| 基于urllib抓取视觉中国旗下网站的高清图片 | 您所在的位置:网站首页 › 视觉中国网页上传图片在APP看不到 › 基于urllib抓取视觉中国旗下网站的高清图片 |
基于urllib抓取视觉中国旗下网站的高清图片
|
引言
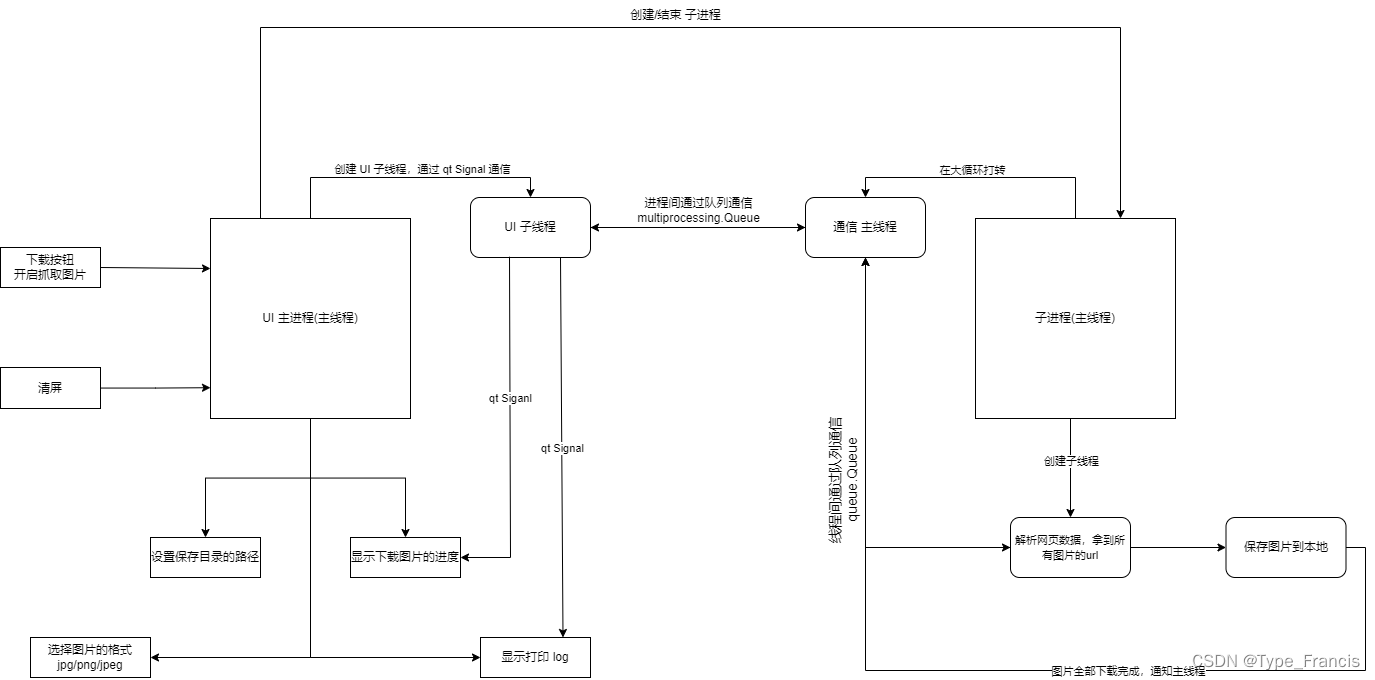
基于Pyside2开发可视化程序界面,抓取高清图片的小工具。用户可以通过输入要查找图片的名称,和需要抓取多少页进行下载到本地上,每一页的图片数量是根据网站的提供来决定的,当前对版权保护日益严格,因此在此说明爬取的图像仅用于个人学习使用,禁止用作商用目的。 项目架构 程序运行起来,只有一个UI主进程,在初始化的时候创建一个子线程,用于和待开启的子进程(点击下载按钮后,就会开启一个子进程完成事务)交换进程间的数据 。只有在用户点击下载按钮后,子进程才会被创建和开启,子进程又开启一个子线程,解析网页数据并拿到所有的图片url,下载所有的图片保存到本地,整个进程随时都有可能被UI主进程结束。 打印消息队列 比如子进程中的子线程,如果有消息要打印到UI,消息先从该子线程传递到主线程(queue.Queue),然后主线程在while循环判断到该队列不为空时,就取出信息放到用于进程间通信的打印消息队列(multiprocessing.Queue);UI子线程while循环判断到打印消息队列不为空,就取出消息并发送signal信号,通知UI主线程响应对应的槽函数,把消息加载到UI。