| 眼底 Fundus、OCT 图竞赛分析 | 您所在的位置:网站首页 › 视网膜oct图像 › 眼底 Fundus、OCT 图竞赛分析 |
眼底 Fundus、OCT 图竞赛分析
|
眼底 Fundus、OCT 图竞赛分析
眼底 Fundus 图竞赛(8分类)算法设计ResNet简介双路ResNet2d网络的工作原理应用数据预处理训练和验证
代码分析
眼底 OCT 图(8分类)代码分析眼底图分类最新研究
MuReD 视网膜疾病 (20分类)糖尿病视网膜分级DRAC 三类病变分割、三级图像质量评估以及三级糖尿病视网膜病变分级Drishti-GS OCT 视网膜视神经头(ONH)分割任务OCT_ChestX-Ray OCT 眼底疾病分类RAVIR 眼底动脉和静脉的有效分割AROI 视网膜OCT图像的四层分割任务RETOUCH 视网膜 OCT 在黄斑水肿应用
RITE 视网膜血管树提取和分割FairSeg10k2024 眼底视盘(OD)和视杯区域分割
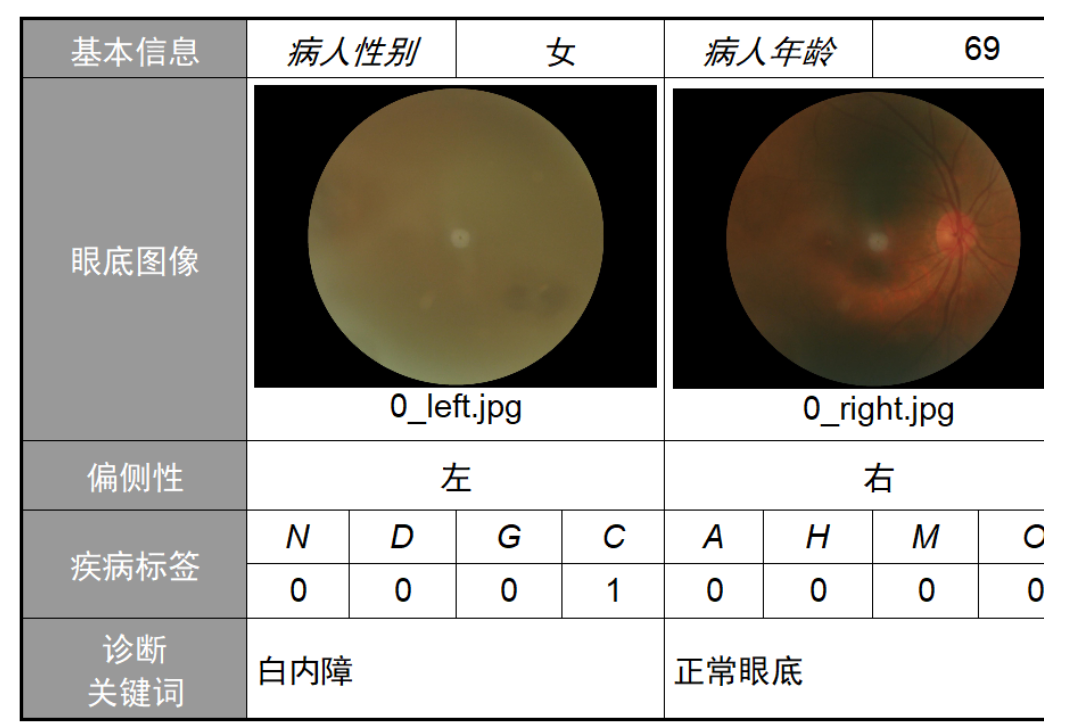
眼底 Fundus 图竞赛(8分类) 链接:https://odir2019.grand-challenge.org/ 代码:https://github.com/junqiangchen/PytorchDeepLearing 眼部疾病分类的目标是将患者分为八个类别: 正常(N)糖尿病(D)青光眼(G)白内障(C)AMD(A)高血压(H)近视(M)其他疾病/异常(O)每个类别,分类概率(值从0.0到1.0)表示患者被诊断为具有相应类别的可能性/风险。 ODIR2019数据集:包括5,000名患者的年龄,双眼的彩色眼底照片和医生的诊断关键词(ODIR-5K)。
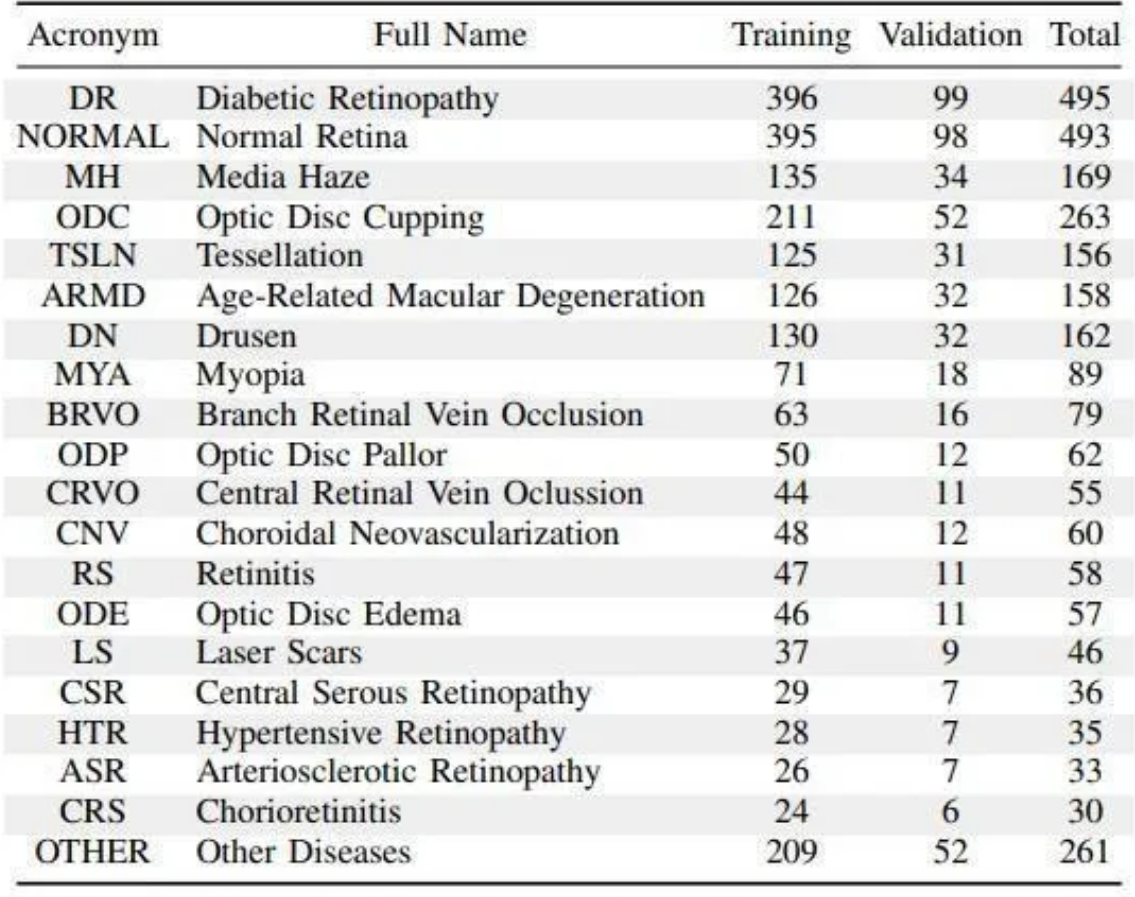
双路ResNet2d网络,或称双路径ResNet2d网络,是一种深度学习模型,特别设计用于处理成对的输入数据,如左右眼的图像。 这种网络架构在本质上利用了两个并行的ResNet(残差网络)架构,分别处理每个输入路径的数据。 通过这种方式,模型能够分别学习每个输入(在此例中为左眼和右眼图像)的特征表示,然后在网络的某个点将这些特征合并起来,以进行进一步的处理和最终的分类或回归任务。 ResNet简介ResNet(残差网络)是一种深度卷积神经网络(CNN),最初由微软研究院的研究人员在2015年提出。 ResNet的关键创新是引入了所谓的“残差块”,这些残差块允许信息通过网络的跨层连接直接传递,帮助解决了更深层网络中的梯度消失和梯度爆炸问题,使得网络可以通过增加更多的层来提高准确性,而不会降低训练效率。 双路ResNet2d网络的工作原理双路输入:模型有两个独立的输入通道(或路径),每个通道对应于一个ResNet网络。 在眼部疾病诊断的上下文中,一个通道处理左眼图像,另一个通道处理右眼图像。 特征提取:每个ResNet网络独立地从其输入图像中提取特征。这意味着网络能够捕获每只眼睛特有的视觉特征,这对于一些疾病的诊断来说可能是非常重要的,因为某些疾病可能只影响一个眼睛。 特征融合:从两个眼睛提取的特征在网络中的某个点被合并(通常是通过拼接或加权求和),以便可以对它们进行联合分析。 分类或回归:合并的特征然后被送入网络的剩余部分,通常包括几个全连接层,最终输出分类(如不同类型的眼疾)或回归(如疾病严重程度的估计)的预测。 应用双路ResNet2d网络在处理需要分析成对数据或关联数据的任务中特别有用,例如立体视觉、人脸识别中的比对任务,以及医学图像分析, 特别是在那些对称器官(如眼睛、耳朵、肺部等)的分析中。 通过这种方式,模型可以更有效地利用成对数据之间的相关性和差异性,从而提高整体的诊断准确性和分析效率。 数据预处理 import torch import torch.nn as nn # 导入PyTorch神经网络模块 from torchvision import models, transforms # 导入模型和数据预处理的transforms from torch.utils.data import DataLoader, Dataset # 导入数据加载器相关的类 from sklearn.model_selection import train_test_split # 导入数据集划分函数 import numpy as np # 导入NumPy库 from PIL import Image # 导入PIL库,用于图像处理 # 数据预处理:定义图像的预处理操作 # 对图像进行缩放固定到512x512大小 # 再采用均值为0,方差为1进行归一化 transform = transforms.Compose([ transforms.Resize((512, 