|
2012年
Problem A树的叶子1.摘要2.Introduction / 引言3.Breaking Down the Problem / 问题的分解4.Assumptions / 假设5.Nomenclatures / 术语6.模型【1】模型一: 叶子的分类(1)参数(2)比较(3)参数的权重 :层次分析(4)模型检验
【2】模型二:树叶分布和形状1.思考2.三中情况:3.得到形状与重叠率的关系4.用过实例检验
【3】树形与叶形【4】树叶总质量1.基于
C
O
CO
CO~2~累积能力分类2.确定求质量公式(根据累积量求总质量)3.利用树龄求出累积率4.利用树的特征求树龄5.模型描述
7.模型优缺点
Problem A树的叶子

1.摘要

2.Introduction / 引言

3.Breaking Down the Problem / 问题的分解
 
4.Assumptions / 假设
 
5.Nomenclatures / 术语

6.模型
【1】模型一: 叶子的分类
(1)参数
   为了对树叶进行分类,需要这7个参数 为了对树叶进行分类,需要这7个参数
(2)比较
计算出这片树叶的七个参数,与某一个标准树叶类参数的方差
I
I
I 引入偏差指数用来表示: 它是数据库和待分类树叶间方差乘上合适权重后, 对 7 个参数的求和.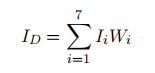 就是假设需要判断A是下面六种常见树叶中的什么类型,我们计算出A的七个参数,然后根据七个参数分别和数据库中六个分类的对应指标求方差,然后乘相应的权重求和,得到最小的,就是说A和最小的偏差最小,那么A就是这个类型的 就是假设需要判断A是下面六种常见树叶中的什么类型,我们计算出A的七个参数,然后根据七个参数分别和数据库中六个分类的对应指标求方差,然后乘相应的权重求和,得到最小的,就是说A和最小的偏差最小,那么A就是这个类型的   六种常见的树叶 六种常见的树叶  I
I
Ii 为相应参数的方差,
I
I
I7 例外:
I
I
Ii 为相应参数的方差,
I
I
I7 例外: 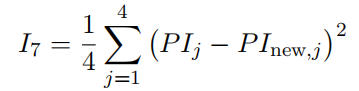 因为第七个指标是四部分面积分别于总面积之比的比例因子,所以会有四个值,我们计算四个方差然后求算数平均值是最恰当的 因为第七个指标是四部分面积分别于总面积之比的比例因子,所以会有四个值,我们计算四个方差然后求算数平均值是最恰当的
(3)参数的权重 :层次分析
首先, 我们建立一个 7 × 7 的对称倒数矩阵 (或成对比较parison: 矩阵) 来做比较:  表格数据的来源 表格数据的来源  类似这种分析表 类似这种分析表  然后得到每个因子的权重 A= 然后得到每个因子的权重 A= 
[V,D] = eig(A) %V是特征向量, D是由特征值构成的对角矩阵(除了对角线元素外,其余位置元素全为0)
Max_eig = max(max(D)) %也可以写成max(D(:))
[R C]=size(D)
CI = (Max_eig - C) / (C-1);
RI=[0 0 0.52 0.89 1.12 1.26 1.36 1.41 1.46 1.49 1.52 1.54 1.56 1.58 1.59]; %注意哦,这里的RI最多支持 n = 15
CR=CI/RI(C)
disp('一致性指标CI=');disp(CI);
disp('一致性比例CR=');disp(CR);
if CR |