下载进度队列 在下载图片过程中,更新下载的数量状态放到该队列;先是主线程从queue.Queue中取出状态,放到multiprocessing.Queue;然后UI子线程从多进程队列取出状态,发送signal信号,通知UI主线程响应对应的槽函数更新进度条的状态。下载完成队列 在子线程中执行全部下载并保存图片到本地上后,把下载完成的提示消息放进主线程(queue.Queue);然后主线程在while循环判断到该队列不为空时,就取出信息放到用于进程间通信的打印消息队列(multiprocessing.Queue); 查看网页源代码 目标网站:视觉中国旗下网站 打开浏览器进入网站,右击鼠标有个查看网页源代码的功能(Ctrl+U),我们眼前就会看到密密麻麻的的信息,这些信息也是我们要抓取图片的重要信息。
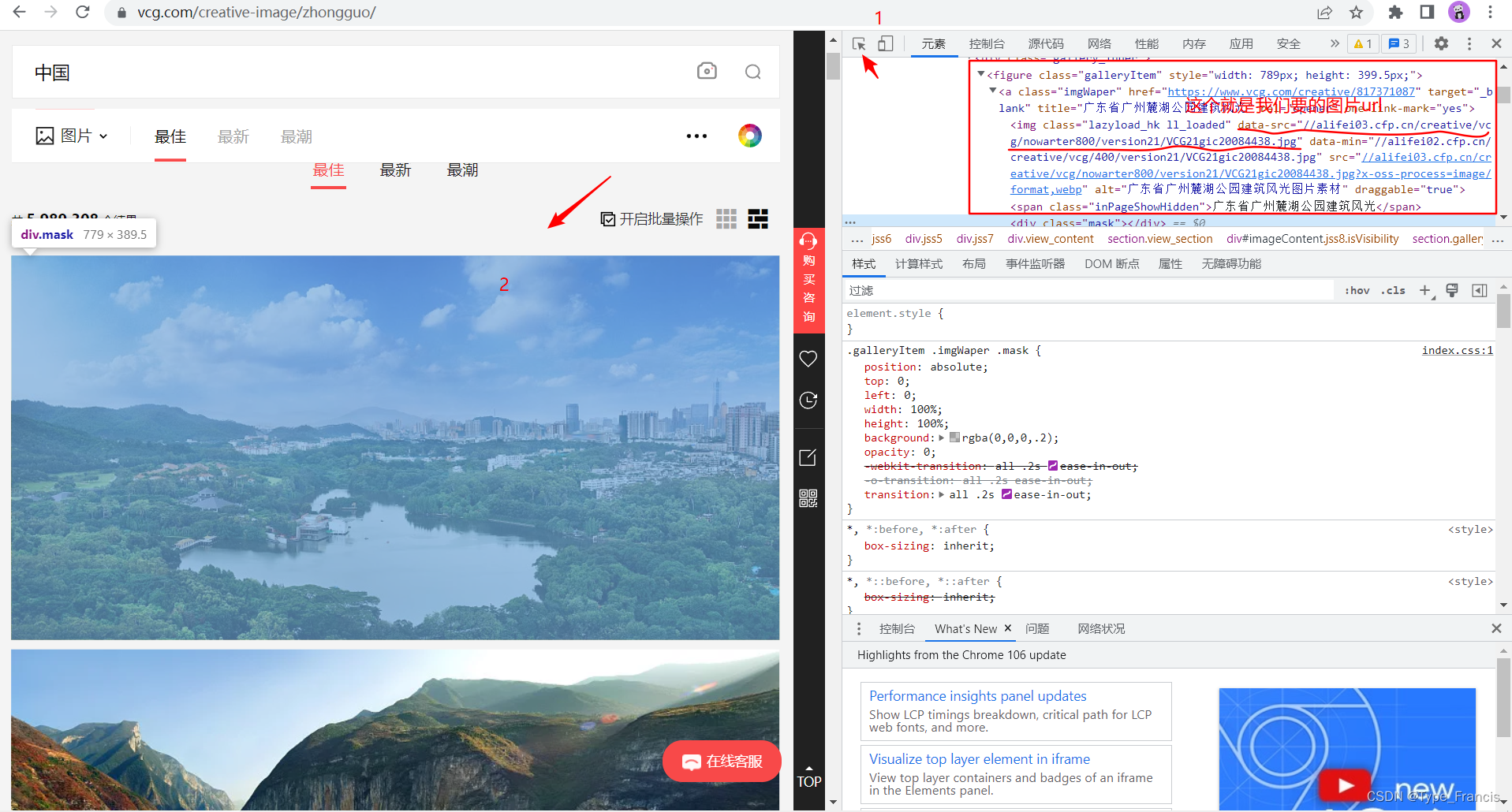
如果记得这样看起来不舒服,还有一个方法,回到进来网站后,右击鼠标的操作,点击检查功能,这样就很好的帮我们定位图片的位置,同样可以清晰看到图片格式长什么样子