512)), # 将图像大小调整为512x512 transforms.ToTensor(), # 将图像转换为PyTorch张量 transforms.Normalize(mean=[0.0, 0.0, 0.0], std=[1.0, 1.0, 1.0]) # 对图像进行归一化 ]) # 自定义数据集类 class EyeDataset(Dataset): def __init__(self, left_eye_paths, right_eye_paths, labels, transform=None): self.left_eye_paths = left_eye_paths # 左眼图像路径列表 self.right_eye_paths = right_eye_paths # 右眼图像路径列表 self.labels = labels # 图像标签(多标签二进制向量) self.transform = transform # 预处理操作 def __len__(self): return len(self.labels) # 返回数据集中的样本数 def __getitem__(self, index): # 根据索引加载左右眼图像并应用预处理 left_img = Image.open(self.left_eye_paths[index]).convert('RGB') # 加载左眼图像 right_img = Image.open(self.right_eye_paths[index]).convert('RGB') # 加载右眼图像 label = torch.tensor(self.labels[index], dtype=torch.float32) # 将标签转换为张量 if self.transform: left_img = self.transform(left_img) # 应用预处理到左眼图像 right_img = self.transform(right_img) # 应用预处理到右眼图像 return left_img, right_img, label # 返回处理后的图像和标签 # 模型定义 class DualResNet(nn.Module): def __init__(self): super(DualResNet, self).__init__() self.resnet = models.resnet50(pretrained=True) # 加载预训练的ResNet50模型 self.resnet.fc = nn.Linear(self.resnet.fc.in_features, 512) # 修改ResNet50的全连接层 self.classifier = nn.Linear(1024, 8) # 定义一个新的全连接层,用于输出8个类别的预测 def forward(self, left_input, right_input): # 前向传播函数 left_features = self.resnet(left_input) # 提取左眼图像的特征 right_features = self.resnet(right_input) # 提取右眼图像的特征 combined_features = torch.cat((left_features, right_features), dim=1) # 拼接左右眼的特征 output = self.classifier(combined_features) # 使用全连接层输出最终的预测 return output # 实例化模型 model = DualResNet() # 定义优化器,使用AdamW优化算法,学习率为0.0001 optimizer = torch.optim.AdamW(model.parameters(), lr=0.0001) # 定义损失函数,使用二值交叉熵损失,适用于多标签分类问题 criterion = nn.BCEWithLogitsLoss() 训练和验证 # 导入所需的库 import torch.optim as optim # 导入优化器库 from torch.utils.data import DataLoader # 导入数据加载器工具 import time # 导入时间库以计算训练时间 # 创建自定义数据集的实例,并加载训练集和验证集数据 train_dataset = EyeDataset(left_eye_paths=left_eye_paths_train, right_eye_paths=right_eye_paths_train, labels=labels_train, transform=transform) val_dataset = EyeDataset(left_eye_paths=left_eye_paths_val, right_eye_paths=right_eye_paths_val, labels=labels_val, transform=transform) # 使用DataLoader来批量加载数据,同时提供打乱数据的选项以增强训练过程 train_loader = DataLoader(train_dataset, batch_size=32, shuffle=True) # 训练数据加载器 val_loader = DataLoader(val_dataset, batch_size=32, shuffle=False) # 验证数据加载器 # 定义训练函数,该函数执行模型的一次训练周期 def train(model, train_loader, criterion, optimizer, device): model.train() # 将模型设置为训练模式 running_loss = 0.0 # 初始化累计损失 for batch_idx, (left_imgs, right_imgs, labels) in enumerate(train_loader): # 遍历数据批次 left_imgs, right_imgs, labels = left_imgs.to(device), right_imgs.to(device), labels.to(device) # 移动数据到指定设备 optimizer.zero_grad() # 清空之前的梯度 outputs = model(left_imgs, right_imgs) # 前向传播计算输出 loss = criterion(outputs, labels) # 计算损失 loss.backward() # 反向传播计算梯度 optimizer.step() # 更新模型参数 running_loss += loss.item() # 累加损失 return running_loss / len(train_loader) # 返回平均损失 # 定义验证函数,该函数评估模型在验证集上的性能 def validate(model, val_loader, criterion, device): model.eval() # 将模型设置为评估模式 running_loss = 0.0 # 初始化累计损失 with torch.no_grad(): # 不计算梯度,以加速计算 for batch_idx, (left_imgs, right_imgs, labels) in enumerate(val_loader): # 遍历验证数据批次 left_imgs, right_imgs, labels = left_imgs.to(device), right_imgs.to(device), labels.to(device) # 移动数据到指定设备 outputs = model(left_imgs, right_imgs) # 前向传播计算输出 loss = criterion(outputs, labels) # 计算损失 running_loss += loss.item() # 累加损失 return running_loss / len(val_loader) # 返回平均损失 # 设置计算设备 device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu") # 使用GPU如果可用,否则使用CPU model = model.to(device) # 将模型移动到指定设备 # 执行训练和验证过程 num_epochs = 10 # 设置训练周期数 for epoch in range(num_epochs): start_time = time.time() # 记录开始时间 train_loss = train(model, train_loader, criterion, optimizer, device) # 训练模型 val_loss = validate(model, val_loader, criterion, device) # 验证模型 end_time = time.time() # 记录结束时间 # 打印每轮的训练损失、验证损失和耗时 print(f"Epoch {epoch+1}/{num_epochs}, Train Loss: {train_loss:.4f}, Validation Loss: {val_loss:.4f}, Time: {end_time - start_time:.2f}s") 代码分析 眼底 OCT 图(8分类)Retinal OCT-C8 数据集包含了24000张二维的OCT图像。 