| azw3 python数据分析 活用pandas库 | 您所在的位置:网站首页 › 车牌号被人故意折弯了咋办 › azw3 python数据分析 活用pandas库 |
azw3 python数据分析 活用pandas库
|
关于python基础,就不讲print、if、for、while循环、数据类型等特别基础的东西了,私信“python”获取我最最最喜欢的一本学习python基础的电子书,里面有非常详细的讲解,且通俗易懂。 本文将按照数据分析的步骤来讲述如何用pandas库读取和操作列表。 读取数据 import pandas as pd #导入pandas库df = pd.read_csv('文件名.csv') #读取列表df.head() #查看前5行
pd.read_csv用来读取csv格式文件。如果是excel格式,用pd.read_excel。txt格式用pd.read_table('文件名.txt', sep = ','),sep表示文件分隔符号,一般是逗号。 head()用来查看列表的前5行,如果想查看前10行可以用head(10)。查看后5行用tail()。 查询指定行列 loc和iloc都可以用来查询指定行列,不同在于iloc是用索引查询,loc是用索引标签查询。通过以下两个例子可以进行对比: df.iloc[:5,[3,1]]
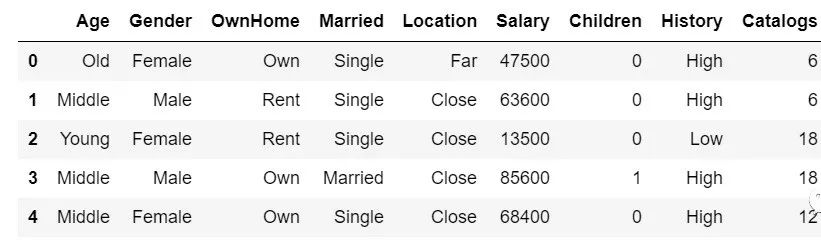
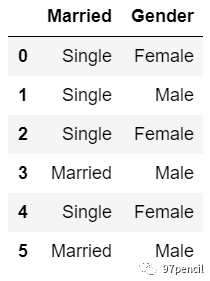
可以看到,iloc读取时:5代表的是前五行不包含索引5,而loc读取时:5是读取至索引5,是包含索引5的。 一般情况下用loc比较多,因为它可以用来进行条件筛选,比如我只想读取性别为女性的行: df.loc[df['Gender']=='Female',['Married','Gender']]
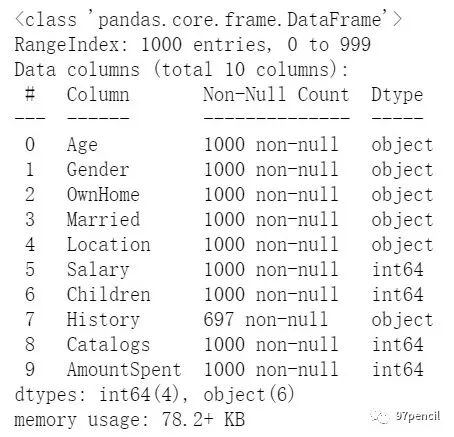
了解数据 df.info()
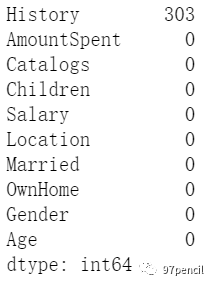
info()用来查看每个变量(每列为一个变量)的基本信息,包括非空值数量、数据类型。可以看到,在本数据列表中,只有“History”列是缺失的,也就是说存在缺失值。我们想知道“History”到底有几个缺失值,又懒得手动计算1000-697=303,就可以进行如下操作: df.isnull().sum().sort_values(ascending = False)