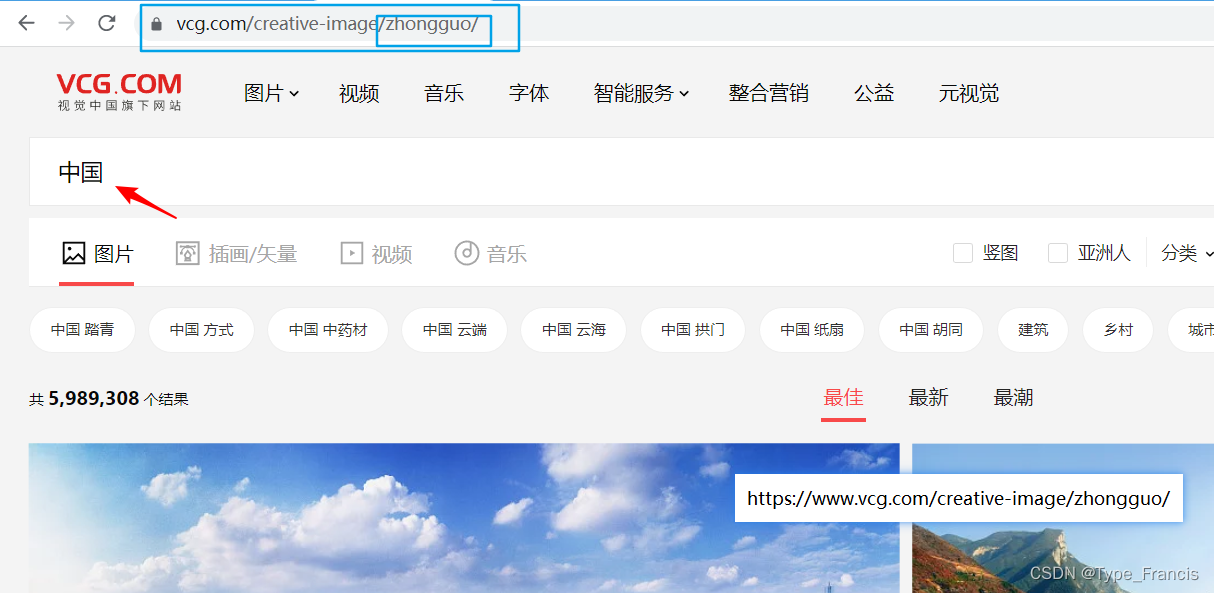
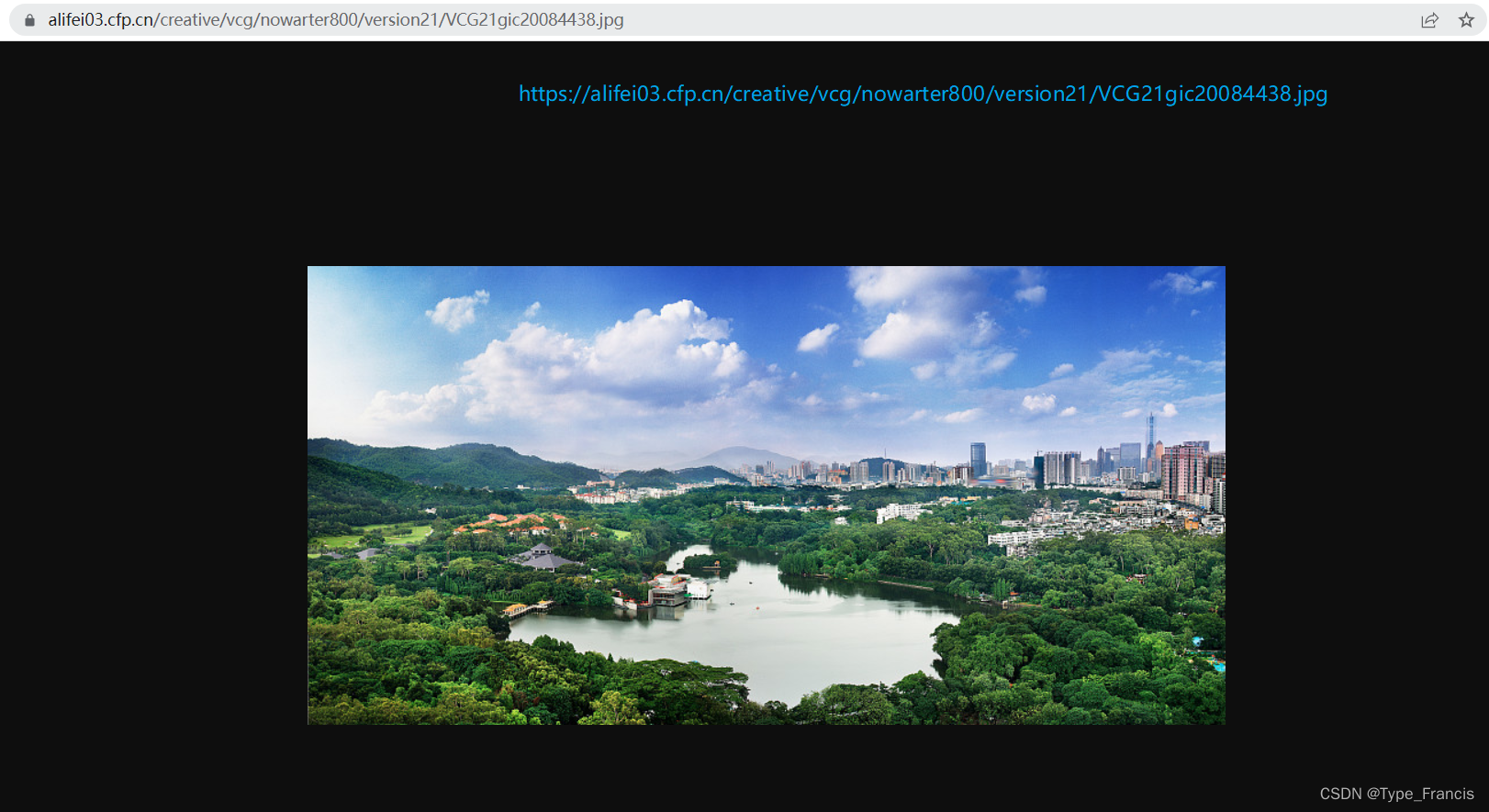
当我们知道图片url格式后,现在就进行对网页上数据解析,把我们想要的图片url提取出来,最重要一点是,要明白知道什么数据是我们想要的,什么数据是不想要的。 设置请求头headers是解决requests请求反爬的方法之一,相当于我们进去这个网页的服务器本身,假装自己本身在爬取数据。对反爬虫网页,可以设置一些headers信息,模拟成浏览器取访问网站 。 self.headers = { "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, \ like Gecko) Chrome/94.0.4606.61 Safari/537.36" } 网址格式page:表示页数 keyword_trans_pinyin:表示汉字转拼音 url="https://www.vcg.com/creative-image/{0}/?page={1}".format(keyword_trans_pinyin,str(page)) 为什么转成拼音?