数据集链接:https://www.kaggle.com/datasets/obulisainaren/retinal-oct-c8/data 共涉及8个类别: AMD (Age-related Macular Degeneration):年龄相关性黄斑变性,这是一种影响中央视力的眼病,常见于老年人。黄斑是眼睛中负责清晰中央视力的部分。AMD分为“干性”和“湿性”两种类型,其中湿性AMD进展更快,更严重。 CNV (Choroidal Neovascularization):脉络膜新生血管,这是湿性AMD的一个特征,指的是在视网膜下出现新血管的生长,这些新血管往往是异常的,容易渗漏,导致视力损失。 CSR (Central Serous Retinopathy):中央浆液性脉络膜视网膜病变,是一种视网膜疾病,特点是中央视网膜下有液体积聚,通常影响中央视力。这种情况可能自行解决,但有时需要治疗。 DME (Diabetic Macular Edema):糖尿病性黄斑水肿,这是一种由糖尿病引起的视网膜疾病,特征是视网膜中央区域(黄斑)的肿胀和流体积聚,导致视力下降。 MH (Macular Hole):黄斑孔,这是黄斑区域形成的一个小洞,可以导致中央视力严重下降。黄斑孔的形成可能与眼内牵拉力的异常有关。 Drusen:视网膜色素上皮下的小黄色沉积物,通常与年龄相关性黄斑变性(AMD)相关。Drusen的存在是评估AMD进展的一个指标。 DR (Diabetic Retinopathy):糖尿病视网膜病变,是糖尿病引起的一种视网膜疾病,随着病情进展,新生血管可能形成,导致视力严重下降。糖尿病视网膜病变是糖尿病最常见的并发症之一,也是成年人失明的主要原因。 Normal:正常眼底,没有发现上述疾病或其他异常的眼底OCT图像。 代码分析https://github.com/junqiangchen/PytorchDeepLearing 眼底图分类最新研究眼底OCT图像的公共数据获取及其分析算法:这篇论文讨论了国际上公开的免费眼底疾病OCT图像数据库及基于这些数据库的计算机辅助算法。阅读全文 多尺度特征融合网络的视网膜OCT图像分类:这项研究提出了一个基于深度学习的多尺度特征融合网络,用于OCT图像的分类。阅读全文 人工智能在眼底影像分析中的研究进展及应用现状:探讨了人工智能分析眼底图像的最新研究进展,包括基于OCT和眼底彩照相结合的多模态深度学习(DL)算法的研究发现。阅读全文 基于集成学习的计算机辅助诊断青光眼算法研究:通过设计基于专家知识的机器学习算法,以支持向量机和其他技术,增强了眼底照和OCT图像数据的分析能力。阅读全文 Octnet: A lightweight cnn for retinal disease classification from optical coherence tomography images: 该研究提出了一个轻量级的卷积神经网络(CNN)用于从OCT图像中分类视网膜疾病。阅读更多 - Computer Methods and Programs in Biomedicine, 2021. Classification of Fundus Images Based on Deep Learning for Detecting Eye Diseases: 探讨了基于深度学习的眼底图像分类方法在检测眼病方面的应用。阅读更多 - Computers, Materials & Continua, 2021. AOCT-NET: a convolutional network automated classification of multiclass retinal diseases using spectral-domain optical coherence tomography images: 这项工作展示了一种卷积网络,用于自动分类使用光谱域OCT图像的多类视网膜疾病。阅读更多 - Medical & Biological Engineering & Computing, 2020. Disease classification of macular optical coherence tomography scans using deep learning software: validation on independent, multicenter data: 此研究验证了使用深度学习软件对黄斑OCT扫描进行疾病分类的有效性。阅读更多 - Retina, 2020. Deep learning approach for classification of eye diseases based on color fundus images: 探讨了基于彩色眼底图像使用深度学习方法分类眼病的策略。