| 4D | 您所在的位置:网站首页 › 质谱dda › 4D |
4D
|
发表时间:2020.12 运用生物技术:DIA-PASEF 研究背景 传统的蛋白质组学采用数据依赖性采集(Data-dependent Acquisition, DDA)策略,特定的肽段信号被连续的选择并碎裂,产生二级质谱图(MS/MS)。这种采集方法偏向于获取高丰度肽段,导致缺失值的问题。与之相比,数据非依赖性采集(Data-independent Acquisition, DIA)技术将质谱整个扫描范围(m/z)分为若干个窗口,并循环地对每个窗口中的所有离子进行选择、碎裂、检测,因此可以无遗漏地获得样本中所有离子的全部碎片信息。但DIA技术的谱图复杂度对后续分析提出了巨大挑战。虽然较窄的隔离窗口会降低谱图复杂度,但这增加了窗口的总数,因此增加了覆盖整个质量范围所需的DIA循环时间。 在色谱和质谱中增加离子淌度分离可以提高灵敏度并降低谱图复杂度。TIMS(trapped ion mobility spectrometer)是一种离子淌度分析仪,其中离子在气流的推动下向前运动,将离子按大小和形状分开,在离子运动的反方向施加电场,阻滞离子的运动,将离子捕获在特定的位置,然后逐渐降低电场,将离子由大到小逐个释放。在TIMS-四极杆-TOF结构的系统中,离子淌度分离可以与四极杆质量选择同步,这种方法被称为平行累积连续碎裂(parallel accumulation–serial fragmentation, PASEF)。本文将PASEF原理扩展到DIA,这将结合DIA数据采集方法的优点和PASEF的固有效率。 实验思路
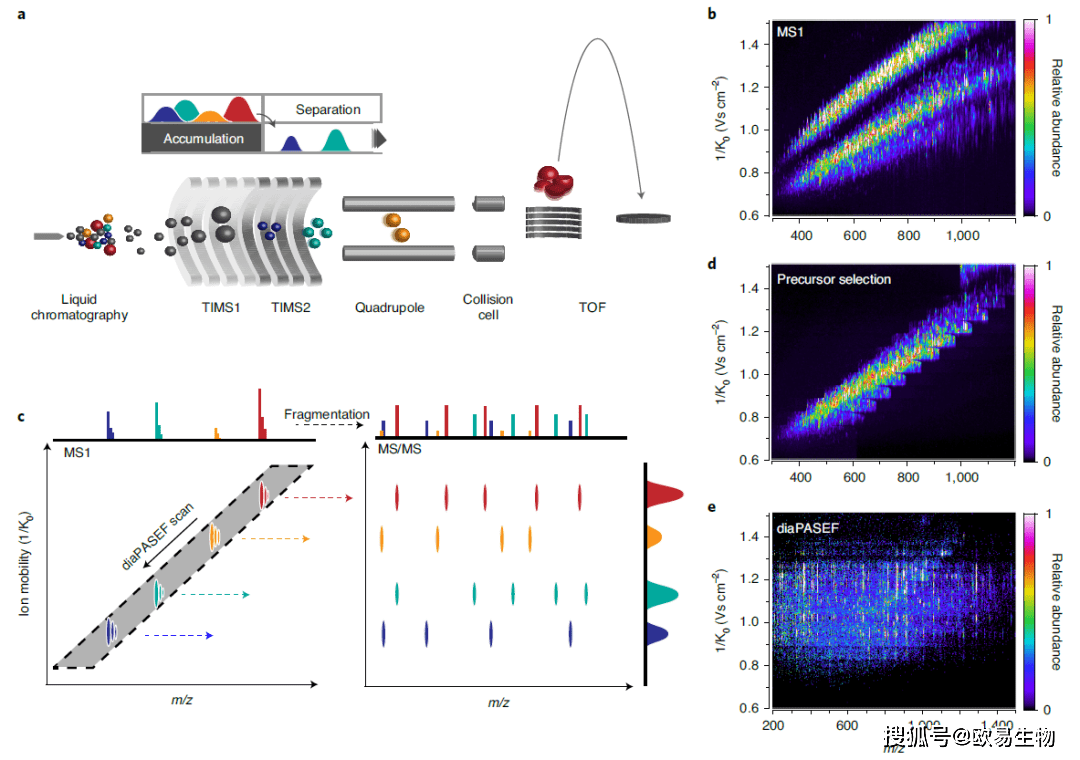
图1 | diaPASEF采集方法 (a)timsTOF Pro质谱仪的离子路径示意图。 (b)HeLa细胞肽段离子淌度与m/z的相关性。 (c)在diaPASEF中,四极杆隔离窗口(灰色)根据离子淌度(箭头)动态定位。 (d)采用步进四极杆隔离方案实现diaPASEF肽段(母离子)选择。 (e)使用d中的肽段(母离子)选择方案进行的单个diaPASEF扫描的示例。 研究结果 1、diaPASEF原理 在timsTOF Pro仪器(Bruker Daltonik)中,通过液相色谱分离的肽被离子化,引入质谱仪中并立即被捕获在双TIMS设备中(图1a)。淌度分离的离子到达正交加速器,快速的TOF脉冲产生高分辨率的质谱图(在整个质量范围内,分辨率>35,000)。对于给定电荷的肽离子,离子淌度和质量是相关的(图1b)。作者认为与其他DIA采集方案相比,此功能可用于隔离DIA的母离子(肽段)质量窗口,而不会丢失各个质量窗口外的离子。鉴于低迁移率(通常为高m/z)离子被捕获在TIMS出口附近,它们首先被释放,因此质量选择四极杆必须首先定位在高m/z位置。随着更高迁移率(通常是降低的m/z)离子从TIMS依次释放,四极杆质量隔离窗口应向下滑动以降低m/z值以完全传输离子云(图1c)。为了逼近理想的diaPASEF扫描,作者根据TIMS斜坡时间逐步调整了隔离窗口,涵盖了2+和3+电荷状态的绝大多数母离子(图1d)。每个DIA窗口中的碎片离子都是在母离子的精确离子淌度位置处检测到的(图1e)。 2、量化增加的离子采样效率 为了在实践中探索diaPASEF原理,作者测量了BSA的胰蛋白酶酶切产物,并比较了通过DDA,DIA和diaPASEF采集方法获得的信号。作为一个典型的例子,肽段DLGEEHFK在9 s内被洗脱(图2a)。在DDA中,双电荷的母离子(肽段)在洗脱峰的开始处累积一次,持续100 ms然后破碎。这大约占总洗脱时间的1%,远小于由相对峰面积估算的整个前体离子总量的1%。在DIA中,由于相对较快的循环时间(1.6 s),该肽段在其洗脱曲线上破碎了7次。这足以重建色谱峰的形状,但仍只捕获了总离子信号的一小部分(小于5%)。相比之下,diaPASEF方案对每次扫描中的碎片进行了总计超过100次的采样,这使得每个时间点的碎片几乎都得到了完整的记录。接下来作者研究了HeLa细胞酶切产物的离子采样效率。