不纯度,简单地讲就是从一个数据集中随机选取子项,度量其被错误分类到其他分组里的概率。 划分数据集我们已经测量了信息熵,但是我们还需要划分数据集,度量划分数据集的熵,因此判断当前是否正确地划分数据集。*你可以想象一个二维空间,空间上随机分布的数据,我们现在需要在数据之间划一条线把它们分成两部分,那我们应该按照 x 轴还是 y 轴划线呢?* 因此我们可以定义一个 split_data_set 方法来解决上述所说的问题: # trees.py def split_data_set(data_set, axis, value): # 对符合规则的特征进行筛选 ret_data_set = [] for feat_vec in data_set: # 选取某个符合规则的特征 if feat_vec[axis] == value: # 如果符合特征则删掉符合规则的特征 reduced_feat_vec = feat_vec[:axis] reduced_feat_vec.extend(feat_vec[axis + 1:]) # 把符合规则的数据写入需要返回的列表中 ret_data_set.append(reduced_feat_vec) return ret_data_set def split_data_run(): my_data, labels = create_data_set() ret_data_set = split_data_set(my_data, 0, 1) print(ret_data_set) # [[1, 'yes'], [1, 'yes'], [0, 'no']] if __name__ == '__main__': # shannon_run() split_data_run()接下来我们把上述两个方法结合起来遍历整个数据集,找到最好的特征划分方式。 因此我们需要定义一个 choose_best_feature_to_split 方法来解决上述所说的问题: # trees.py def choose_best_feature_to_split(data_set): # 计算特征数量 num_features = len(data_set[0]) - 1 # 计算原始数据集的熵值 base_entropy = calc_shannon_ent(data_set) best_info_gain = 0 best_feature = -1 for i in range(num_features): feat_list = [example[i] for example in data_set] # 遍历某个特征下的所有特征值按照该特征的权重值计算某个特征的熵值 unique_vals = set(feat_list) new_entropy = 0 for value in unique_vals: sub_data_set = split_data_set(data_set, i, value) prob = len(sub_data_set) / float(len(data_set)) new_entropy += prob * calc_shannon_ent(sub_data_set) # 计算最好的信息增益 info_gain = base_entropy - new_entropy if info_gain > best_info_gain: best_info_gain = info_gain best_feature = i return best_feature def choose_best_feature_run(): data_set, _ = create_data_set() best_feature = choose_best_feature_to_split(data_set) print(best_feature) # 0 if __name__ == '__main__': # shannon_run() # split_data_run() choose_best_feature_run我们发现第0个*即第一个*特征是最好的用于划分数据集的特征。对照表3-1,我们可以发现如果我们以第一个特征划分,特征值为1的海洋生物分组将有两个属于鱼类,一个属于非鱼类;另一个分组则全部属于非鱼类。如果按照第二个特征划分……可以看出以第一个特征划分效果是较好于以第二个特征划分的。同学们也可以用 calc_shannon_entropy 方法测试不同特征分组的输出结果。 递归构建决策树我们已经介绍了构造决策树所需要的子功能模块,其工作原理如下:得到原始数据集,然后基于最好的属性值划分数据集,由于特征值可能多于两个,因此可能存在大于两个分支的数据集划分。第一次划分后,数据将被向下传递到树分支的下一个节点,在这个节点上,我们可以再次划分数据。因此我们采用递归的原则处理数据集。 递归结束的条件是:程序遍历完所有划分数据集的属性,或者每个分支下的所有实例都具有相同的分类。如果所有实例具有相同的分类,则得到一个叶子节点或者终止块。任何到达叶子节点的数据必然属于叶子节点的分类。如图3-2 所示: 图3-2 划分数据集时的数据路径