阅读更多 - Optical Coherence Tomography and Fundus OCT, 2020. “机器学习在使用眼底和视网膜光学相干断层扫描图像检测青光眼中的表现:一项元分析”,作者为JH Wu等,发表于2022年。该研究对机器学习技术在使用眼底和OCT图像检测青光眼的有效性进行了元分析。在ScienceDirect上阅读更多。 “基于深度学习的视网膜疾病分类框架”,作者为A Choudhary等,发表于2023年。本文提出了一个基于深度学习的模型,用于将OCT扫描的视网膜图像分类为四类视网膜疾病。在MDPI上阅读更多。 “使用深度学习诊断视网膜疾病”,作者为AAEKF Elsharif和SS Abu-Naser,发表于2022年。这项研究聚焦于使用深度学习对疾病的OCT图像进行分类。在PhilPapers上阅读更多。 “使用深度学习对视网膜OCT图像进行分类”,作者为M Subramanian等,发表于2022年。该研究介绍了一个用于分类视网膜疾病的深度学习图像识别系统。在IEEE Xplore上阅读更多。 “用于视网膜眼底图像分类的深度神经网络和机器学习方法”,作者为R Thanki,发表于2023年。该文章探讨了使用深度神经网络和机器学习对视网膜眼底图像进行分类的方法。在ScienceDirect上阅读更多。 “眼底 OCT 图像的公共数据获取及其分析算法”: 这项研究探讨了如何获取公开的免费眼底疾病OCT图像数据库,并使用这些数据库来开发计算机辅助算法。研究主要涉及三类疾病,并讨论了84484张眼底OCT图像的应用,包括968张用于测试,83484张用于训练。文章还探讨了迁移学习在眼底OCT图像分析中的应用。阅读更多 - Laser & Optoelectronics Progress, 2023。 “人工智能在眼底影像分析中的研究进展及应用现状”: 本文综述了人工智能在眼底影像分析中的最新研究进展,特别是机器学习(ML)和深度学习(DL)在生成治疗后OCT预测图像以及眼底疾病的智能诊断中的应用。阅读更多。 “多层次可选择核卷积用于视网膜图像分类.”: 这项研究使用OCT视网膜眼底检测图像数据集进行分类研究,探讨了将机器学习应用于基于OCT图像的AMD和DME疾病的诊断和分析。阅读更多 - Journal of Chongqing University of Posts & Telecommunications, 2022。 眼底OCT图像的公共数据获取及其分析算法: 概述了国际上公开的免费眼底疾病OCT图像数据库,涵盖了3种疾病类型。数据集包括84484张眼底OCT图像,其中968张用于测试,其余用于训练。研究还讨论了迁移学习在眼底OCT图像分析中的应用情况。阅读更多 (Laser & Optoelectronics Progress, 2023)人工智能在眼底影像分析中的研究进展及应用现状: 综述了人工智能,尤其是机器学习(ML)和深度学习(DL)在眼底OCT图像分析中的最新研究进展。讨论了AI在眼底图像诊断中的智能性和全面性诊断的应用。阅读更多多层次可选择核卷积用于视网膜图像分类: 探讨了利用OCT视网膜眼底检测图像数据集进行分类研究。研究表明,将机器学习应用于OCT图像的AMD和DME疾病的诊断和分析非常有效。阅读更多 (Journal of Chongqing University of Posts & Telecommunications, 2022)相关论文,都记录在这:医学图像:一眼诊全身 MuReD 视网膜疾病 (20分类)数据:https://data.mendeley.com/datasets/pc4mb3h8hz/1 MuReD 这个数据集通过整合和优化几个公开可用的数据集来实现其目标,确保了数据在质量、多样性和数量上的平衡。 数据集来源: MuReD 数据集由三个较小的数据集合并而成,分别是: ARIA: 包含143张图像,有三种疾病标签。STARE: 包含388张图像,覆盖21种疾病条件。RFMiD 训练集: 包含1920张图像,涉及46种不同的病理。选择和合并标准: 由于ARIA和STARE数据集的图像数量较少,决定只使用RFMiD数据集的训练部分来避免在合成的MuReD数据集中引入过多的偏差。 最终,MuReD数据集包括2451个样本和52个疾病标签,以及一个标记为“正常”的类别用于健康的眼底图像,还有一个“其他”类别用于标注罕见疾病。 数据集特点: 样本数量: 最终的MuReD数据集包含2208张图像,有20个不同的标签。图像质量和多样性: 数据集中的图像质量和分辨率各不相同,但都经过仔细选择,确保了最低的质量标准。后处理步骤: 对数据集应用了一系列后处理步骤,旨在提高图像质量,增加病理的多样性,并确保每个标签都有足够数量的样本。这有助于减少数据集中存在的类别不平衡问题。
