| 【推荐系统入门到项目实战】(七):隐式反馈与贝叶斯个性化排序模型(BPR) | 您所在的位置:网站首页 › 评分预测和排序预测 › 【推荐系统入门到项目实战】(七):隐式反馈与贝叶斯个性化排序模型(BPR) |
【推荐系统入门到项目实战】(七):隐式反馈与贝叶斯个性化排序模型(BPR)
|
【推荐系统】:隐式反馈和排序模型
🌸个人主页:JOJO数据科学📝个人介绍:统计学top3高校统计学硕士在读💌如果文章对你有帮助,欢迎✌关注、👍点赞、✌收藏、👍订阅专栏✨本文收录于【推荐系统入门到项目实战】本系列主要分享一些学习推荐系统领域的方法和代码实现。
隐式反馈和排序模型
到目前为止,我们对基于模型的推荐系统的讨论集中在使用基于均方误差的目标来预测真实价值的结果,例如评分预测。也就是说,我们已经根据相应的回归方法描述了基于模型的推荐。正如我们在考虑点击、购买或评分数据时为基于邻域的推荐开发了单独的方法一样,在这里我们考虑如何调整基于回归的方法来处理二元结果(例如点击和购买)。很自然的,我们可能会想象我们可以调整我们基于回归的方法来处理二元结果,就像logistic回归那样。也就是说,我们可以将模型输出传递给激活函数,这样正交互(positive intersection)与高概率相关联,而负交互与低概率相关联。 然而,在处理点击或购买数据时,我们应该考虑到没有被点击或购买的item不一定是负面互动——实际上没有被点击或购买的项目正是我们打算推荐的项目。 已经提出了几种技术来处理这种情况下的推荐。通常这类方法被称为“one-class”推荐,因为只观察到“正面”类(点击、购买、收听等)。该方法也称为隐式反馈推荐,因为信号(是否购买)仅隐式反应了我们喜欢或不喜欢某件商品。 接下来我们将主要介绍两种比较有效的方法 1. Re-weighting处理隐式反馈数据的一类方法是试图将实例重新加权为具有积极或消极的各种“置信度”。考虑正实例与“置信度”测量 r u , i r_{u,i} ru,i 相关联的情况,可以测量例如用户收听歌曲或观看特定节目的次数。负面实例仍然有 r u , i = 0 r_{u,i} = 0 ru,i=0,这样模型基本上假设负面实例必然与低置信度相关联,而正面实例之间的置信度可能有很大差异。最终,目标仍然是预测二元结果 p u , i p_{u,i} pu,i ,并且模型被训练为预测
预测器的形式类似于之前我们介绍的方法,均方误差最小来估计模型。主要区别在于这里是根据每个观察的置信度加权的:我们会给予买过或者点击过的实例给予更高的权重。
其中 c u , i c_{u,i} cu,i 是与每个观测相关的加权函数,它是 r u , i r_{u,i} ru,i 的单调变换,例如
其中 α α α和 ϵ \epsilon ϵ是超参数。这样,变换后得到的 c u , i c_{u,i} cu,i 确保负实例具有较小但非零的权重,而正实例根据其相关置信度接收越来越高的权重。 以类似的方式应用于负实例。提出了几种方案,其中两种方案如下:
第一个(称之为“面向用户”的权重),建议如果相应的用户与许多项目进行交互,则负面实例的权重应该更高;第二个假设如果相应的项目具有很少的关联交互,则负面实例应该被赋予更高的权重。 当然,具体怎么选用 c u , i c_{u,i} cu,i是根据相关的数据集和业务问题确定的。 2. 贝叶斯个性化排序(Bayesian Personalized Ranking)虽然上述的重新加权方案证明了在隐性反馈设置中谨慎对待 "负面 "和 "正面 "反馈的重要性,但它们最终还是优化了回归目标,因此仍然试图给未见过的实例分配 "负面 "分数。 这种方法的一个潜在问题是,未见过的实例正是我们想要推荐的,因此我们不应该鼓励模型给它们打负分。 一个较弱的假设是,虽然未见过的实例应该比正面实例的分数低,但它们不需要有负面的分数。也就是说,我们知道用户喜欢的项目比未见过的项目 “more positive”,但未见过的项目仍然可以有正向的分数。 例如,以淘宝为例,往往会给我们推荐许多我们之前没有买过的商品。 虽然正项目应该出现在我们推荐列表的前面,但是我们并不关心它们的实际分数(正或者负)。 同样,贝叶斯个性化排名(BPR)背后的思想是,我们应该生成项目的排名列表,使积极的项目出现在最前面。这是通过训练一个预测器 x u , i , j x_{u,i,j} xu,i,j来实现的,该预测器根据两个项目(i或j)中哪个是u所喜欢的(即排名较高)来分配一个分数:
现在,如果我们知道i是正面的,j是用户u的负面(或未见过的)项目,那么一个好的模型应该倾向于输出 x u , i , j x_{u,i, j} xu,i,j的正值。这种类型的预测策略(比较两个样本,而不是给单个样本打分)被称为配对模型。 x u , i , j x_{u,i,j} xu,i,j可以是任何预测因子,尽管最直接的选择是用预测值之间的差异来定义它,比如说
同意,我们可以将 x u , i x_{u,i} xu,i拓展到通过一个隐语义模型来定义,类似于方程的模型
基于模型的推荐方法项目,对于未见过的项目j来说, γ u γ j γ_uγ_j γuγj也应该是负的,只是差值是正的,也就是说,正的项目有更高的配对得分。 现在我们可以用模型是否正确输出正值 x u , i , j x_{u,i,j} xu,i,j来定义我们的目标,即给定一个正面项目i和一个未见过的项目j。理想情况下,我们希望计算模型能够正确地将正面项目排在比未见过的项目更高的位置。对于一个特定的用户u,我们有:
请注意,此数量取值介于 0 和 1 之间,其中 AUC 为 1 表示模型始终将正项排名高于未见过的项; AUC 为 0.5 意味着该模型并不比随机模型好。优化上述内容会带来两个问题。 首先,考虑所有 $(u, i, j) $三元组是不可行的;为了解决这个问题,可以对每个正项 i 随机抽取固定数量的未见项 j。 其次,上述方程中的目标是一个阶跃函数,其导数几乎处处为零。因此,我们将阶跃函数 δ ( x u , i , j ) δ(x_{u,i,j}) δ(xu,i,j) 替换为可微分的替代函数,例如 sigmoid 函数。使用 sigmoid 函数允许我们将 σ ( x u , i , j ) σ(x_{u,i,j}) σ(xu,i,j) 解释为概率
从这一点来看,优化的进行方式与我们逻辑回归的方式大致相同:我们使用
σ
(
x
u
,
i
,
j
)
σ(x_{u,i,j})
σ(xu,i,j) 来定义给定训练集的模型的(对数)概率,并减去正则化项: 实例数据 data[0] {'user_id': '70da424cfb5d9e0e9839651405092f56', 'book_id': '10267349', 'review_id': '1b71e342273ecd830ae1276081fdbb15', 'rating': 4, 'date_added': 'Tue Jul 26 08:31:21 -0700 2011', 'date_updated': 'Wed Jul 27 21:08:46 -0700 2011', 'read_at': 'Wed Jul 27 00:00:00 -0700 2011', 'started_at': 'Tue Jul 26 00:00:00 -0700 2011', 'n_votes': 0, 'n_comments': 1}建立一些实用的数据结构。由于我们将把数据转换为稀疏的交互矩阵,这里的主要结构是把每个用户/项目分配给一个从0到nUsers/nItems的ID。 userIDs,itemIDs = {},{} for d in data: u,i = d['user_id'],d['book_id'] if not u in userIDs: userIDs[u] = len(userIDs) if not i in itemIDs: itemIDs[i] = len(itemIDs) nUsers,nItems = len(userIDs),len(itemIDs) nUsers,nItems (59347, 89311)将数据集转换为稀疏矩阵。只存储积极的反馈实例(即评级项目)。 Xui = scipy.sparse.lil_matrix((nUsers, nItems)) for d in data: Xui[userIDs[d['user_id']],itemIDs[d['book_id']]] = 1 Xui_csr = scipy.sparse.csr_matrix(Xui) model = bpr.BayesianPersonalizedRanking(factors = 5) model.fit(Xui_csr) 0%| | 0/100 [00:00 |
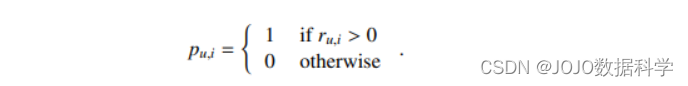
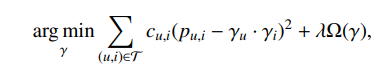
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-DJHlhrOX-1679839810371)(null)]](https://img-blog.csdnimg.cn/7e2bdb9fb5864fb48c63fbf241b5999c.png)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-37b01NIg-1679839810269)(null)]](https://img-blog.csdnimg.cn/e3b1fa07e49a4c9da0052df90970bb9e.png)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-cOO8MNmj-1679839810307)(null)]](https://img-blog.csdnimg.cn/116cd0f8c96e4766991e9b2102e143ef.png)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-hDyPX1ow-1679839810347)(null)]](https://img-blog.csdnimg.cn/d80dd271137a4c99ac1d1842a87424fe.png)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-J10yJHBP-1679839807105)(upload/image-20230326195703670.png)]](https://img-blog.csdnimg.cn/680514d129ba412584e1e292f586c639.png)

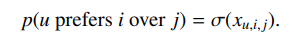
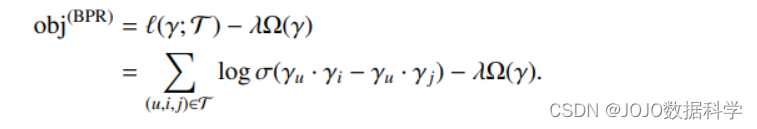
【本文地址】