为了解决数据中碎片离子密度高的问题,作者选择了四次diaPASEF扫描的方案,每次用50 m/z隔离窗口隔离大约四分之一的母离子,另一个方案有16个diaPASEF扫描和25 m/z隔离窗。DIA的离子流大约比DDA高出三倍,而四扫描diaPASEF方案与DIA相比使累积的肽离子流进一步增加了五倍(图2b,c)。由此得出结论,diaPASEF原理在简单和复杂的蛋白质组学中都能如预期般提高数据采集效率。
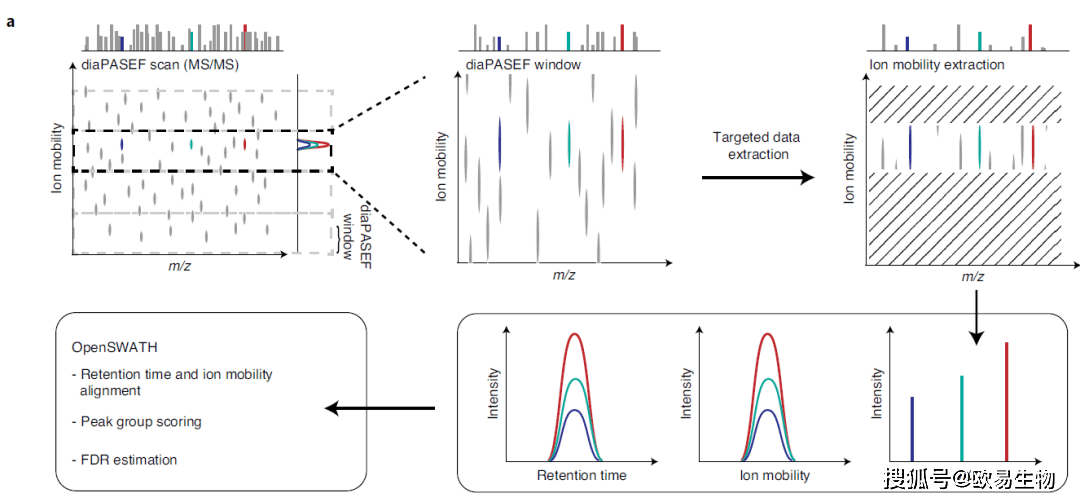
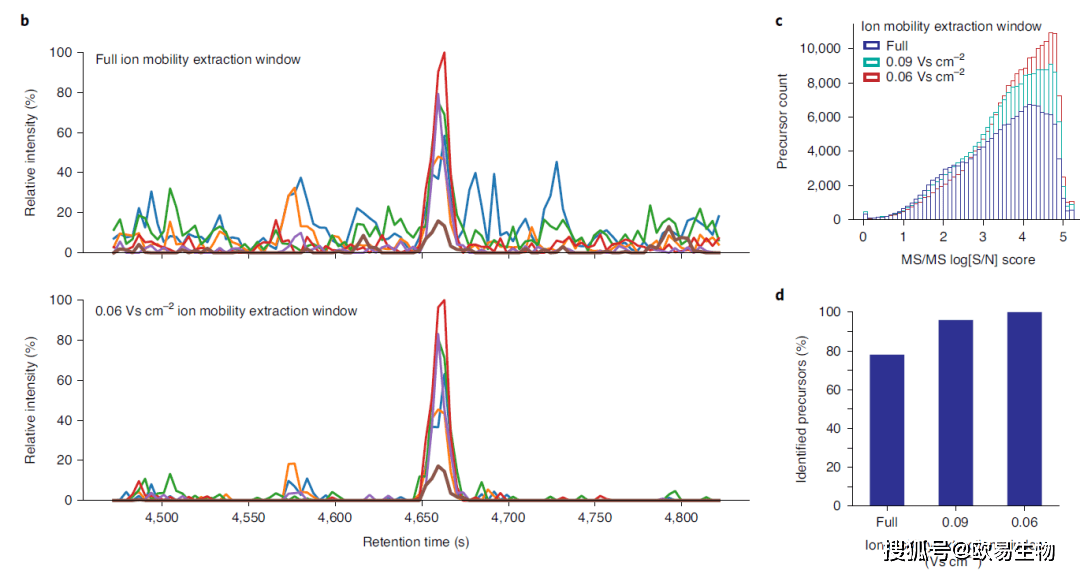
图2 | 不同数据采集方法的效率 (a)使用DDA、DIA以及diaPASEF方法获得的双电荷DLGEEHFK肽前体的y6离子的提取碎片离子色谱图。 (b)在通过DDA,DIA和两种diaPASEF方案获得的200 ng HeLa酶切产物的单次运行分析中,从多电荷母离子中检测到的离子电流。 (c)b中的累积离子电流。 3. 四维数据的数据提取 为了从这种新颖的数据结构中鉴定和定量肽段,作者开发了Mobi-DIK(离子淌度DIA分析试剂盒;图3a)。该工作流基于在色谱洗脱时间内从采集的数据集中有针对性地提取特定母离子的碎片离子集,然后进行统计评分。Mobi-DIK将该数据分析原理从DIA扩展到了diaPASEF。首先,使用DDA模式的PASEF产生有离子淌度信息的谱图库,使用一组高可信度的肽段,可以自动以m/z,保留时间和离子淌度维度执行参考库和实验数据之间的校准。限制离子淌度提取宽度可从同一母离子质量窗口的共洗脱肽中去除具有不同离子淌度的信号(图3b)。接下来,作者使用已建立的OpenSWATH模块选择峰组。与信噪比的增加相一致,相应的二级谱信噪比得分随着离子淌度提取窗口的缩小而按比例增加(图3c)。结果在一次完整蛋白质组的单次运行分析中,与传统分析相比,在离子淌度维度上进行有针对性的提取可使肽段鉴定率提高22%(图3d)。
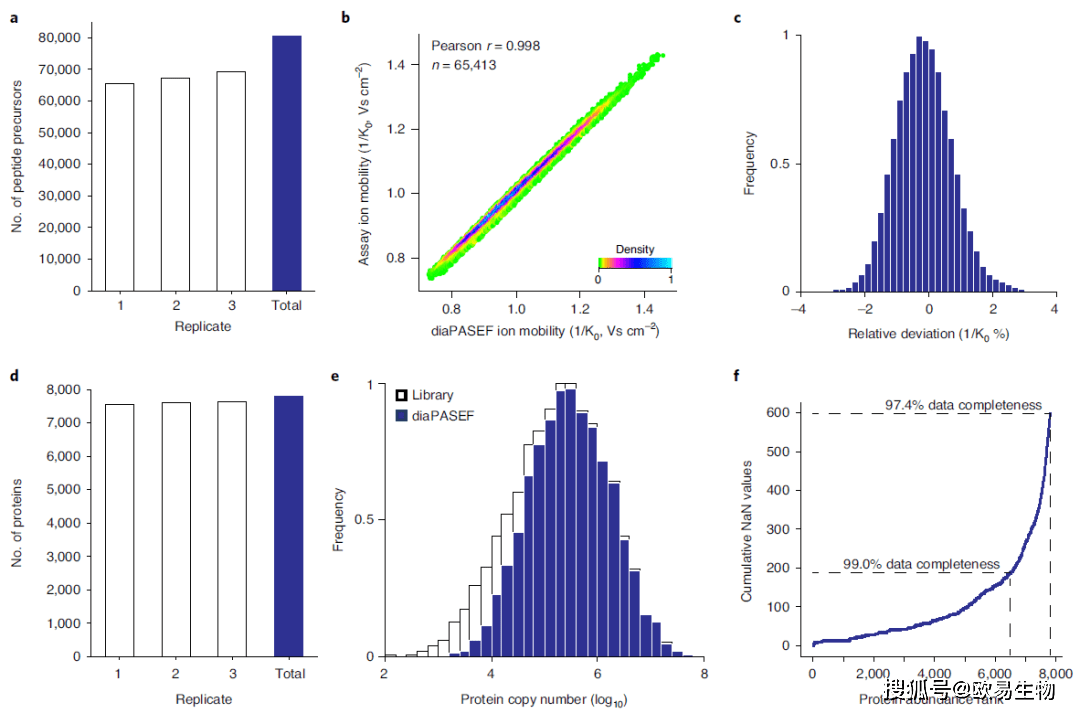