数据:https://www.kaggle.com/datasets/sovitrath/diabetic-retinopathy-224x224-2019-data 包含相应图像的目录: 0 - No_DR(正常)1 - Mild(轻微)2 - Moderate(中等)3 - Severe(严重)4 - Proliferate_DR(扩散)将一个多分类任务拆解成一个二分类任务和一个多分类任务,其中二分类任务是用来判断有无视网膜病变,多分类任务是用来判断有视网膜病变的不同程度。 将一个多分类任务拆分成一个二分类任务和一个多分类任务的方法通常用于处理具有层次结构的问题,或是在问题的一部分存在明显的类别不平衡时。 这种方法可以提高模型的总体性能,特别是在初步需要识别是否存在特定条件(例如视网膜病变)的场景中 假设我们有一个关于糖尿病视网膜病变(糖网)的图像数据集,我们的目标是诊断糖尿病视网膜病变的存在以及病变的严重程度。 糖网病变的严重程度分为五个级别:无糖网(0)、轻微(1)、中度(2)、重度(3)、和增殖性糖网(4)。 为什么要拆分任务 类别不平衡:在实际数据集中,可能会发现无糖网(0级)的图像远多于其他类别,导致类别严重不平衡。直接进行多分类可能会导致模型偏向于多数类,从而忽略掉少数类。不同的关注点:诊断过程中,医生通常首先判断是否存在糖网病变,如果存在,再进一步评估病变的严重程度。这两个问题的关注点不同,一个是判断是否有病,另一个是病的程度,因此分开处理可能更符合实际需求。如何拆分任务 有无糖网病变二分类任务: 任务目标:判断图像中是否有糖网病变(有病变 vs 无病变)。数据处理:所有非0标签(轻微、中度、重度、增殖性)的图像标签修改为1,表示有糖网病变;0标签保持不变,表示无糖网病变。糖网病变程度多分类任务: 任务目标:在确定图像中有糖网病变的前提下,进一步判断病变的严重程度(轻微、中度、重度、增殖性)。数据处理:只使用标签非0的数据,即只有在确认有病变的情况下,才进行这一步的训练和预测。通过这种拆分,模型可以更专注于各自的任务,先判断是否存在疾病,再确定疾病的程度,这不仅提高了模型的鲁棒性,还使得模型的解释性更强,更接近医生的诊断流程。 实测,拆分后准确性提高 1 %。 那能不能继续拆解,确定有病后,再拆解为五个二分类任务。 轻微病变二分类任务: 判断图像是否为轻微糖尿病视网膜病变。中度病变二分类任务: 判断图像是否为中度糖尿病视网膜病变。重度病变二分类任务: 判断图像是否为重度糖尿病视网膜病变。增殖性病变二分类任务: 判断图像是否为增殖性糖尿病视网膜病变。无病变(作为对照组)二分类任务: 这个任务略有不同,其目标是判断图像是否无任何糖尿病视网膜病变,即使已经确定存在病变。这可以作为一种对照,确保模型能够准确分辨出特定程度的病变而不是简单地将所有有病变的图像归为同一类。实施注意事项 数据处理:对于每个二分类任务,需要从整体数据集中提取对应的正负样本。 正样本为目标病变程度的图像,负样本为其他所有病变程度的图像。 数据不平衡处理:特别注意到,在这种细化的拆分中,某些程度的病变图像数量可能非常少,导致数据不平衡问题更加突出。 可以通过数据增强、过采样或使用特定的损失函数来缓解这一问题。 模型训练:每个任务可以使用相同或不同的模型架构,如ResNet,但可能需要针对每个任务调整模型的参数和训练策略。 综合判断:在所有二分类任务完成后,需要有一个策略来综合这些二分类任务的输出,以得出最终的病变程度判断。 这可能涉及到模型输出的概率阈值设置,或是某种形式的逻辑判断规则。 通过这种方式,每个病变程度都被单独关注,有助于提升模型在识别特定病变程度上的性能。 然而,这种方法也可能增加模型训练和维护的复杂度,需要在实际应用中权衡利弊。 DRAC 三类病变分割、三级图像质量评估以及三级糖尿病视网膜病变分级三级图像质量评估:地基检查 三类病变分割:建筑框架搭建 三级糖尿病视网膜病变分级:内部装修和定级 数据:https://github.com/junqiangchen/PytorchDeepLearing/tree/main/dataprocess Drishti-GS OCT 视网膜视神经头(ONH)分割任务数据:https://data.mendeley.com/datasets/rscbjbr9sj/3 从视网膜图像中分割出视盘(OD)和视杯区域,进而计算杯盘比(CDR),为青光眼的早期诊断和进展监测提供了一种自动化、高效的工具。 DRISHTI-GS2014数据集是一个专门为视网膜图像分析和青光眼研究设计的集合,包含101张高分辨率的彩色眼底图像。 这些图像分为50张训练图像和51张测试图像,均在印度马杜赖阿拉文眼科医院以受试者同意的方式收集。数据集旨在支持视网膜视神经头(ONH)的自动分割和青光眼的诊断研究。 