| 提升语义分割性能的几种方法[转] | 您所在的位置:网站首页 › 语义分割有什么用 › 提升语义分割性能的几种方法[转] |
提升语义分割性能的几种方法[转]
|
原文:提升语义分割性能的几种方法 - CSDN
转载,备忘,感谢!
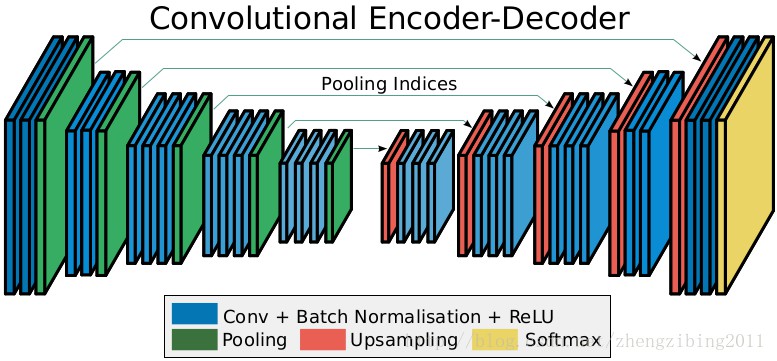
1.图像语义分割面临的挑战 [1] - 特征分辨率减小:主要是由神经网络中的重复最大池化Pooling和降采样( stride 跨越) 操作造成的,而采用此种操作的原因是: A.降维,以免参数过多难以优化; B.基于深度学习的语义分割是从用于分类任务的CNN转化而来;而在分类任务中,CNN分类器要求对输入的空间变换具有不变性,池化恰能满足这样的要求. [2] - 不同 scale 下目标存在的状况:主要是目标在 multi-scale 图像中的状态造成的. 因为在同一种尺度下,不同目标的特征往往响应并不相同. 如需要在较大的尺度下才能较好地提取图像中比较小的目标,而较大的目标为了获取全局性信息也必须在较小的尺度下才能实现.[3] - CNN的空间不变性造成定位精度的下降:对于分割任务而言,由于pooling操作引起的分类器对输入的空间变换具有不变性丢失空间信息,内在的限制了分割的空间精度. 2. 现阶段解决方法 FCN 作为将 CNN 应用于 semantic segmentation 的 forerunner,贡献巨大. 但 FCN 方法具有一些不足.为保证最终的 feature map 不至于过小,FCN 的 conv1 引入 pad=100,会产生较大的噪声;32倍 upsample(deconvolution) 非常粗糙,而且 deconvolution 的 filter不可学习;skip architecture 虽能有效提高精度,但需要3次训练,即 FCN-32s->FCN-16s->FCN-8s.除skip architecture外,随着研究的深入,针对以上挑战,有以下几种方法解决: 2.1 Encoder-Decoder结构 采用此种思想的代表为 DeconvNet,SegNet,其基本思想是采用一种对称结构将由于 pooling 操作而减小的feature map通过逐步的 upsample 逐渐恢复到原图像大小,同时在upsample阶段,融合了subsample中pooling index,具体细节可参见原文.