图3 | 离子淌度目标数据提取 (a)Mobi-DIK工作流程中从diaPASEF扫描中提取碎片离子色谱图的步骤。 (b)diaPASEF实验中肽段DGLLIIGVHSAK的碎片离子谱,该肽段来自HeLa消化液(顶图无离子淌度限制,底图有离子淌度限制)。 (c)在HeLa消化液的三次diaPASEF分析中,从同一diaPASEF窗口中的共洗脱母离子中去除干扰信号。 (d)c中三次diaPASEF分析中检测肽段离子的百分比。 4. 单针(Single-run)蛋白质组分析 为了在典型的DIA实验中研究diaPASEF,作者首先从24个组分的HeLa消化液中构建了DDA PASEF的参考库,它由135,671个肽段和9,140种蛋白组成。对于200 ng的样品量和120分钟的液相色谱-质谱分析,作者设计了一个采集方法,每100 ms diaPASEF扫描中具有四个窗口(25 m/z的隔离窗)。在三次重复实验中,共检测到80,580个母离子(1%FDR)(图4a)。diaPASEF中的离子淌度值与参考库中的高度相关(r> 0.99,图4b),中位数绝对偏差为0.6%(图4c)。总体而言,在FDR为1%的情况下,鉴定出66,998个特异的肽序列,平均鉴定到7,601种蛋白,三次实验共鉴定7,800种蛋白。(图4d)。定量的蛋白质的动态范围大约为四个数量级(图4e)。其中三次重复样本中共同定量了7,348种蛋白(94%),从而得到了一个几乎完整的数据矩阵(图4f)。
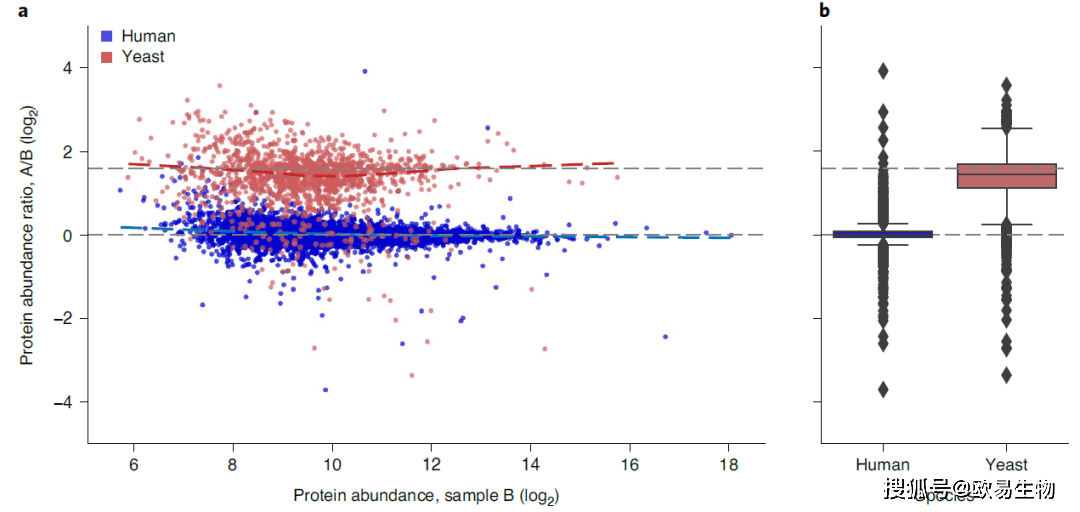
图4 | 使用diaPASEF进行单针HeLa蛋白质组分析 (a)使用16次扫描diaPASEF方案,以120 min梯度注入200 ng HeLa消化液,三次重复进样中肽段离子的数量。 (b)母离子离子淌度在diaPASEF中与参考库的相关性。 (c)diaPASEF与参考库中离子淌度的相对偏差。 (d)定量蛋白质的数量。 (e)参考库中蛋白质数量与三次diaPASEF实验检测的蛋白质数量。 (f)三次重复进样中缺失的蛋白质定量数据点的累积数量与减少的蛋白质丰度有关。 