数据集特点: 受试者:包括了40至80岁的青光眼患者以及未患有青光眼的正常人群,男女比例大致相等。成像协议:所有图像均在散瞳后拍摄,以视盘(OD)为中心,视场角度为30度,图像分辨率为2896×1944像素,采用PNG格式存储,未经压缩。标注:图像由具有3至20年经验的四位青光眼专家进行标注,旨在捕获专家之间标记的差异。专家标注考虑了视盘(OD)和视杯区域,以支持青光眼相关的杯盘比(CDR)计算和分析。数据处理:为了便于分析,从原始图像中裁剪出眼底区域,去除了周围的非眼底黑色区域,最终得到的图像尺寸约为2047×1760像素。质量控制:具有对比度差或视盘区域定位不准的低质量图像被排除。数据集应用: DRISHTI-GS2014数据集提供了一个有价值的资源,用于开发和测试视网膜图像处理算法,特别是针对青光眼诊断的自动化工具。 该数据集不仅有助于推动眼科人工智能的发展,还可能提高临床环境中的诊断准确性和效率。通过自动分割视盘和视杯区域,研究人员和开发者可以更有效地评估青光眼的指示参数,如杯盘比(CDR),进而诊断和监测青光眼的进展。 OCT_ChestX-Ray OCT 眼底疾病分类数据:https://data.mendeley.com/datasets/rscbjbr9sj/3 OCT 2017 数据集包含 84484 张视网膜光学相干断层扫描(OCT)图像,所有图像均标记为疾病类型-患者ID-该患者的图像编号。 OCT分类中的CNV、DME、DRUSEN和NORMAL是使用光学相干断层扫描(OCT)技术诊断的几种典型的视网膜疾病和状态。 CNV(脉络膜新生血管) 全称:Choroidal Neovascularization描述:这是与年龄相关的黄斑变性(AMD)的晚期形式之一,发生在脉络膜(眼睛后部的血管层)中新生血管生长异常,这些新生血管可能泄漏液体和血液,导致视网膜损伤和视力下降。DME(糖尿病性黄斑水肿) 全称:Diabetic Macular Edema描述:这是糖尿病视网膜病变(DR)的一种形式,由于血糖控制不良导致视网膜血管受损,血管泄漏液体积聚在黄斑区(视网膜中心,负责清晰视力的区域),引起黄斑区肿胀和视力下降。DRUSEN 描述:Drusen是黄斑区的小沉积物,常见于年龄相关的黄斑变性(AMD)。它们是代谢废物的堆积,表现为OCT图像上的小白点。虽然一些Drusen可能不会引起视力问题,但大量的或者较大的Drusen是AMD发展的一个风险因素。NORMAL(正常)。 RAVIR 眼底动脉和静脉的有效分割数据:https://drive.google.com/file/d/1jCvIBu35pBP3uGKvdOQpQ0cXRhViITPX/view 眼底动脉和静脉的有效分割,这对于视网膜脉管系统疾病的诊断和监测至关重要。 如糖尿病视网膜病变,高血压性视网膜病变,视网膜静脉阻塞,视网膜动脉阻塞,年龄相关性黄斑变性,前列腺增生,系统性疾病的早期标志(自身免疫疾病、血液病、心血管疾病等)。 AROI 视网膜OCT图像的四层分割任务数据:https://github.com/junqiangchen/PytorchDeepLearing/tree/main/dataprocess 视网膜OCT图像的四层分割任务,特指在OCT眼底图像中分割以下四个关键的解剖边界或层次: 内界膜 (ILM - Inner Limiting Membrane):视网膜的最内层,直接接触玻璃体。 在OCT图像中,这是最内侧的明亮线,代表视网膜最表面的边界。 内丛状层和内核层之间的边界 (IPL/INL - Inner Plexiform Layer/Inner Nuclear Layer):这一边界分隔了内核层(由神经细胞的细胞核组成)和内丛状层(由神经细胞的突触连接组成)。 这两层在OCT图像中不总是容易区分,因此它们的共同边界被用作一个重要的解剖标记。 视网膜色素上皮 (RPE - Retinal Pigment Epithelium):位于视网膜神经组织层和脉络膜之间的一层细胞,对视网膜健康至关重要。 在OCT图像中,RPE作为一个较暗的带状结构出现,其上方是感光细胞层。 布鲁赫膜 (BM - Bruch’s Membrane):位于视网膜色素上皮细胞层和脉络膜之间的薄膜。 在OCT图像中,布鲁赫膜通常显示为RPE下方的一个细小且较亮的线。 这些层的准确分割对于评估视网膜疾病的影响和进行准确的疾病诊断至关重要。 特别是在新生血管性年龄相关性黄斑变性(nAMD)等病症中,这些层次的变化可以指示病理变化的存在和进展。 RETOUCH 视网膜 OCT 在黄斑水肿应用数据:https://github.com/junqiangchen/PytorchDeepLearing/tree/main/dataprocess 目的:黄斑水肿是一种常见眼病,会导致视网膜中央肿胀,影响视力。