| 磁盘中的程序必须加载到内存才能运行 | 您所在的位置:网站首页 › 计算机执行的指令和数据存放在机器的 › 磁盘中的程序必须加载到内存才能运行 |
磁盘中的程序必须加载到内存才能运行
|
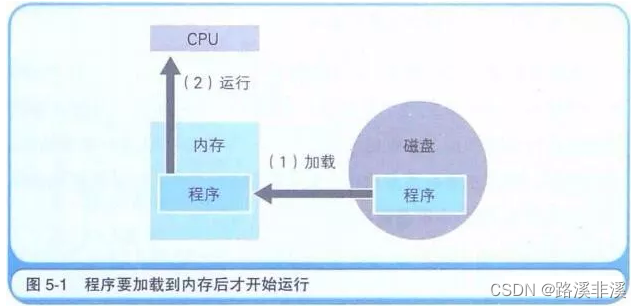
计算机中主要的存储部件是内存和磁盘。磁盘中存储的程序必须加载到内存之后才能运行。在磁盘中保存的原始程序是无法直接运行的。这是因为,负责解析和运行程序内容的CPU,需要通过内部程序计数器来指定内存地址,然后才能读出程序。即使CPU可以直接读出并运行磁盘中保存的程序,由于磁盘读取速度慢,程序的运行速度还是会降低的。总之,存储在磁盘中的程序需要读入到内存后才能运行。
所谓程序,实质就是一系列有指定地址的指令,CPU按照地址去取指,解码后按照指令去执行,期间所产生的的数据也是放在内存中(缓存或者寄存器充当临时存储),如果需要,也可以将内存中的数据保存到外存中(硬盘或者Flash) 补充:一般情况下,外存是无法随机寻址的。 由上述可知,内存一般保存的是程序和数据。 在这个基础上,才有了内存的一些分区管理,比如堆、栈、Data区、Bss区这些放数据的,以及放程序(其实就是各种函数和指令)的代码段(常量通常也放在这)等等。 问题来了。 程序是如何被优雅的装载到内存中的? 直接参考; 内存管理:程序是如何被优雅的装载到内存中_51CTO博客_储存内存管理 关于计算机中的程序和数据 一直以来都有个疑问,一个程序中哪些算是指令,哪些算是数据?指令是储存在哪?数据又是储存在哪? 可参考这个视频: 存储器、指令与数据的存储_哔哩哔哩_bilibili 其实,如果想要深入理解这个问题,就需要了解机器指令。 一条C语言会转成对应的(一条或多条)汇编语句,每条汇编语句对应一个机器码,供计算机直接执行。 机器指令是CPU能直接识别并执行的指令,它的表现形式是二进制编码。机器指令通常由操作码和操作数两部分组成,操作码指出该指令所要完成的操作,即指令的功能,操作数指出参与运算的对象,以及运算结果所存放的位置等。 由于机器指令与CPU紧密相关,所以,不同种类的CPU所对应的机器指令也就不同,而且它们的指令系统往往相差很大。但对同一系列的CPU来说,为了满足各型号之间具有良好的兼容性,要做到:新一代CPU的指令系统必须包括先前同系列CPU的指令系统。只有这样,先前开发出来的各类程序在新一代CPU上才能正常运行。 机器语言是用来直接描述机器指令、使用机器指令的规则等。它是CPU能直接识别的唯一一种语言,也就是说,CPU能直接执行用机器语言描述的程序。 这里面涉及到指令系统的设计,比如冯诺依曼体系,就是将指令和数据储存在一起,哈弗结构则是将指令和数据分开等等。 一条指令包含操作码和地址码两部分。操作码表示指令的操作和功能,用来告诉计算机来做什么操作,地址码表示操作数的地址或者操作数本身,用来告诉计算机操作的对象,以及这些对象的地址等信息。
在一个指令系统中,若所有指令的长度都是相等的,则称为定长指令字结构。定字长指令的执行速度快,控制简单。若各种指令的长度随指令功能而异,则称为变长指令字结构。 指令的地址码结构 一般的计算机运算指令要包含以下这些内容: 第一个操作数或者其地址 A1 ; 第二个操作数或者其地址 A2 ; 需要对操作数进行的操作 OP ; 计算结果的存放地址 A3 ; 下一条指令的地址 A4 。 例如:我们让计算机执行一个1+2=3的指令。首先需要让计算机取出操作数1( A1 );然后再取出操作数2( A2 );之后将两者送到运算器中进行加和( OP )运算;运算的结果放入主存的某个单元中( A3 );之后再取出下一条指令( A4 ),这个过程一般可以表示为 (A1)OP(A2)→A3 。(我们约定,如果 Ax 中存储的是操作数的地址,则用 Ax 表示其地址,用 (Ax) 表示操作数本身;如果 Ax 中存储的是操作数本身,则直接用Ax 表示操作数) 除了操作 OP 外,另外的4个地址信息均需要在地址码中体现。 下面有几种常用的地址码格式: 1.四地址指令: 上文提到的四个地址均有在地址码部分给出,这样的指令称为四地址指令。 其指令格式如下图所示:
表示为 (A1)OP(A2)→A3 下一条指令的地址A4=下一条指令的地址 即对 A1 与 A2 内的数据进行操作后,结果存储到 A3 中,然后执行 A4 中的指令。 四地址指令需要访问4次内存:取指令一次,取第一操作数一次,取第二操作数一次,保存操作数一次。 2.三地址指令: 三地址指令省略了 A4 :下一条指令的地址。由于大多数指令是按主存中的顺序执行的,因此可以采用一个程序计数器( PC )来记录指令的地址,每当执行下一条指令时, PC 的值自加1。这样的话,就可以省略掉第四个地址,得到三地址指令。 表示为 (A1)OP(A2)→A3 (PC)+1→PC (隐含) 即 即对 A1 与 A2 内的数据进行操作后,结果存储到 A3 中,然后 PC 自加,顺序执行下一条指令。 例如,加操作:ADD A B X;(A+B送到X中) 与四地址指令相同,三地址指令也需要访问4次内存。 3.二地址指令: 如果第一个操作数地址与结果存放地址相同,即 A1 与 A3 相同,则可以省略掉 A3 ,称为二地址指令。 表示为 (A1)OP(A2)→A1 (PC)+1→PC (隐含) 即对 A1 与 A2 内的数据进行操作后,结果仍然存储到 A1 中,然后 PC 自加,顺序执行下一条指令。 同三地址指令相同,执行二地址指令同样也需要访问4次内存。 4.一地址指令: 如果我们进一步把另外一个操作数省略,那么就可以得到一地址指令。 通常来说,一地址指令有如下两种情况: (1)另一个被省略的操作数由内存外的累加寄存器 Acc ——一般用来暂存ALU运算的结果。 指令可以表示为 (Acc)OP(A1)→Acc (PC)+1→PC (隐含) 即 A1 中的数据与 Acc 中的数据共同送到运算器中做运算,其运算的结果保存在 Acc 中。之后 PC 自增,继续顺序执行下一条指令。 这种类型的一地址指令通常只需要访问2次内存:存内存中取指令一次,从内存中取操作数一次,因为不需要把结果存入内存中,所以只需要访问两次。 (2)只是针对 A1 内数据执行加一、减一、求反、求补等单操作数指令。 指令可以表示为 OP(A1)→A1 (PC)+1→PC (隐含) 即只对 A1 中的数据进行操作,然后将结果存入 A1 中。之后 PC 自增,继续顺序执行下一条指令。 这种类型的一地址指令需要访问3次内存:从内存中取指令一次,从内存中取操作数一次,将计算后的结果放入内存中一次。 5.零地址指令: 零地址指令只有操作码,没有地址码。 零地址指令常用在堆栈的压入和弹出操作上,比如可以用 PUSH 操作码来表示将数据压入栈中,用 POP 操作码来表示将数据弹出栈。通过这些功能可以实现原有的三操作数命令。比如连续两次pop出的数据可以默认地进入算术逻辑单元进行运算,然后运算的结果再次被push入栈中。 不同地址指令的长度、执行速度不一样,适用的场景也不一样。一般来说,访问主存的次数越少,执行速度越快。计算机中有大量的寄存器,访问寄存器要比访问主存速度快很多。因此,操作数蕴含在寄存器中的指令(一地址指令)执行速度会更快。 指令和数据均存放在内存中,计算机如何区分它们是指令还是数据? 通常完成一条指令可分为取指阶段、分析阶段和执行阶段。在取指阶段通过访问存储器可将指令取出;在执行阶段通过访问存储器可将操作数取出。这样,虽然指令和数据都是以0、1代码形式存在存储器中,但CPU可以判断出在取指阶段访存取出的0、1代码是指令;在执行阶段访存取出的0、1代码是数据。 计算机区分指令和数据有以下2种方法: 1.通过不同的时间段来区分指令和数据,即在取指令阶段(或取指微程序)取出的为指令,在执行指令阶段(或相应微程序)取出的即为数据。 2. 通过地址来源区分,由PC提供存储单元地址的取出的是指令,由指令地址码部分提供存储单元地址的取出的是操作数。 这里面涉及到的哈弗结构和冯诺依曼结构相关内容,可直接参考: 指令也是数据?浅谈计算机体系结构 - 掘金 注意:单片机使用的是哈弗结构; 从抽象层面来看,可以就将程序看做是指令和数据,只是冯诺依曼结构将两者储存在同一个存储空间,哈弗结构将二者分开存储。 最简单的汇编指令格式是操作码(例如:MOV、BL)和操作数(例如:pc, lr)。操作码易于理解,例如MOV表示将某个值从一处传送到另一处,BL表示跳转到某处;而操作数则表示一处和另一处到底是哪里(是在寄存器中还是内存中),要跳转的位置在哪里(或者是绝对地址或者是相对地址)。操作数部分要解决的问题是:到哪里去获得操作数?因此就有了寻址方式的分类。 指令数据中,操作码就是操作码,地址码部分可分为三类数据: 寄存器码:指示着对应的寄存器,通常为几个二进制数,不同的寄存器码代表着不同的寄存器。 地址码:也就是某块内存地址; 立即数码:直接的数据; 其实,看到这里,是不是发现了什么?就是对应了汇编代码中的寄存器、内存地址、立即数等操作数。 其实,汇编代码就是对机器代码的一种自然语言解释。 例如一个简单的加法运算: 0001 0010 0000 0001 其中,前四位表示操作码,也就是相加这个操作;接下来四位表示寄存器码,指示某个寄存器;最后的八位就表示一个立即数,表示要将第二个寄存器加上常数值1。 不同的机器码有对应的电路实现。 注意:指令和数据是存放在一起,并不是说二者是连续的,只是没有分为两块内存分别访问罢了。出于方便管理和组织的考虑,通常将指令和数据分成几个若干的存储区。是什么样的存储区呢?就是代码区、data区、bss区、堆区、栈区这些,指令通常存放在代码区,或者叫文本区、text区。 |

【本文地址】