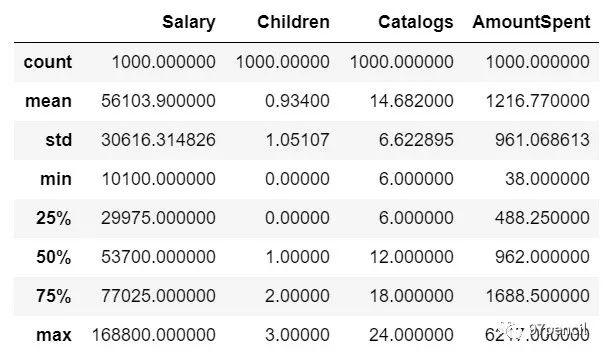
可见,使用isnull().sum()可以直接得到每个变量的缺失值数量。这里,sort_values是用来对数据进行排序的,默认是升序(ascending = True),这里ascending = False使数据降序。 数据描述统计 df.describe()
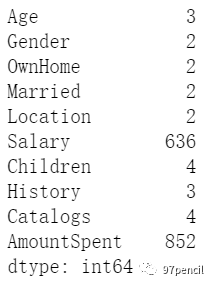
describe()用来查看数字型变量的描述统计信息,包括计数(count)、平均数(mean)、标准差(std)、最大值、最小值、中值等。如此一来我们对数据有个初步的了解,像工资这种如果最小值出现负数,那就是数据错误了,需要修正数据。 df['Salary'].var()当然我们也可以直接用sum()、min()、max()、std()、var()等来直接查看某变量的数据统计信息。如图通过var()可以得到工资的方差。 df.nunique()
nunique()可以用来查看每个变量的独特值数量。如图,“Age"有三个独特值。 df['Age'].value_counts().sort_index()
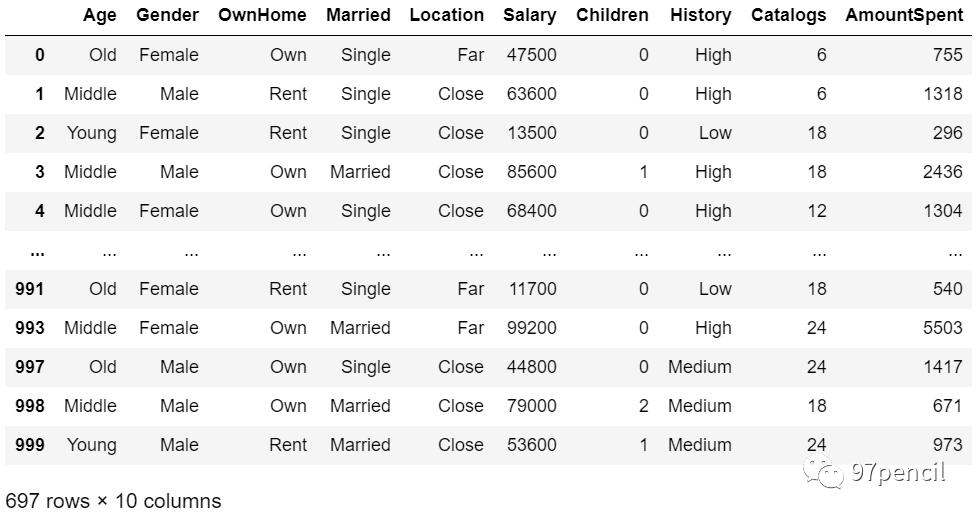
如果想知道”Age“里面的3个独特值分别是什么,以及每一个独特值的数量,可以用value_counts()如上图。可见,该数据将“Age"分为3类:Middle、Young、Old。其中Middle数量最多。sort_index()是按照索引排序(默认升序),这里是按首字母进行排序(A-Z)。 缺失值处理 对于缺失值,一般可采取两种处理方式:删除和填充。 df.dropna()
使用dropna()可以将有缺失值的行全部删除。如图,删除确实之后最终保留了697行。 填充一般可以选择用平均数、中值或众数进行填充。 df['History'] = df['History'].fillna(df['History'].mode()[0])这里通过fillna()用众数填充了“History”的缺失值。 |


【本文地址】