RETOUCH2017项目旨在通过自动化技术从OCT图像中分割出三种不同类型的积液,这对于黄斑水肿的诊断和治疗监测至关重要。积液类型:视网膜内液(IRF)、视网膜下液(SRF)和色素上皮脱离(PED)。数据集和数据获取: 设备:来自三个不同制造商的设备被用于获取OCT图像,包括Cirrus(Zeiss Meditec)、Spectralis(海德堡工程公司)和Topcon(T-1000和T-2000)。数据集大小:总共112个OCT卷,70个用于训练,42个用于测试。手动注释:图像被两个医疗中心的专家进行了手动标注,用于后续的自动化处理和学习。图像处理和模型训练: 图像预处理:包括调整图像大小和归一化处理,以便于模型处理。数据增强:对训练数据应用数据增强技术,比如旋转和平移,以提高模型的泛化能力。模型:使用基于VNet的3D网络进行训练,目标是自动识别和分割上述三种积液。优化和评价:使用AdamW优化器,损失函数为多分类Dice损失和交叉熵损失。模型性能通过Dice指数(DI)和绝对体积差(AVD)评估。 RITE 视网膜血管树提取和分割数据:https://uiowa.qualtrics.com/jfe/form/SV_a3mc5H4SG2B3e2p?Q_JFE=qdg 视网膜血管树的提取和分割不仅可以提供有关血管本身的信息,还可以反映出背后可能存在的各种眼科疾病。 糖尿病视网膜病变(Diabetic Retinopathy, DR)这是糖尿病最常见的并发症之一,随着病情的进展,会导致视网膜血管受损、泄漏或堵塞。在早期阶段,对视网膜血管的精确分析可以帮助识别微血管瘤或视网膜出血,及时进行治疗。 高血压视网膜病变(Hypertensive Retinopathy)长期的高血压可以导致视网膜血管变窄、硬化,甚至出血。通过观察视网膜血管的变化,医生可以评估高血压对眼底的影响程度,及时调整治疗方案。 视网膜静脉阻塞(Retinal Vein Occlusion, RVO)这种情况发生时,视网膜的静脉因为某种原因被阻塞,导致血液无法正常流出视网膜,可能引起视网膜肿胀和出血。通过分析视网膜血管,尤其是静脉的状态,可以帮助确定阻塞的位置和严重性。 年龄相关性黄斑变性(Age-related Macular Degeneration, AMD)AMD是老年人视力丧失的主要原因之一,特别是在发达国家。AMD的早期诊断依赖于对视网膜中心区域,尤其是血管状态的观察。血管新生是AMD晚期的一个标志,通过分析血管状态可以帮助识别此病变。 前列腺增生(Proliferative Retinopathies)这类疾病包括任何导致视网膜血管增生的情况,新生血管往往比正常血管更脆弱、容易泄漏和出血。准确的血管分割可以帮助早期发现这些新生血管。 FairSeg10k2024 眼底视盘(OD)和视杯区域分割数据:https://uiowa.qualtrics.com/jfe/form/SV_a3mc5H4SG2B3e2p?Q_JFE=qdg 目标是实现对眼底视盘(OD)和视杯区域的准确分割,这对于青光眼的诊断和治疗监测至关重要。 子解法1:图像预处理 操作:将图像缩放到固定大小1024x1024,并采用均值为0,方差为1的方式进行归一化处理。原因:统一图像大小有助于网络处理不同的输入图像,而归一化则能够减少图像间亮度和对比度的差异,为模型训练提供更稳定的输入。子解法2:数据集划分 操作:将数据分成训练集和验证集。原因:这种划分确保模型能够在独立的数据上进行训练和验证,有助于评估模型的泛化能力和防止过拟合。子解法3:VNet2d网络训练 网络选择:选择VNet2d网络结构进行训练。原因:VNet网络特别适用于体积数据和医学图像的分割任务。在二维图像分割中,VNet2d能够有效处理视网膜图像,并准确识别OD和视杯区域。子解法4:优化器和损失函数 选择:使用AdamW优化器和二分类的dice和交叉熵损失函数。原因:AdamW优化器有助于模型更快地收敛,而Dice损失和交叉熵损失函数的结合既可以提高分割边界的精确度,也能处理类别不平衡问题,这对于OD和视杯区域的精确分割至关重要。实施细节 图像预处理:对所有图像执行归一化和缩放操作,以确保输入的一致性。模型训练:在训练集上训练模型,通过调整超参数优化模型性能。模型验证:使用独立的验证集评估模型,以确保其泛化能力和准确性。例如,在处理图像预处理阶段,采用归一化处理的原因是因为这种方法可以标准化图像的亮度和对比度,降低模型训练的难度,使得模型能够更专注于学习区分OD和视杯区域的特征,而不是被图像的亮度变化所干扰。 通过这种方法,可以有效地从眼底图像中分割出视盘和视杯区域,为青光眼的诊断提供重要的量化指标,如杯盘比(CDR)。 |
【本文地址】