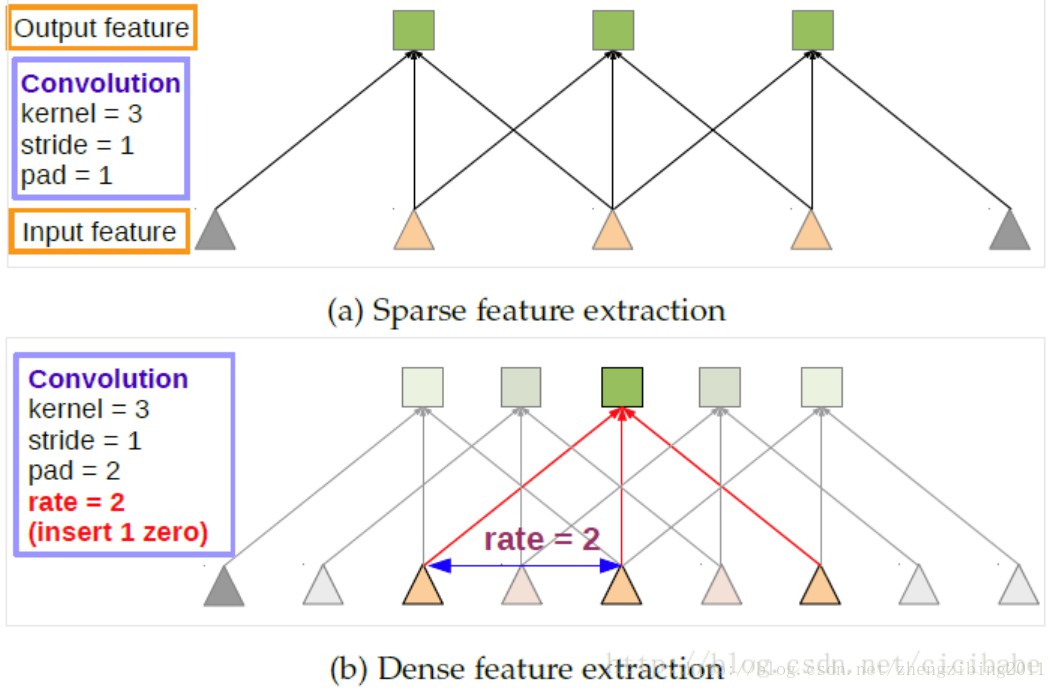
2.2 Atrous Convolution 带孔卷积 feature map 的减小是由于 pooling 造成的,为确保一定精度的feature map,能否不使用或减少使用pooling呢?理论上是可行的,但如果这样做会使得需要优化的参数过多,重要的是难以基于以前的 model 进行fine-tuning,atrous convolution解决了这个问题.在DeepLab中令 pool4,pool5 的 stride=1,再加上1 padding,这样经过 pooling 后 feature map 大小不变,但后层的感受野发生了变化,为使感受野不变,后面的卷积层使用 atrous convolution,其作用是在不增加参数的前提下,增加感受野. 因此,解决了feature map空间分辨率下降的问题.
2.3 ASPP
针对不同scale下的目标存在的状况问题,可通过两种方法解决: [1] 标准的多尺度处理方法,用共享相同参数的并行CNN分支,从不同尺度的 Input image 中提取score map,然后进行双线性差值,最终对它们进行融合,在不同尺度上获得每个位置的最大响应. 训练和测试时均这样处理,比较繁琐的是需要计算输入图像的每个尺度在各layer上的特征响应.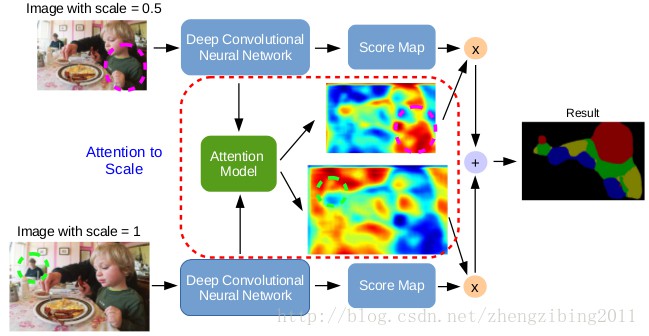
[2] 基于任意尺度上的区域都可以用在这个单一尺度上重采样卷积特征进行精确有效地分类的思想,使用多个不同采样率上的多个并行带孔卷积,每个采样率上提取的特征再用单独的分支处理,融合生成最后的结果.
2.4 DenseCRF CRF 几乎可以用于所有的分割任务中图像精度的提高.CNN 可用于对图像中的目标进行分类并预测出目标的大致位置,但并不能真正描绘他们的边界. 因此,将DCNN 的识别能力和全连接 CRF 优化定位精度耦合在一起,能成功的处理定位挑战问题,生成了精确的语义分割结果.全连接CRF理论较为复杂,在此不作阐述. 类似的概率图模型(PGM)还有MRF,G-CRF(高斯-条件随机场). |
 DeepLab
DeepLab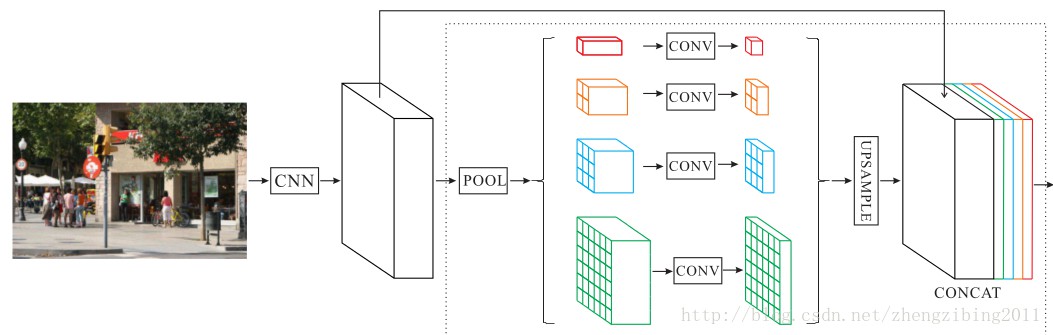 PSPNet
PSPNet
【本文地址】