| 散列表(一)解决冲突的四种办法 | 您所在的位置:网站首页 › 解决冲突最好的办法是宽容还是忍耐 › 散列表(一)解决冲突的四种办法 |
散列表(一)解决冲突的四种办法
|
一)哈希表简介
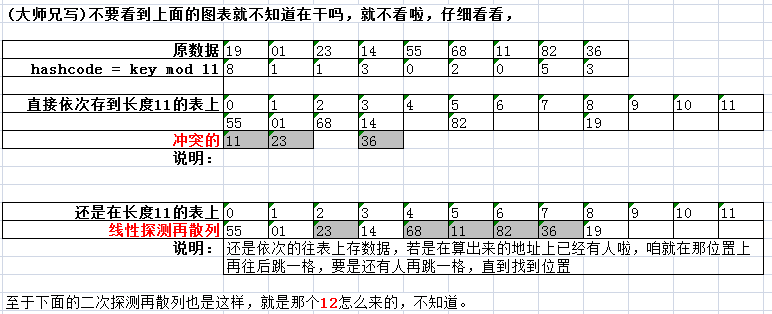
非哈希表的特点:关键字在表中的位置和它之间不存在一个确定的关系,查找的过程为给定值一次和各个关键字进行比较,查找的效率取决于和给定值进行比较的次数。 哈希表的特点:关键字在表中位置和它之间存在一种确定的关系。 哈希函数:一般情况下,需要在关键字与它在表中的存储位置之间建立一个函数关系,以f(key)作为关键字为key的记录在表中的位置,通常称这个函数f(key)为哈希函数。 hash : 翻译为“散列”,就是把任意长度的输入,通过散列算法,变成固定长度的输出,该输出就是散列值。 这种转换是一种压缩映射,散列值的空间通常远小于输入的空间,不同的输入可能会散列成相同的输出,所以不可能从散列值来唯一的确定输入值。 简单的说就是一种将任意长度的消息压缩到莫伊固定长度的消息摘要的函数。 hash冲突:(大师兄自己写的哦)就是根据key即经过一个函数f(key)得到的结果的作为地址去存放当前的key value键值对(这个是hashmap的存值方式),但是却发现算出来的地址上已经有人先来了。就是说这个地方要挤一挤啦。这就是所谓的hash冲突啦 二)哈希函数处理冲突的方法 1)开放定址法: 其中 m 为表的长度 对增量di有三种取法: 线性探测再散列 di = 1 , 2 , 3 , … , m-1 平方探测再散列 di = 1 2 , -12 , 22 , -22 , 32 , -32 , … , k2 , -k2 (大师兄备注:吗单,上面的平方探测再散列是加1的平方;减1的平方,加2的平方,减2的平方,加3的平方,减3的平方。。。加k的平方,减k的平方。卧擦,老师你能再坑点么?法科。要是你直接看这个平方探测再散列的di是怎么来的,不一定能看懂老师ppt的这个写法,是平方的意思。上面的红色字呢,相当于是老师的ppt,是对应上面的图片一起看的。) 随机探测再散列 di 是一组伪随机数列 例子: 我在上面的这个配图底部写的那个红色的12,我当时测试的时候,不知道这个12,也就是上面增量 di 的由来。不知道,限制知道了,那是1的2次方。。。。老师懒得或者说不会给数字打角标。 上面这个只是老师的ppt,下面放上自己亲自整的测试。 先按照ppt上的hash算法:h(key) = key % 7,算出来对应的hash值,这个hash值暂时就决定,当前的这个值,存放在数组的位置。 都算完之后,就可以,按照这个hash值,依次的,把这些数,都放在下面的数组上。然后就有我自己的这个截图。 和上面的ppt推算的是一致的。 这个做法就是Java的HashMap就是这么实现的,简单的解释下,这个HashMap源码的这个链表产生机制。 在put()方法里面,最后部分有个如下的调用。 addEntry(hash, key, value, i);解释下几个参数的意思: 1,hash:就是根据key算出来的一个值,源码是这么滴–int hash = hash(key);, 这个算出来的这个就相当于是身份证号码,可以唯一确定一个人一样,唯一确定这个map 2,key:key就是我们在往hashmap里面put键值对的时候的key,使用map的时候,不是可以根据key拿到value吗。 3,value:这个同上啦,就是存的键值对的值。 4,i:源码里面是这么滴–int i = indexFor(hash, table.length);实际意思就是这个键值对存放在底层数组的索引下标。 然后这个i,可以对应到ppt上的那个取模之后的值,也就是确定在数组上的下标。 虽然在put的时候,可能会出现扩容的问题,但是在这咱就不考虑这个,只考虑如何生成链表,以及链表上的键值对的顺序。 createEntry(hash, key, value, bucketIndex); 这个方法就是真正的在创建一个节点到数组上。 这几个参数是一样的,和上面解释的一样的意思。 [java] view plain copy print ? //先从数组上取下原来的值,给塞到新的节点去,然后把新的节点再放到数组上。 //也就是后来居上的道理。ppt上画的也就有点毛病了。 //老师们嘛,就是 混口饭吃,一般都不斤斤计较这东西的。 void createEntry(int hash, K key, V value, int bucketIndex) { Entry e = table[bucketIndex]; table[bucketIndex] = new Entry(hash, key, value, e); size++; } //先从数组上取下原来的值,给塞到新的节点去,然后把新的节点再放到数组上。 //也就是后来居上的道理。ppt上画的也就有点毛病了。 //老师们嘛,就是 混口饭吃,一般都不斤斤计较这东西的。 void createEntry(int hash, K key, V value, int bucketIndex) { Entry e = table[bucketIndex]; table[bucketIndex] = new Entry(hash, key, value, e); size++; } 1234567 [java] view plain copy print ? static class Entry implements Map.Entry { final K key; V value; Entry next; int hash; /** * Creates new entry. */ Entry(int h, K k, V v, Entry n) { value = v; next = n; key = k; hash = h; } //****** static class Entry implements Map.Entry { final K key; V value; Entry next; int hash; /** * Creates new entry. */ Entry(int h, K k, V v, Entry n) { value = v; next = n; key = k; hash = h; } //****** } 123456789101112131415 上面就是hashmap底层数组上存的元素的model。也是能形成链表的关键,有兴趣的可以看看1.7的hashmap的源码。 3、4)再哈希、建立公共溢出区 3.再hash法,就是算hashcode的方法不止一个,一个要是算出来重复啦,再用另一个算法去算。反正很多,直到不重复为止咯。大师兄猜的 4.建立一个公共溢出区域,就是把冲突的都放在另一个地方,不在表里面。具体实现就 不知道啦,也是大师兄猜的。 总结一下的就是下面的四行字: 1.开放定址法(线性探测再散列,二次探测再散列,伪随机探测再散列) 2.再哈希法 3.链地址法(Java hashmap就是这么做的) 4.建立一个公共溢出区看到这个,自个儿还是得静下心来看看hashmap的源码,1.7的简单易懂,我还做了注解,可以看看,链接如下 Java 佳娃 1.8的 hashmap的理解的连接 Java 1.7 的hashmap 的理解,多了红黑树什么的。 |






【本文地址】