第一个结束条件使得算法可以终止,我们甚至可以设置算法可以划分的最大分组数目。后续章节会陆续介绍其他决策树算法,如 C4.5和 CART,这些算法在运行时并不总是在每次划分分组时都会消耗特征。由于特征数目并不是在每次划分数据分组时都减少,因此这些算法在实际使用时可能引起一定的问题。但目前我们并不需要考虑这个问题,我们只需要查看算法是否使用了所有属性即可。如果数据集已经处理了所有特征,但是该特征下的类标记依然不是唯一的,*可能类标记为是,也可能为否*,此时我们通常会采用多数表决的方法决定该叶子节点的分类。 因此我们可以定义一个 maority_cnt 方法来决定如何定义叶子节点: # trees.py def majority_cnt(class_list): """对 class_list 做分类处理,类似于 k-近邻算法的 classify0 方法""" import operator class_count = {} for vote in class_list: if vote not in class_count.keys(): class_count[vote] = 0 class_count[vote] += 1 sorted_class_count = sorted(class_count.items(), key=operator.itemgetter(1), reverse=True) return sorted_class_count[0][0]在定义处理叶子节点的方法之后,我们就开始用代码 create_tree 方法实现我们的整个流程: # trees.py def create_tree(data_set, labels): # 取出数据集中的标记信息 class_list = [example[-1] for example in data_set] # 如果数据集中的标记信息完全相同则结束递归 if class_list.count(class_list[0]) == len(class_list): return class_list[0] # TODO 补充解释 # 如果最后使用了所有的特征无法将数据集划分成仅包含唯一类别的分组 # 因此我们遍历完所有特征时返回出现次数最多的特征 if len(data_set[0]) == 1: return majority_cnt(class_list) # 通过计算熵值返回最适合划分的特征 best_feat = choose_best_feature_to_split(data_set) best_feat_label = labels[best_feat] my_tree = {best_feat_label: {}} del (labels[best_feat]) # 取出最合适特征对应的值并去重即找到该特征对应的所有可能的值 feat_values = [example[best_feat] for example in data_set] unique_vals = set(feat_values) # 遍历最适合特征对应的所有可能值,并且对这些可能值继续生成子树 # 类似于 choose_best_feature_to_split 方法 for value in unique_vals: sub_labels = labels[:] # 对符合该规则的特征继续生成子树 my_tree[best_feat_label][value] = create_tree(split_data_set(data_set, best_feat, value), sub_labels) return my_tree def create_tree_run(): my_dat, labels = create_data_set() my_tree = create_tree(my_dat, labels) print(my_tree) # {'no surfacing': {0: 'no', 1: {'flippers': {0: 'no', 1: 'yes'}}}} if __name__ == '__main__': # shannon_run() # split_data_run() # choose_best_feature_run() create_tree_run()我们已经手动为我们的流程生成了一个树结构的字典,第一个关键字 ‘no surfacing’ 是第一个划分数据集的特征名字,该关键字的值也是另一个数据字典。第二个关键字是 ‘no surfacing’ 特征划分的数据集,这些关键字的值是 ‘no surfacing’ 节点的子节点。如果值是类标签,则盖子节点是叶子节点;如果值是另一个数据字典,则子节点是一个判断节点,这种格式结构不断重复就狗策很难过了整棵树。 在 Python 中使用 Matplotlib 注解绘制树形图我们已经用代码实现了从数据集中创建树,但是返回的结果是字典,并不容易让人理解,但是决策树的主要优点是易于理解,因此我们将使用 Matplotlib 库创建树形图。 Matplotlib 注解Matplotlib 库提供了一个注解工具annotations,他可以在数据图形上添加文本注释。并且工具内嵌支持带箭头的划线工具。 因此我们创建一个 tree_plotter.py 的文件通过注解和箭头绘制树形图。 # tree_plotter.py import matplotlib.pyplot as plt from chinese_font import font # 定义文本框和箭头格式 decision_node = dict(boxstyle='sawtooth', fc='0.8') leaf_node = dict(boxstyle='round4', fc='0.8') arrow_args = dict(arrowstyle=' |

【本文地址】