5. 非标定量测试 接下来作者建立了两个蛋白质组实验。分别向200 ng HeLa样品中掺入了约45 ng和15 ng的酵母消化液,对两组样本进行三次重复检测。使用合并的人和酵母库进行的Mobi-DIK分析定量了101,395个人的质谱峰和7,992个酵母质谱峰中的82,808个人和7,483个酵母的特异性肽段序列,据此推断出7,943种人蛋白和2,250种酵母蛋白。尽管低丰度酵母掺入量仅占样品的7%,但作者在两个样品中的至少两次重复中定量了7,697种人蛋白和1,394种酵母蛋白。它们的蛋白质丰度比值根据混合比分为两个不同的群体(图5)。与上述定量精度一致,人源蛋白在整个丰度范围内以1:1的比例聚集(σ(log2) = 0.22)。低丰度的酵母掺入蛋白的定量总体精度较低(σ(log2) = 0.70)。结果表明非标diaPASEF工作流程可以准确地量化蛋白质丰度的变化。
图5 | 非标定量检测 (a)将HeLa细胞消化液掺入约45 ng(样品A)和15 ng(样品B)酵母消化物,并使用16扫描diaPASEF方案进行120分钟梯度的diaPASEF分析(重复三次)。 (b)a中数据的箱线图。 6. diaPASEF对高通量和高灵敏度蛋白质组学的适应性 diaPASEF方案可以进行优化,以平衡选择性(较窄的隔离窗口),灵敏度(较高的质谱效率,较少的diaPASEF扫描)和母离子覆盖范围(图6a)。快速色谱方法通常需要较短的质谱循环时间,以实现足够数量的数据点以进行准确定量。因此作者设计了一种采集方案,该方案以0.9 s的循环时间专注于更窄的母离子范围。为了测试该方案,作者使用了一种液相色谱系统,该系统具有快速的周转时间和预定义的标准梯度,用于每天分析60、100和200个样品(Evosep One)。用每天60个样品的方法(21分钟梯度)对200 ng HeLa进行三次分析,每次运行平均定量4,813种蛋白,总共定量5,183种蛋白,中位变异系数为5.8%(图6b,c)。值得注意的是,其中4,255种定量蛋白质的变异系数 |

【本文地址】