首先,我们先进去网站搜下图片,看它的网址格式是怎么样 很清楚看见,图片名称是通过我们输入的关键字转成拼音拼接的,然而,我们也希望程序也是跟浏览器一样,所以我这里就用Python的xpinyin库来实现汉字转拼音效果。 from xpinyin import Pinyin pinyin = Pinyin() res = pinyin.get_pinyin('中国','') print(res) # zhongguo 提取图片url使用tree.xpath提取data-src数据,返回是一个列表,这里就不再对一一详细讲了,想了解更多直接上网搜。 tree.xpath('//div[@id="root"]//div[@class="gallery_inner"]//figure/a/img/@data-src') 下载图片并保存到本地当我们已经拿到所有的图片url后,就会发现,图片url都没有https请求头 # 图片url //alifei03.cfp.cn/creative/vcg/nowarter800/version21/VCG21gic20084438.jpg没有请求头就无法下载图片,我就直接把https和图片url拼凑起来,返回一串新的图片url字符串通过输入到浏览器,访问有效。
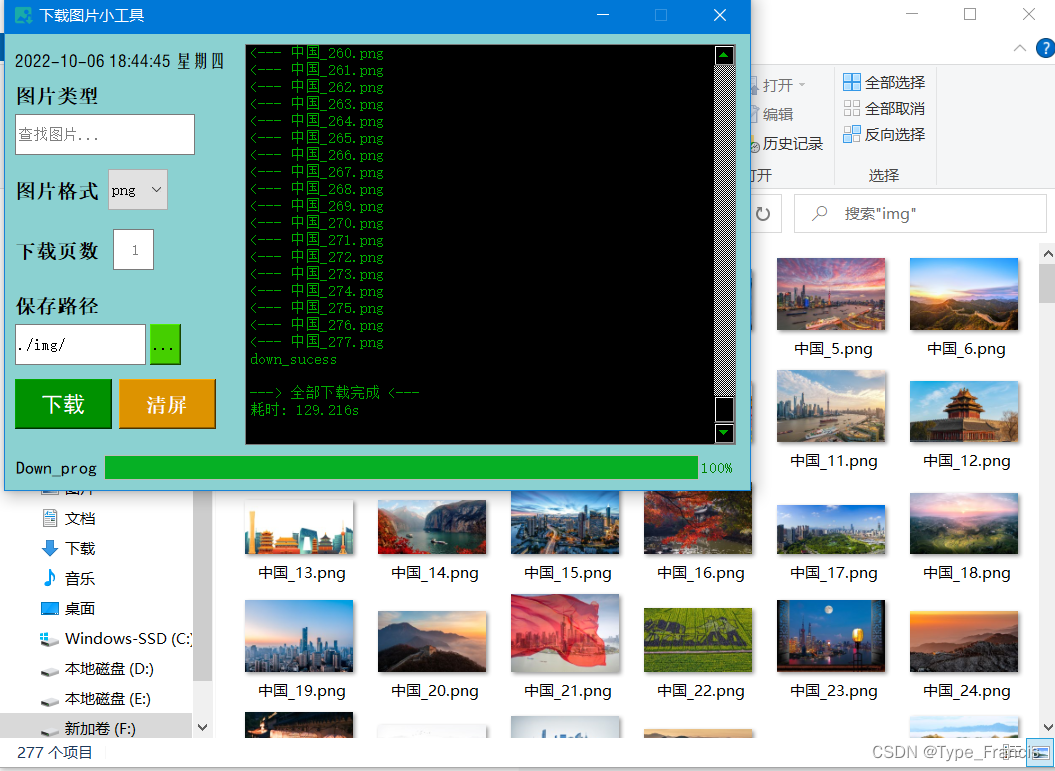
最后,使用urllib.request.urlretrieve方法把所有的图片保存到本地上 urllib.request.urlretrieve(url, filename=None, reporthook=None, data=None) 传输说明:url:外部或者本地url filename:指定了保存到本地的路径(如果未指定该参数,urllib会生成一个临时文件来保存数据); reporthook:是一个回调函数,当连接上服务器、以及相应的数据块传输完毕的时候会触发该回调。我们可以利用这个回调函数来显示当前的下载进度。 data:指post到服务器的数据。该方法返回一个包含两个元素的元组(filename,headers),filename表示保存到本地的路径,header表示服务器的响应头。 运行程序前提准备:电脑有安装python3.9+,支持Windows/Linux 依赖库:pip install PySide2 运行脚本:python ui_main.py 抓取图片的效果图 链接:https://pan.baidu.com/s/1_7kjwmNQGPe52wcfEAvWjQ 提取码:linv 今天就先到这里啦,如果对你有帮助的,赶紧收藏下来吧!觉得代码哪里有问题或者有建议的,都可以打在评论上,我会留意的,互相学习,互相探讨,你我皆黑马。 |

【本文地址】